
计算机网络(自顶向下方法) 第7版 James F.Kurose等
本笔记主要内容是b站网课中科大郑烇、杨坚全套《计算机网络(自顶向下方法 第7版,James F.Kurose,Keith W.Ross)》课程的同步学习过程, 精简了闲聊内容, 辅以课程PPT, 教材原文, 个人理解, 学习通课后作业, GPT解释等多方面扩展
网课整体讲的节奏比较慢, 建议1.5倍速听, 中间个别地方比较啰嗦, 看PPT懂了的地方可以快进
课程主要内容介绍
- 计算机网络和互联网(重要)
- 应用层
- 传输层
- 网络层: 数据平面
- 网络层: 控制平面
- 数据链路层和局域网
- 网络安全
- 无线和移动网络
- 多媒体网络
- 网络管理
Chap1. 计算机网络概述
目标
- 了解基本术语和概念
- 掌握网络基本原理
1.1 什么是Internet
从具体构成的角度
节点:
- 主机及其上运行的应用程序
- 路由器, 交换机等网络交换设备
圆形表示网络核心系统: 交换机, 路由器
方形表示边缘系统: PC, 服务器, 手机, …
连接这两部分的边叫做接入系统
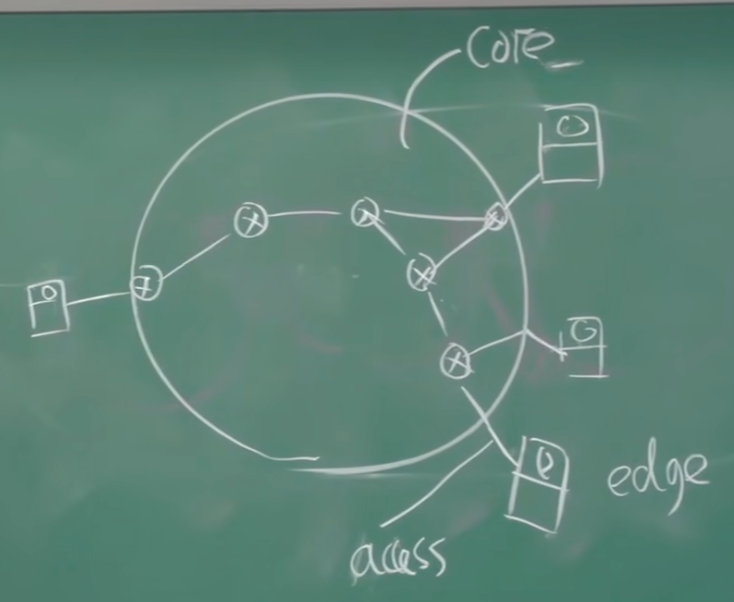
边: 通讯链路
-
接入网链路: 主机到互联网
-
主干链路: 路由器间的链路
协议:对等层实体在通信过程中应该遵守的规则的集合, 协议规定了:
- 语法
- 语义
- 时序
- 动作
互联网是以ICP/IP为主的一簇协议, 互联网是网络的网络
- 结构松散, ISP互联
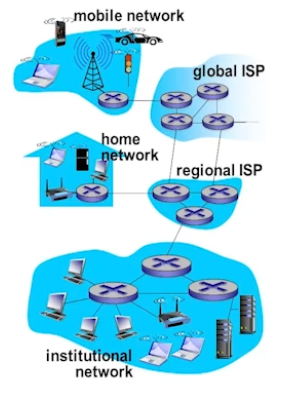
互联网有多种节点(端系统): PC, 服务器, 手机, 路由器, 智能家具…
多种通讯链路: 光线, 同轴电缆, 无线电, 卫星…
从服务的角度
互联网是 分布式的应用进程(Web, VoIP, Email…)和为分布式引用进程提供服务的基础设施
- 分布式应用是网络存在的理由
- 基础设施向应用进程提供通信服务
- 面向链接的服务: TCP/IP
- 无链接的服务: UDP
1.2 网络边缘
分布式应用程序运行在网络边缘
边缘通过接入连接到网络核心, 核心的作用是数据交换, 负责任意两个边缘的通信
网络应用以下的所有东西都是基础设施, 包括端系统, 接入, 路由器, 交换机等等
- 客户/服务器模式
- 客户端向服务器请求服务, 服务器提供
- 比如Web浏览器, Email客户端/服务器
- 对等模式
- 很少(甚至没有)专用服务器
- 比如Gnutella, KaZaA
1.3 网络核心
网络核心是路由器的网状网络
两种方式
- 电路交换(线路交换): 每个呼叫预留一条专有线路, 比如电话网
- 分组交换:
- 将要传送的数据分成一个个单位: 组
- 将分组从一个路由器传到相邻路由器(跳, hop), 一段段最终从源传到目标端
- 每段: 链路最大传输能力(带宽)
电路交换(线路交换)
端到端的资源被分配给从源到目标的呼叫(call)
- 通常被传统电话网络采用
- 独占资源, 不共享, 保证了性能
- 如果呼叫没有数据发送, 则被分配到资源被浪费
- 交换节点之间链路较粗, 带宽较大
- 将网络资源分成片(pieces), 为呼叫分配片
- 比如频分, 时分, 波分
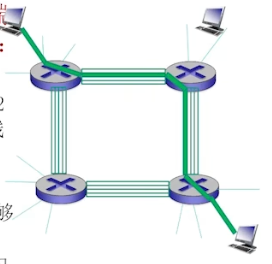
电路交换不适合计算机之间的通信
- 连接建立时间长
- 计算机通信有突发性, 造成资源浪费
- 可靠性不高?
- 核心节点损毁导致全部通信失效
分组交换
以分组(packet)为单位存储-转发方式
-
通讯资源不细分为片, 使用全部带宽
-
数据分为packet, 一个组被传输到下一个链路之前, 必须全部到达路由器
-
一次使用一段链路, 其他链路可以共享, 按需使用
-
延迟比电路交换更大, 换取了共享性
如果到达路由器的速率>路由器传出的速率:
- 分组会排队等待传输
- 超出路由器缓存的会被抛弃
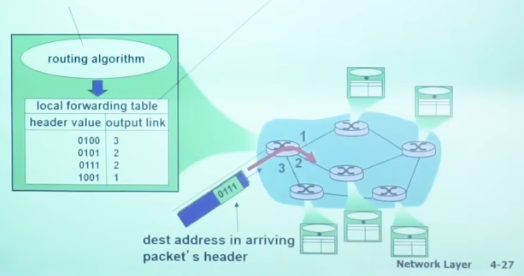
路由: 决定分组采用的源到目标的路径, 算出路由表
转发: 查路由表将分组从路由器的输入链路转移到输出链路
分组交换事实上是统计多路复用, 本质上还是划分时间片, 但是划分方法是动态的, 是特殊的时分
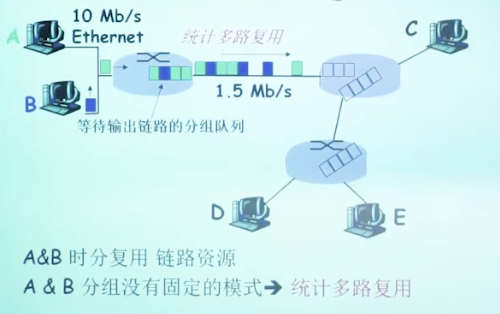
多媒体应用常常需要保证带宽, 需要分组交换表现出线路交换的特性来
数据报方式
-
每个分组相互独立
-
分组内包含目标完整地址
-
没有握手
-
交换节点之间不维护链接状态
-
类似于寄信
-
传送给同一个目标的分组可能走不同的路(路由表是动态的)
虚电路方式
- 有握手, 建立虚拟线路
- 建立虚电路后, 每个交换节点存储对应的表项(虚电路号-Next)
- 分组内包含虚电路号, 不标识目标主机完整地址
分组交换-虚电路 VS 电路交换
二者虽然有相似性, 但是本质上是不同的技术
| 特性 | 电路交换 | 虚电路方式 |
|---|---|---|
| 连接类型 | 面向物理连接 | 面向逻辑连接 |
| 资源分配 | 独占物理资源 | 动态共享资源 |
| 传输方式 | 连续比特流 | 按分组传输 |
| 建立延迟 | 较高,需要建立物理电路 | 较低,仅需建立逻辑连接 |
| 传输效率 | 较低,可能存在资源浪费 | 较高,资源动态利用 |
| 容错性 | 较差,故障需重建连接 | 较高,可动态调整路径 |
1.4 接入网, 物理媒体
前面介绍了网络边缘, 网络核心, 这里讨论如何将边缘接入网络
住宅接入
- 电话公司: 用电话线接入, 调制解调器, 另一头是城控交换机
- 有线电视公司: 改造同轴电缆, 单向改双向
- FDM: 不同频段传输不同数据
- 电力公司: 电线上网
企业接入
- 交换机级联
物理媒体: 导引性媒体(有实体的, 双绞线, 同轴电缆), 非导引性媒体(没实体的, 无线链路)
1.5 Internet/ISP结构
端系统通过接入ISP访问互联网
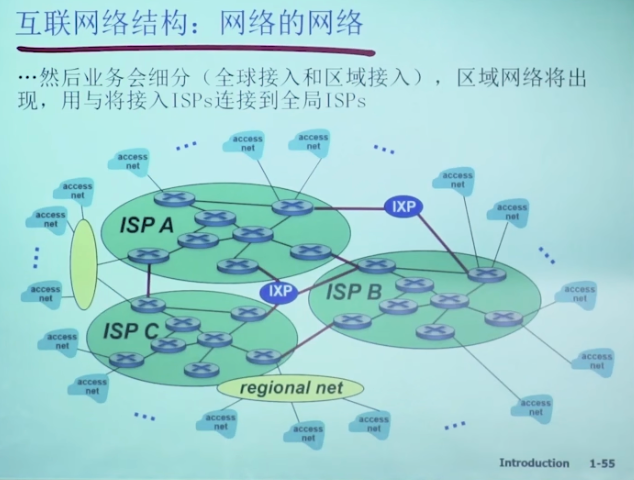
- ISP: 提供互联网服务, 比如移动, 中国教育网
- ICP: 提供内容, 比如百度, 谷歌
- 有的ICP不满ISP的服务, 会自己部署数据中心和线缆
- IXP: 在ISP之间交换流量, 免于从骨干网络绕行
Internet结构: 网络的网络
松散的层次模型
Tier 1 ISP, 如UUNet, BBN/Genuity, Sprint, AT&T
- 国家/国际覆盖的骨干网络, 速率极高
- 与其他第一层ISP直接相连, 免费对等交换流量
- 为大量二层ISP和大型公司, 政府机构提供接入
下层网络通过POP接入上层网络
Tier 2 ISP
-
通常是区域性ISP, 通过接入Tier 1 ISP访问全球互联网
-
向Tier 1支付费用, 有一定上游成本
-
二层ISP之间也通过IXP互联
-
为Tier 3 ISP, 企业, 机构等提供接入
Tier 3 ISP: local ISP
-
通常只覆盖一个城市, 或者一个小区域
-
直接向家庭, 小型企业, 本地机构提供接入
-
通常没有对等关系, 完全依赖上游
IXP: ISP之间的流量交换
- 主要用于Tier 2, 也可能涉及1或者3
- 为Tier 2 ISP建立公共对等关系, 帮助绕过昂贵的Tier 1上游带宽
- 除了ISP, IXP还为CDN, 企业网络, 云服务提供服务
1.6 性能: 丢包, 延迟, 吞吐量
分组丢失和延时是怎样发生的
- 路由器排队延迟
- 进入排队, 造成延迟
- 队伍已满, 直接丢弃
- 物理链路上的传播延迟
- 光速
- 路由器的处理延迟
- 路由器解析分组内容, 查表, 确定路由方向
- 路由器的传输延迟
- $$T=\frac{L}{R}$$
- L是一个分组的大小, R是路由器带宽
- 代表一个分组缓存下来的延迟
流量强度
$$
I = \frac{La}{R}
$$
其中
- $$L$$是一个分组的大小, bits
- $$R$$是链路带宽, bps
- $$a$$是分组到达队列的平均速率(个数)
$$I$$趋近于$$0$$, 平均排队延时很小
$$I$$趋近于$$1$$, 平均排队延时很大
$$I \gt 1$$, 比特到达队列的数据超过了输出速率, 排队延时无穷大, 在设计系统时, 应避免
TraceRoute
用来测试多跳之间每一跳的延时
TTL: Time to Live, IP协议中的数字字段, 表示最大存活时间, 通常以跳计
TraceRoute会先发送TTL=1的数据包, 数据包达到第一跳路由器时, TTL=0被丢弃, 并返回一个ICMP超时消息, 消息中包含第一条路由器的IP地址
TraceRoute发送TTL=2的数据包, 探测第二跳服务器, 以此类推
TraceRoute通常使用UDP数据包
吞吐量
在源和目标之间传输的速率(数据量/单位时间)
- 瞬间吞吐量
- 平均吞吐量
1.7 协议层次, 服务模型
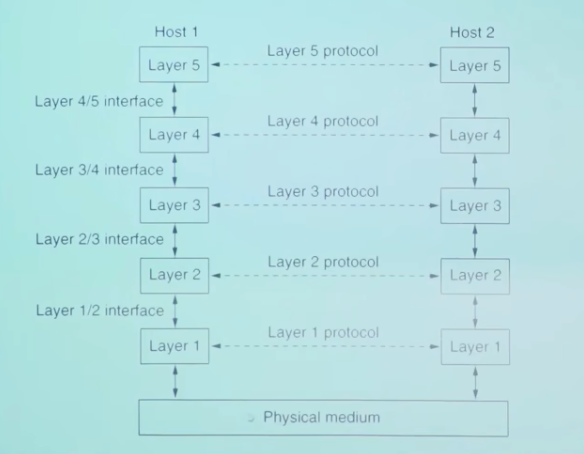
网络是迄今为止人类创造的最复杂的系统, 为了处理复杂的功能, 需要分层
每一层都通过接口和下一层交换PDU, 以使用下一层提供的服务, 通过本层的处理后, 向上层提供自己的服务
- 服务: 某一层可以向上一层提供的功能的集合
- 服务访问点: SAP(Service Access Point)
- 一个层用以区分不同服务用户的点
- 例如传输层的SAP是端口
- 原语: primitive, 上层使用下层服务的形式
- 一个层会提供多种服务, 上层使用的具体的服务, 穿过层间接口的位置上原语
- socket api的一系列函数是原语
- 协议: 对等层实体在交互过程中需要遵守的规则的集合
两种主要类型的服务
- 面向连接的服务
- 两个通讯的实体会建立某种连接
- 先握手, 再通讯, 最后拆除连接
- 非零星的, 大数据块, 需要可靠
- 通常是保序的, 但也有例外
- 无连接的服务
- 不建立连接, 不预留资源, 不需要双方活跃
- 类似于寄信, 直接通讯
- 小块的零星数据
服务和协议的关系
- 本层协议要靠下层提供的服务来实现
- 本层实体通过协议为上层提供本层的服务
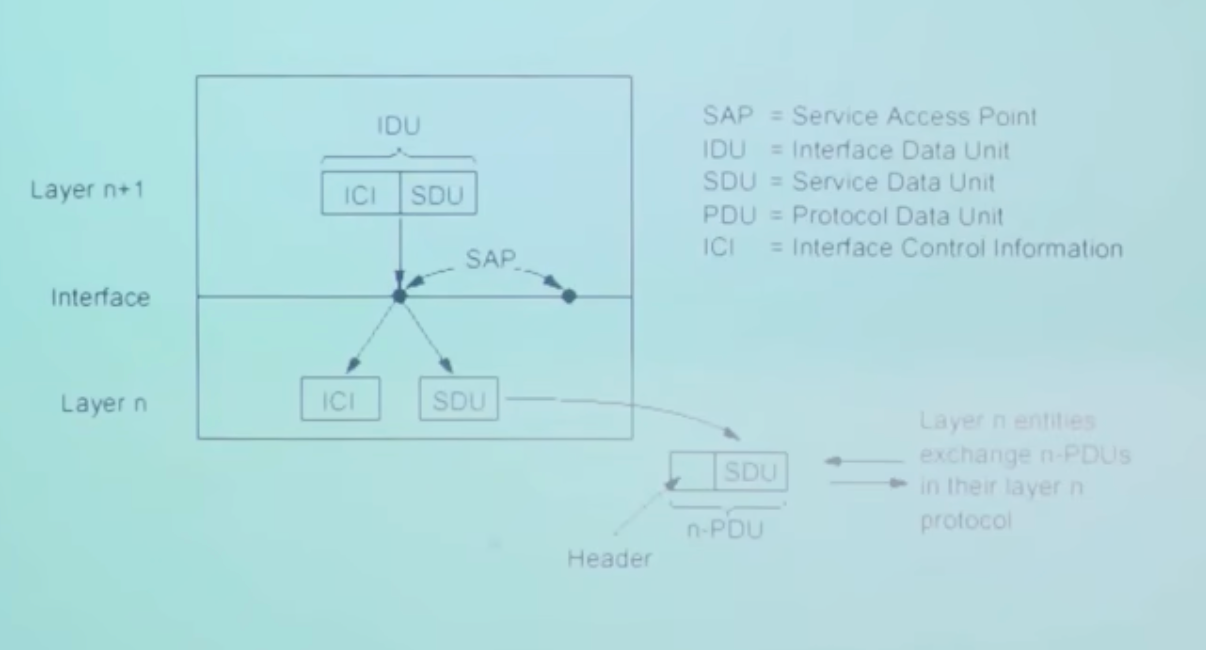
数据单元(DU)
SDU是下层传输到本层的数据, 经过自己的处理后, 加工上自己的头(Header), 作为PDU继续向上传输
第n层的PDU是第n-1层(上层)的SDU
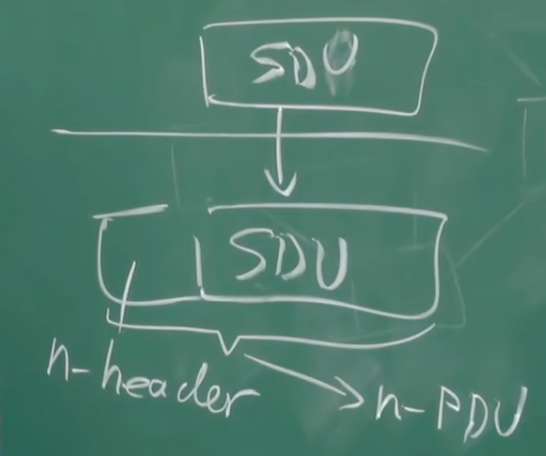
实际上, 本层拿到SDU的处理会很复杂, 会切分, 丢弃, 封装, 复杂处理等等
对复杂系统使用分层的好处
- 概念化: 结构清晰, 便于标识组件和描述关系
- 结构化: 模块彼此独立, 易于维护和升级
TCP/IP协议栈
- 应用层: 网络应用(基本单位是报文, message)
- 为人类用户或者其他进程提供网络应用服务
- FTP, SMTP, HTTP, DNS
- 传输层: 主机之间的数据传输(基本单位是段, segment)
- 在网络层提供的端到端基础上, 将不可靠通信变为可靠通信
- 区分进程
- TCP, UDP
- 网络层: 为数据报从源到目的选择路由(基本单位是分组, packet)
- 主机之间端到端的通信, 不可靠
- IP, 路由选择协议
- 链路层: 相邻节点之间的数据传输(基本单位是帧, frame)
- 两个相邻节点的通信, 点到点
- 可靠或者不可靠
- PPP, 802.11(wifi), Ethernet
- 网卡, 跳(hop)
- 物理层: 在物理链路上(基本单位是bit)
- 拿到链路层给出的帧(frame), 转化为物理信号(电磁波, 光, …)
- 也在网卡上
ISO/OSI 参考模型
- 表示层: 互联网应用解释传输的数据, 这样以来, 应用层就只关心语义方面的信息, 而无需关心数据形式
- 会话层: 维持会话(session), 数据交换同步, 检查点, 恢复
在TCP/IP协议栈中, 缺少上面的两层——这不代表TCP/IP没有相关功能, 而是将他们合并到了应用层中, 让网络应用程序自己完成会话管理和数据解释
1.8 历史
早期(1960年以前): 线路交换网络
线路交换网络的种种特性使其不适合计算机之间的通信
- 线路建立时间过长
- 独享方式占用, 不适合阵发的场合
- 可靠性不高: 核心节点损毁导致瘫痪
- 有三个组独立开展分组交换的研究
1962-1972: 早期的分组交换概念
- ARPA-Net: 小型的分组交换实验网络
- 最开始给军方用, 后面转民用
- 使用NCP协议: 相当于TCP+IP
- 每台设备即是主机设备, 也是交换设备
1972-1980: 各种专用网络
- ARPA-Net证明了分组交换可行性
- 各种存储转发的网络兴起
- 协议混乱, IBM内部就有40多种
Cerf & Kahn 网络互联原则(互联网之父)
- 极简, 自治
- 尽力而为服务模型
- 无状态路由器: 不维护通讯状态
- 分布控制
- 极具包容性
1980-1990: 体系结构变化, 网络数量激增, 应用丰富
- 1983年宕机ARPA-Net, 升级了TCP/IP协议(Flag-Day)
- 出现SMTP, FTP, TCP拥塞控制等新的协议
- DNS出现
- 出现了其他的, 国家级的分组交换网络
1990-2000: 商业化, Web
- NSF对ARPA-Net的访问设备间建立了NSF-Net, 形成双骨干网络
- NSF-Net放宽了商业应用
- Unix在操作系统中免费捆绑了TCP/IP支持
2000- : 持续扩张, 异常复杂
- TCP/IP具有包容性, 生命力很强
- 新一代杀手级应用促进了互联网进一步发展
- ISP不断扩张
- 安全性问题, 拥塞问题不断出现和被修订
- 网络变得异常复杂
Chap2. 应用层
2.1 应用层协议原理
网络应用数不胜数: Email, Web, 远程登录, P2P文件共享, 即时通信软件, 网络游戏, 流媒体, 视频会议, 社交网络, 搜索引擎, …
应用层是互联网中协议最多的层, 如果愿意, 可以自己编写程序规定协议
网络核心中没有应用层软件, 应用层只在端系统上
客户-服务器(C/S)体系结构
- 服务器一直运行, 守候在固定IP的固定端口上
- 服务器是中心, 存储资源
- 客户端主动请求服务器
缺点:
C/S体系的可扩展性较差, 服务器硬件, 网络硬件扩容困难
当需求超过承载力时, 性能会断崖式下降
对等体(P2P)体系结构
- (几乎)没有一直运行的服务器
- 任意端系统之间可以通信
- 每一个节点即是客户端又是服务器
- 自扩展性: 新的节点加入, 同时带来了请求和服务能力
- 参与的主机间歇性连接, IP地址可变
缺点: 难以管理
混合体系结构
Napster:
集中式文件搜索, P2P文件传输, 用户越多性能就越强
即时通信软件:
集中式管理用户信息(注册, 在线状态), P2P用户私聊
进程通信
进程是主机上运行的应用程序
- 同一个主机内, 采用进程间通信机制通信(操作系统定义)
- 不同主机, 采用交换报文(Message)来通信
- 客户端进程发起通信
- 服务器进程等待连接
即使是P2P架构, 在每个会话(session)上也有客户端进程和服务器进程的区别
分布式进程需要解决的问题

问题1: 进程标识与寻址
- 不仅要有唯一的标识, 还要提供找到地址的方法
- 进程的标识: IP+Port, 一些知名端口是约定的进程
问题2: 传输层如何给应用层提供服务
位置: SAP——TCP/IP: socket
- 传输层的SAP是端口号, 比如HTTPS在443, SSH在22
形式: API——TCP/IP: socketAPI
应用层要穿过层间接口达到传输层, 需要携带信息:
- 要传输的报文(本层的SDU)
- 数据源: 我方进程的IP+Port (TCP/UDP)
- 数据目标: 对方进程IP+Port (TCP/UDP)
IP+Port被称作端节点(End Point)
传输层的实体会根据上面的信息封装为TCP报文段或者UDP数据报. 移交下层时, 封装为IP数据报: 只暴露源IP, 目标IP
新的问题: 上面的信息太多了, socketAPI每次传输如果都携带就太过于繁琐
引入一个代号用来管理通信的单方或者双方: socket: integer, 这样可以让穿过层间接口的信息量最小
- 类比为os打开文件的句柄: 对句柄的操作就是对文件的操作
- socket是本地便于管理引入的, 对方不知道
- 更进一步的, 本地只有应用层, 网络层知道socket(socket是他们二者的约定)
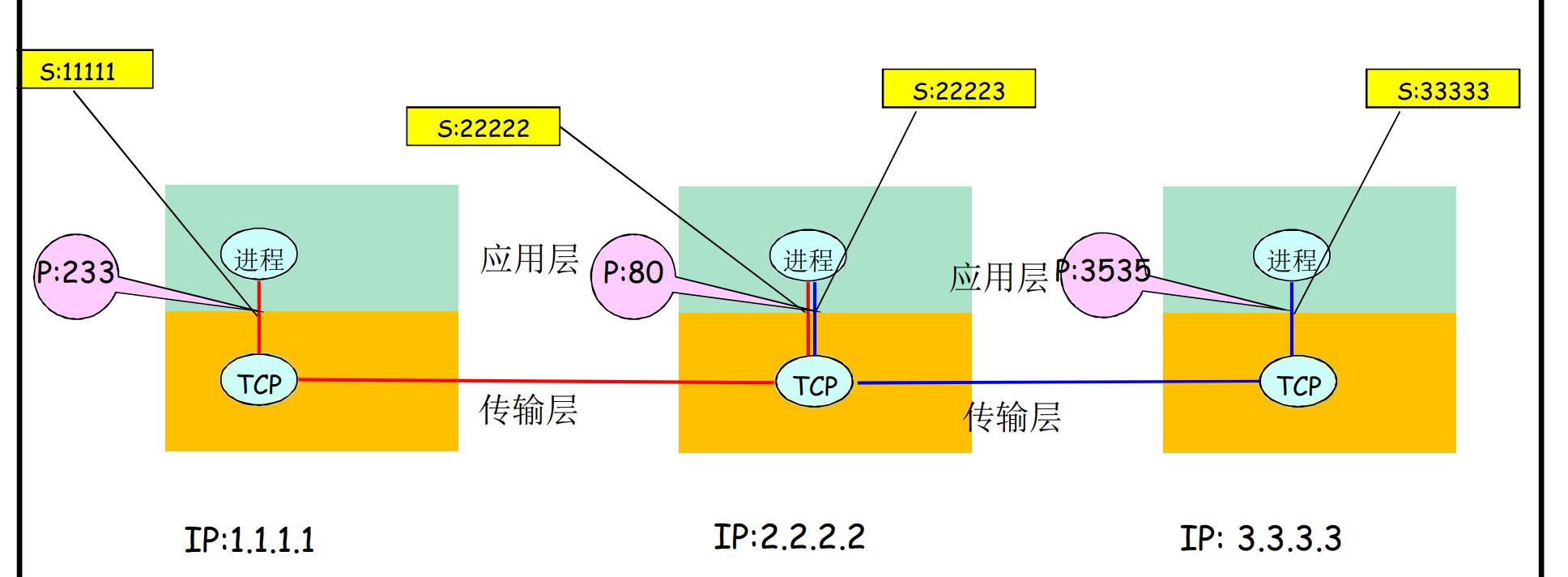
TCP-socket是四元组: 源IP, 源端口, 目标IP, 目标端口
OS会维护一张socket表, socket-[四元组]-状态, socket的在TCP建立时分阶段建立, 后面会讲
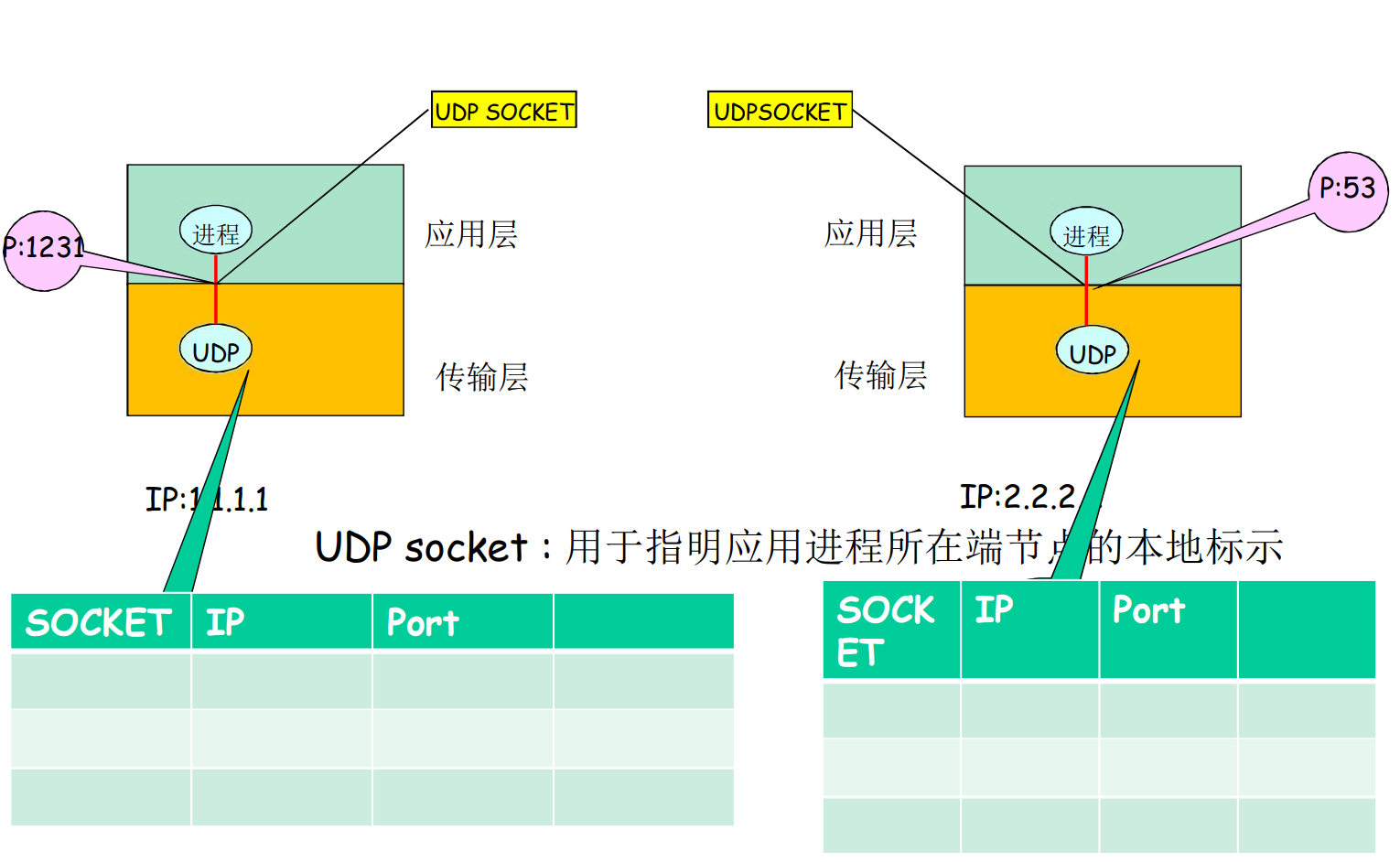
UDP-socket不需要握手, 只包含本地IP, 本地端口, 在传输报文的时候, 给出对方IP, 对方端口
问题3: 如何使用传输层提供的服务
定义应用层协议: 报文格式, 解释, 时序等
编制程序, 通过API调用网络基础设施提供的通信服务来传输报文, 解析报文, 实现应用时序等
应用层协议定义了运行在不同端系统上的进程如何交换报文
- 报文类型: 相应/传输
- 报文格式与语法语义
- 报文动作和次序
应用协议仅仅是应用和网络相关的一部分, 应用还有用户界面, 业务逻辑等等
安全性
TCP和UDP都不提供安全性保障
SSL: 在TCP上层实现, 提供加密的TCP链接
2.2 Web and HTTP
基本概念
- Web页面本身是对象, 也由对象组成
- 对象可以是HTML文件, JPEG图像, Java程序, MP3音频等等
- Web页用过URL引用对象
URL格式:
protocol://user:pswd@www.jlu.edu.cn/someDept/pic.jpeg:port任何对象都可以通过URL进行唯一标识
HTTP概况
HTTP: 超文本传输协议, Web的应用层协议, 基于TCP
- C/S模式, 客户请求, 服务器响应
使用TCP的过程
- 客户发起一个与服务器的TCP连接(建立套接字), 端口号为80
- 服务器接受客户的TCP连接请求
- 在浏览器(HTTP客户端)与Web服务器(HTTP服务器)交换HTTP报文(应用层协议报文)
- 完成交换后TCP连接关闭
HTTP是无状态的, 服务器不维护关于客户的信息
维护状态的协议很复杂, 需要维护历史信息, 处理不一致, 无状态的服务器可以支持更多的客户端
-
首先, 服务器会建立一个waiting socket监听80端口, 这个socket不传输实际数据, 只等待用户连接
-
然后, 客户机请求连接, 被waiting socket监听到, 此时进行三次握手流程, 流程结束后, 连接正式建立
-
waiting socket内部有一个队列(backlog), 存储正式建立连接, 但没有处理的请求
-
服务器从队列中取出连接请求, 为其创建一个新的connect socket, 这个socket用于正式的通信
-
waiting socket继续持续监听
非持久HTTP(HTTP/1.0)
- 最多一个对象在TCP链接上发送
- 下载多个对象需建立多个TCP链接
过程实例
-
HTTP客户端向服务器
www.jlu.edu.cn的80端口发送HTTP请求 -
位于
www.jlu.edu.cn的HTTP服务器正在监听80端口的HTTP请求, 他收到请求, 接受并通知客户端 -
HTTP客户端向TCP连接的套接字发送HTTP请求报文, 标识需求对象
/index.html -
HTTP服务器接收到请求报文, 检索被请求的对象, 并将之封装在一个响应报文里, 通过套接字发送回客户端
-
客户端收到了
index.html对象, 解析过程中发现引用了1.jpg图像对象 -
请求
1.jpg对象, 重复步骤1-5
一些文件传输软件也跑在HTTP协议上
持久HTTP(HTTP/1.1 默认)
- 多个对象可以同时在一个链接上发送
持久HTTP分为两种类型
- 流水线方式(HTTP/1.1默认): 连续发请求, 连续获取
- 非流水线方式: 请求一个, 获取一个, 再请求一个
响应时间模型
往返时间(RTT): 一个小的分组从客户端到服务器, 再回到客户端到时间(传输时间忽略)
响应时间
- 一个RTT用来发起TCP连接
- 一个RTT用来HTTP请求并等待HTTP响应
- 文件传输时间
总共2xRTT+传输时间
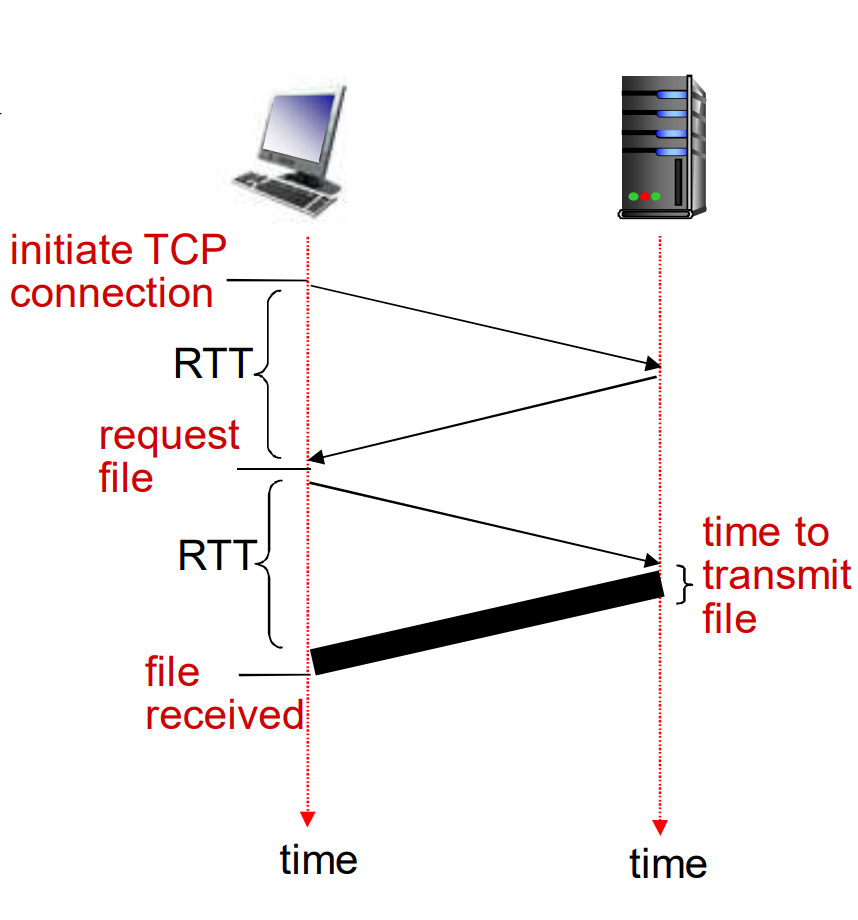
- 非持久HTTP每个对象都要经历上面的过程
- 持久HTTP只有首个对象经历
请求报文
HTTP报文两种类型: 请求/响应, ASCII编码可读
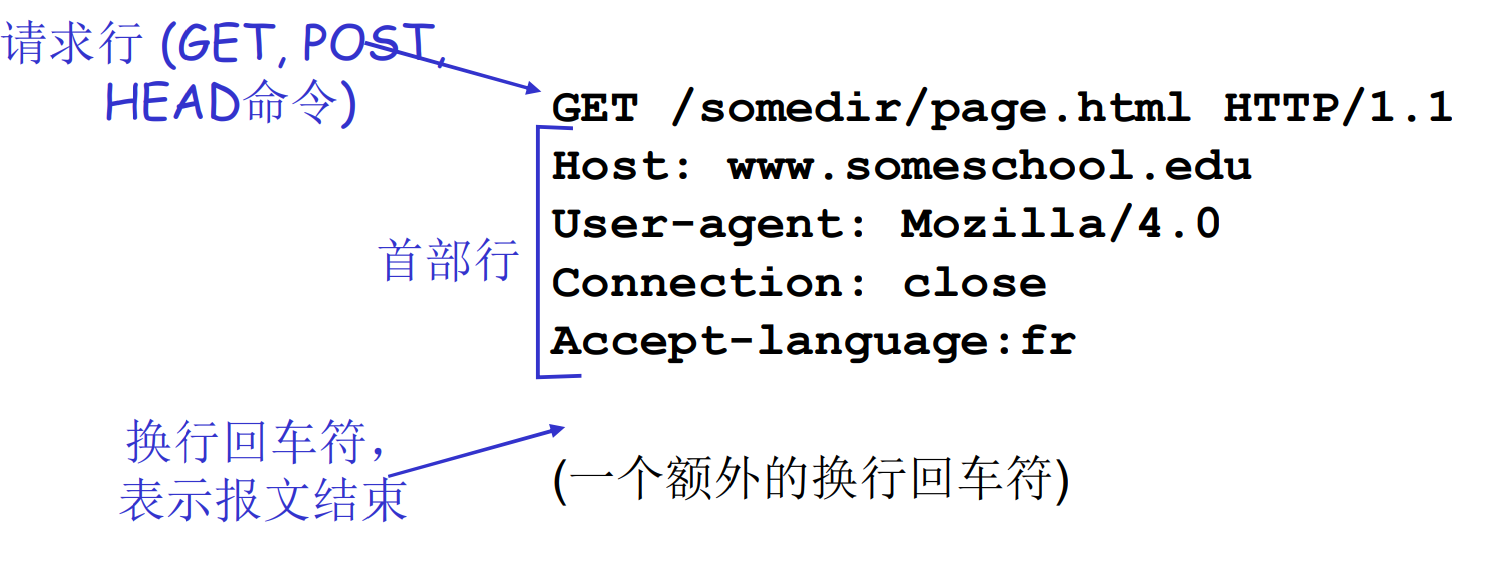
命令字
- GET: 请求文件, HEAD和BODY都要
- POST: 上传文件
- HEAD: 获取头(用来维护, 建索引等)
请求报文的通用格式
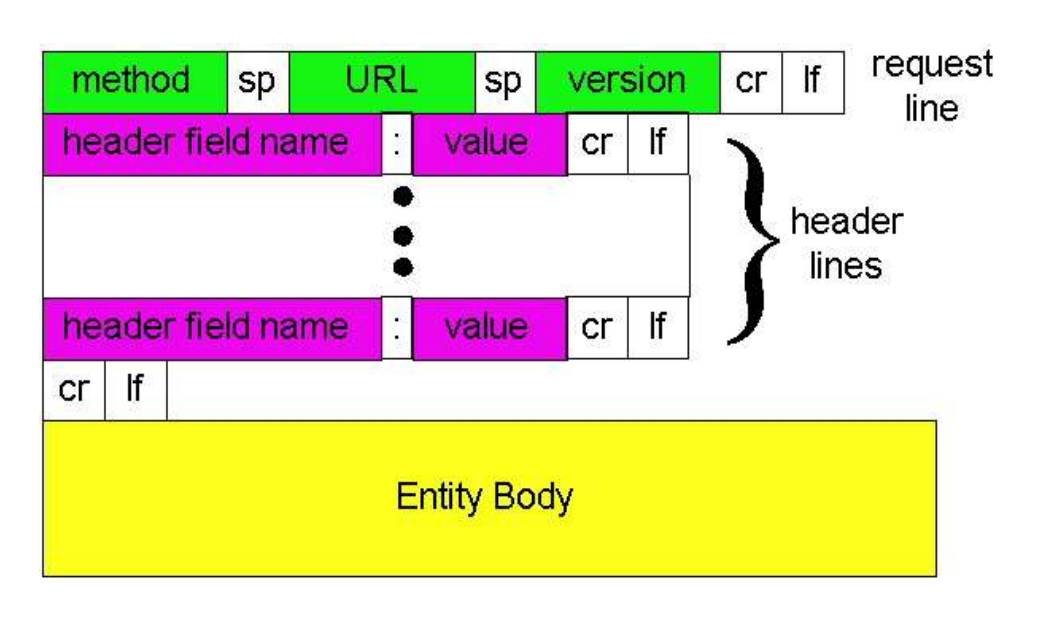
如果是GET, 则BODY一般是空的
如果是POST, 则需要给出BOD Y, 代表上传什么
向服务器提交表单
-
POST方式: Entity Body给出内容
-
GET方式: 用过输入请求行的URL参数提交
HTTP常用命令
HTTP/1.0
- GET
- POST
- HEAD
HTTP/1.1 添加
- PUT: 提交对象, 并上载到URL字段的指定路径
- DELETE: 删除URL字段指定的文件
HTTP响应报文
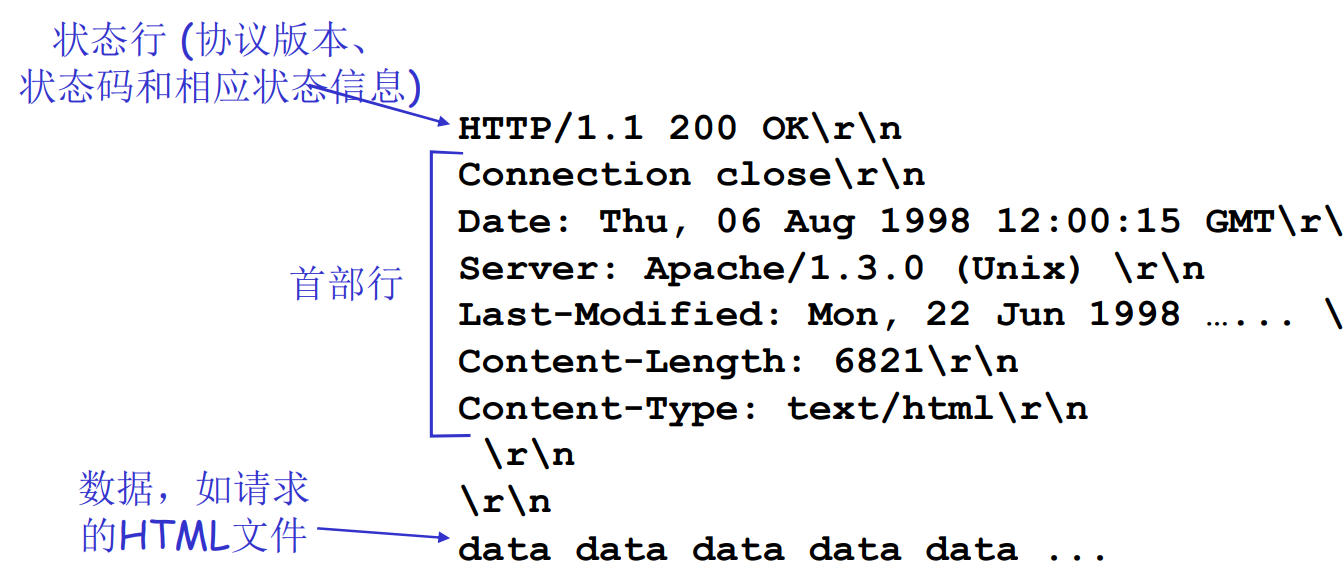
Content-Length是很有必要的, 他帮助应用程序区分报文的界限.
这是因为TCP提供的是字节流(Byte Stream), 不维护数据边界. 数据可能被拆成多份, 也可能会被合并. TCP只保证传输顺序正确
服务器先后发送了Hello 和World, 客户端可能收到
HelloWorldHelloW,orldH,el,lloWor,d
更进一步的, 假设服务器发送HTTP响应报文
HTTP/1.1 200 OK
Content-Length: 13
Hello, World!HTTP/1.1 200 OK
Content-Length: 12
Hello again!由于TCP数据流的特性, 客户端收到的可能是
HTTP/1.1 200 OK
Content-Length: 13
Hello, World!HTTP/1.1 200 OK
Content-Length: 12
Hello again!此时就需要应用需要自行通过content-length来解析内容
因为 TCP 本身不提供报文边界的概念, 应用层协议(如 HTTP)需要自己设计机制来告诉对方"消息从哪里开始, 到哪里结束"
前面提到的HTTP请求报文中, content-length不是必须要的.
-
如果是POST请求, 携带实体, 则需要
-
如果是GET请求, 则不需要. 这是因为请求有明确的结束标志
\r\n, 就算被截断了, 也可以区分边界
HTTP响应状态码
- 200 OK: 请求成功, 对象会在响应报文后续给出
- 301 Moved Permanently: 请求对象被永久转移, 新的URL在响应报文的Location首部行指定, 此时客户端软件会自动用新的URL获取对象
- 400 Bad Request: 请求不能被服务器解读
- 404 Not Found: 请求的文档在服务器找不到
- 505 HTTP Version Not Supported
HTTP协议是无状态的, 但是在实际应用中, 经常会有关于状态的实际需求
- 客户端在首次访问服务器时, 服务器发现了首次请求, 为他生成了cookie, 并在响应报文中返回了
- 客户端存储了这个cookie, 此时cookie一式两份, 分别维护在客户端和服务器中
- 服务器可能会建立cookie-数据库的索引, 维护丰富信息
- 客户端本地也会存储自己的信息
- 在以后(数天数个月)的通讯中, cookie都会夹在客户端请求中, 作为用户标识. 服务器可以通过cookie维护用户状态, 比如登陆状态, 比如购物车等等
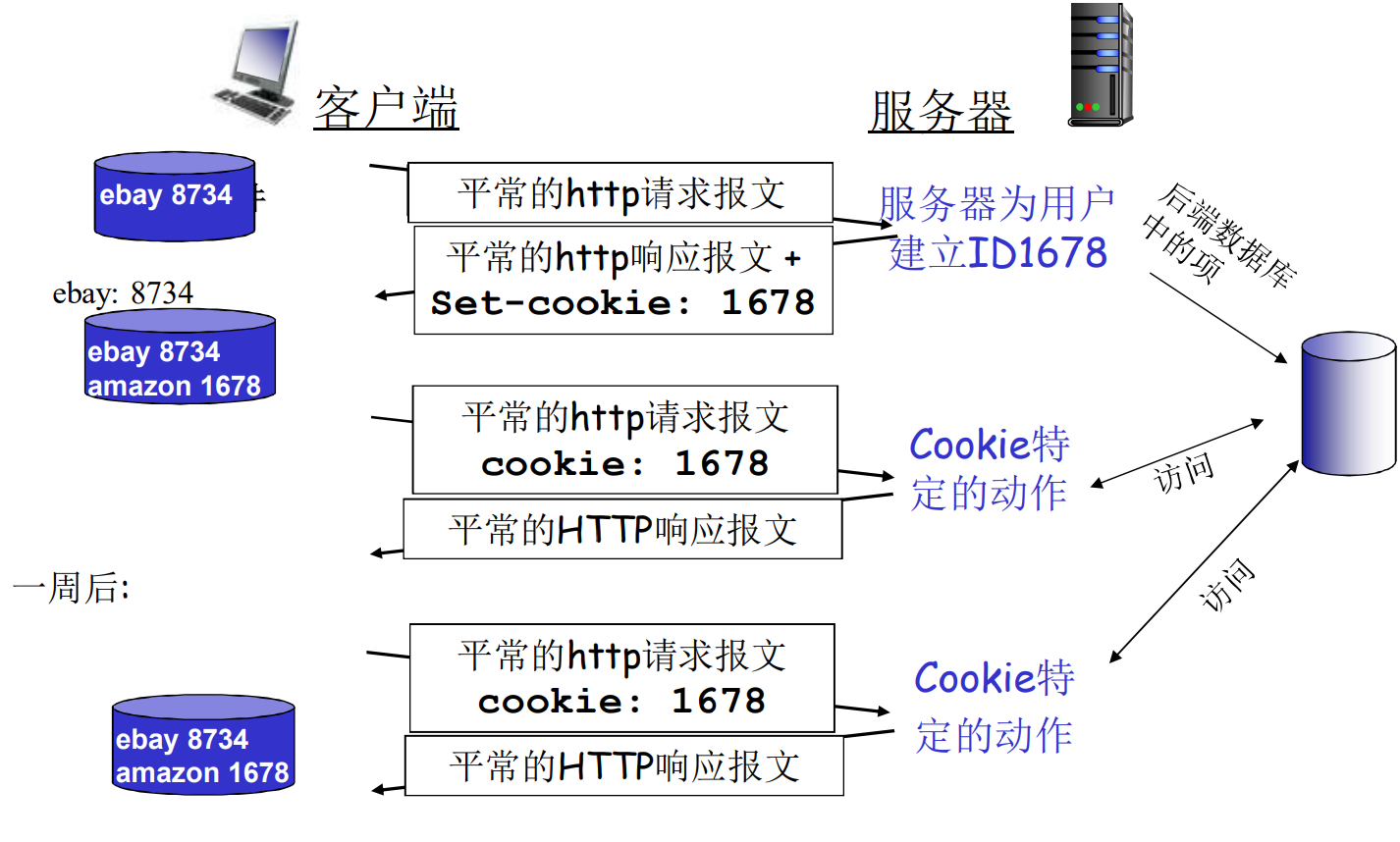
cookie在带来便利的同时, 也带来多种隐私问题. 长期携带cookie便于第三方分析用户行为
Web缓存(代理服务器)
不访问原始服务器, 即可满足客户请求
如果缓存命中, 直接返回, 否则请求原服务器
缓存即是客服端, 也是服务器, 通常由ISP安装
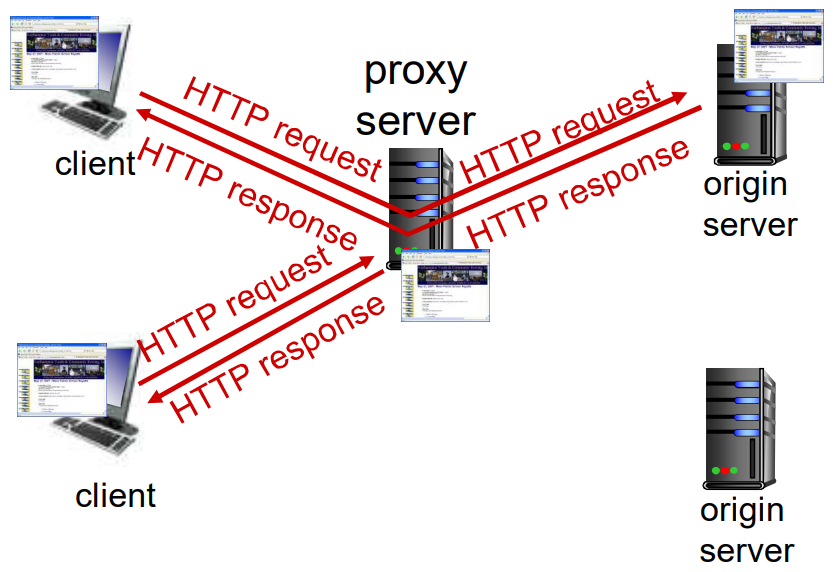
- 优化响应速度
- 减少服务器内网上行流量
- 让较弱的ICP也能够有效提供内容
条件GET
缓存可能带来新的问题: 缓存的文件版本肯能会落后于服务器的
引入条件GET: If-Modified-Since 用来向服务器查询文件在某个时间点后是否被修改了
- 如果修改了, 回复200 OK, 并携带新对象
- 如果没有, 只回复一个HEAD, 304 Not Modified
2.3 FTP
FTP即是应用层的协议, 也是一种具体的应用
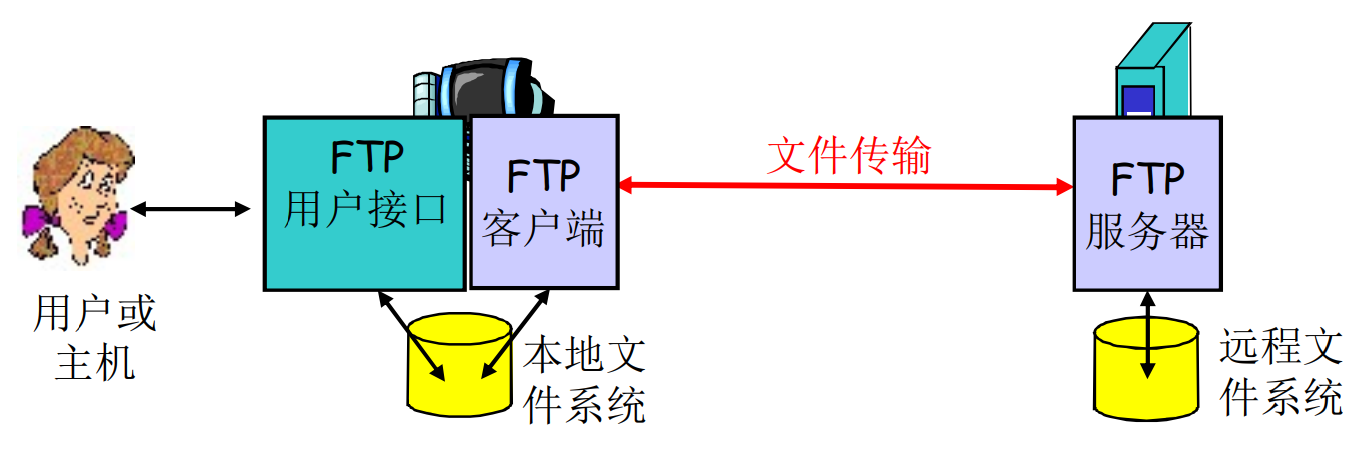
- FTP服务器监听21端口, 运行在TCP上
- RFC 959
- C/S模式
- 用户可以向服务器上传文件, 也可以下载服务器上的文件
FTP的工作实例
- FTP客户端向FTP服务器的21端口发送连接请求, 使用TCP作为传输协议, 建立控制连接
- 服务器验证客户身份信息, 返回确认
- 客户端通过控制连接发送命令浏览目录, 并请求传输文件
- 服务器接到请求后
- 主动模式: 客户端通过控制发送
PORT命令, 包含自己的IP和端口端口, 要求服务器从20号端口主动请求连接 - 被动模式: 客户端发送
PASV命令, 要求服务器提供新的端口, 客户端来请求连接 - 新建立的连接叫数据连接
- 主动模式: 客户端通过控制发送
- 文件传输完成后, 数据连接关闭
FTP是有天然的有状态协议(客户身份, 当前目录等)
FTP在控制连接上, 传输ASCII可读文本
相对于数据(带内)连接来说, 控制连接又叫带外(Out of Band)连接
2.4 Email
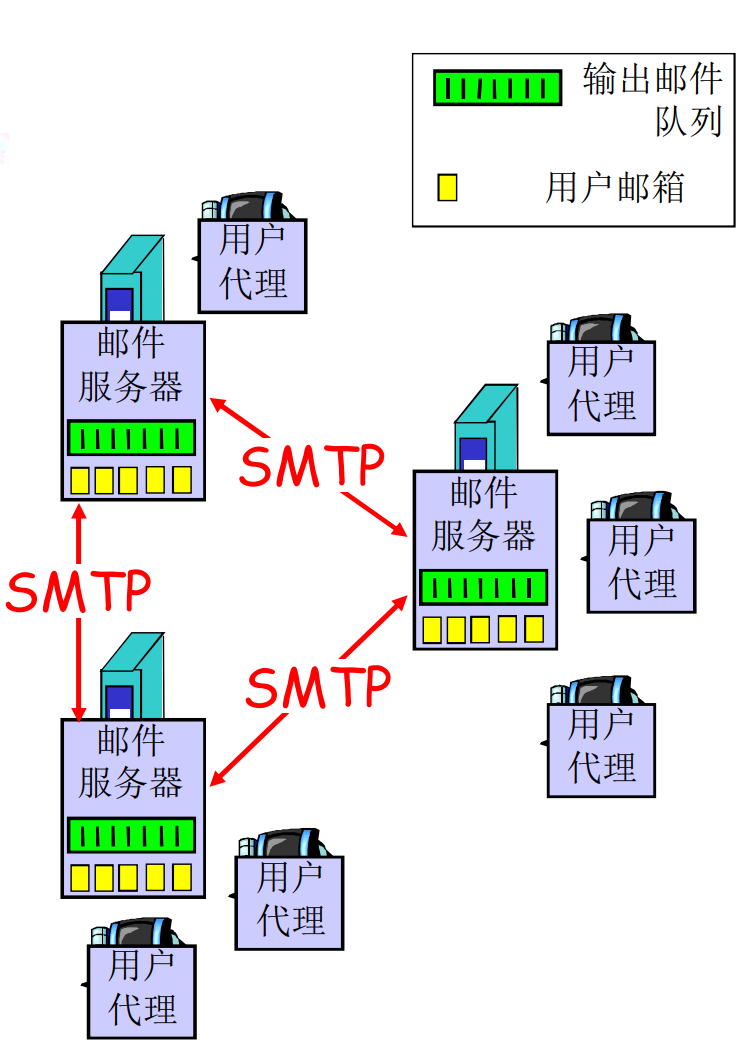
主要组成部分: 用户代理, 邮件服务器, 邮件传输协议
用户代理
- 用户界面
- 需要配置邮件服务器
- 从邮件服务器收取邮件来阅读
- 撰写邮件后上传到邮件服务器的发送队列
- 用户代理的协议有POP3, IMAP, HTTP等, 用来拉取邮件到本地
邮件服务器
- 管理和维护用户的邮件
- 邮件发送队列
- 服务器之间以SMTP协议交互
SMTP [RFC 2821]
- 监听25端口, 传输ASCII可读报文(包括命令, 响应, 邮件本身内容)
- 用户在本地撰写邮件后, 通过SMTP协议发送给服务器的发送队列
- 服务器之间的中继也通过SMTP发送, 直到目标服务器
- SMTP是持久连接
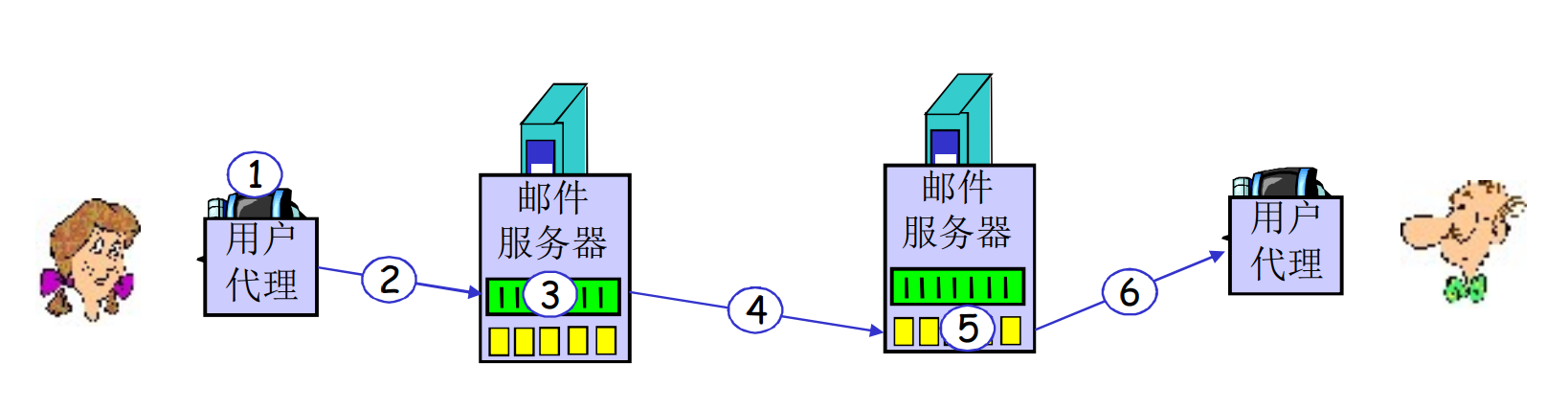
上图中, 2, 4, 为SMTP负责的过程, 6为POP3/IMAP/HTTP负责的过程
与HTTP相比, HTTP一份报文只包含一个对象, 而SMTP可以封装多个
邮件报文格式

MIME: 多用途互联网邮件扩展, 允许邮件包含非文本内容
邮件访问协议
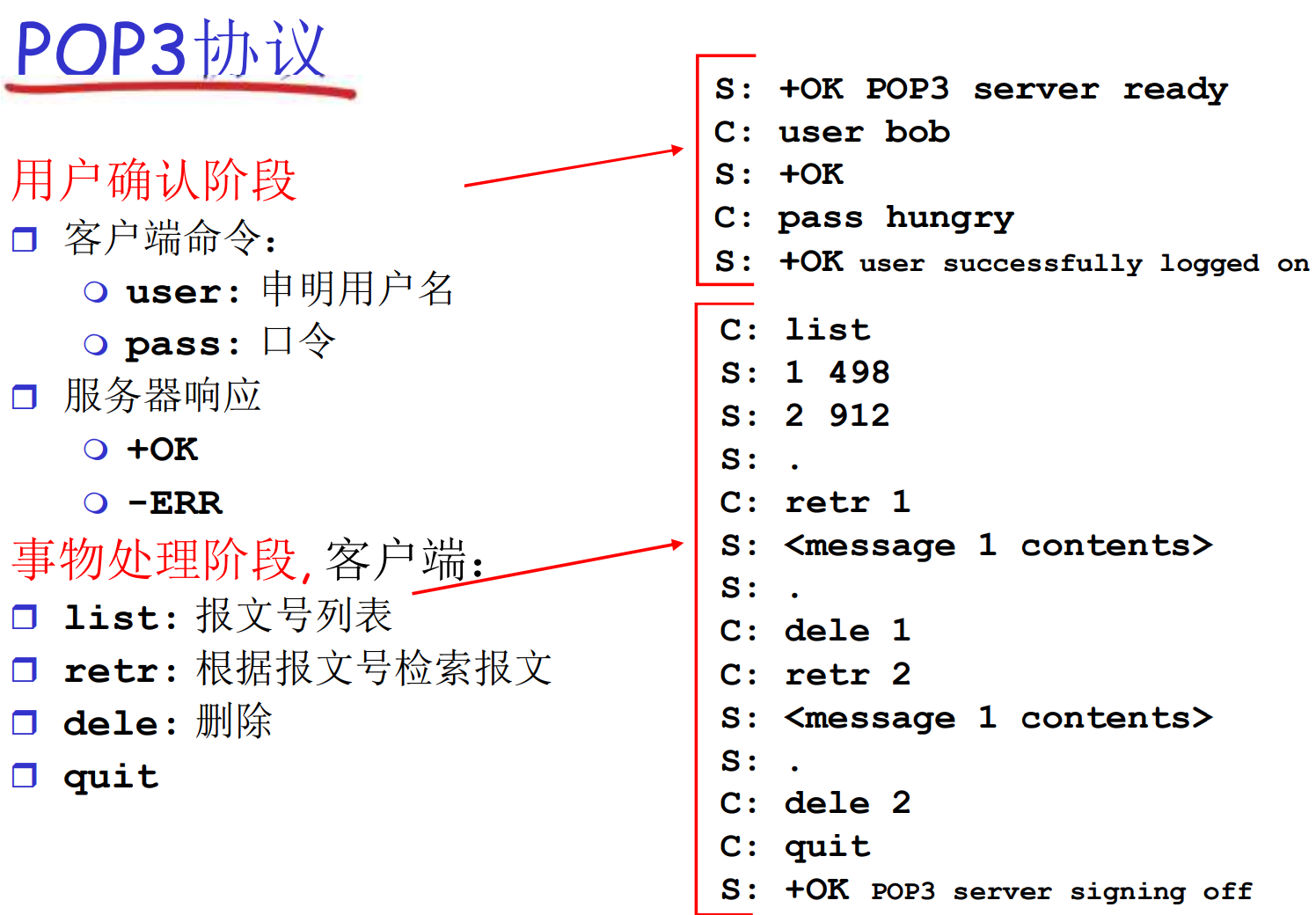
| 特性 | POP3 | IMAP | HTTP(Webmail) |
|---|---|---|---|
| 存储位置 | 本地 | 服务器 | 服务器 |
| 多设备同步支持 | 不支持 | 支持 | 支持 |
| 离线访问 | 支持 | 部分支持(缓存) | 不支持 |
| 网络依赖 | 低 | 中 | 高 |
| 安全性 | 本地存储,视加密情况而定 | 依赖于服务器的加密和配置 | HTTPS 提供高安全性 |
| 使用场景 | 单设备用户,低带宽环境 | 多设备用户,企业办公 | 临时访问邮件,轻量级用户 |
2.5 DNS
DNS不是给人服务的应用, 而是给其他应用服务的应用
DNS负责域名到IP地址的转换
DNS的必要性
在网络上, 所有的主机, 路由器用IP地址标识和寻址
- IP地址难以记忆
- 人类倾向于使用有意义的字符串标识
- 存在字符串到IP地址转换的必要性
DNS系统需要解决的问题
- 如何命名设备: 字符串的, 层次化的
- 如何完成转换: 分布式的数据库响应查询
- 如何维护: 如何增加/删除/修改域
DNS的历史
ARPA-Net的解决方案
- 用简单字符串作为主机名, 平面化
- 存在一个集中的维护站, 维护一个主机-IP的映射清单
不适合主机数量很大的情况
DNS的主要思路
- 分层的, 基于域的命名机制, 树状
- 分布式的数据库响应查询请求, 完成转换
- 运行在UDP上, 53号端口
一个有趣的事实: DNS虽然是互联网的核心功能, 重中之重, 但却实现在应用层上, 位于网络边缘. 类似DNS的例子还有很多
这说明互联网的复杂性体现在边缘, 而非核心上
DNS的功能
- 最主要的功能: 域名-IP转换
- 主机别名-规范名的转换: Host aliasing (CNAME)
- 负载均衡: Load Distribution (同一个域名可以解析出不同IP)
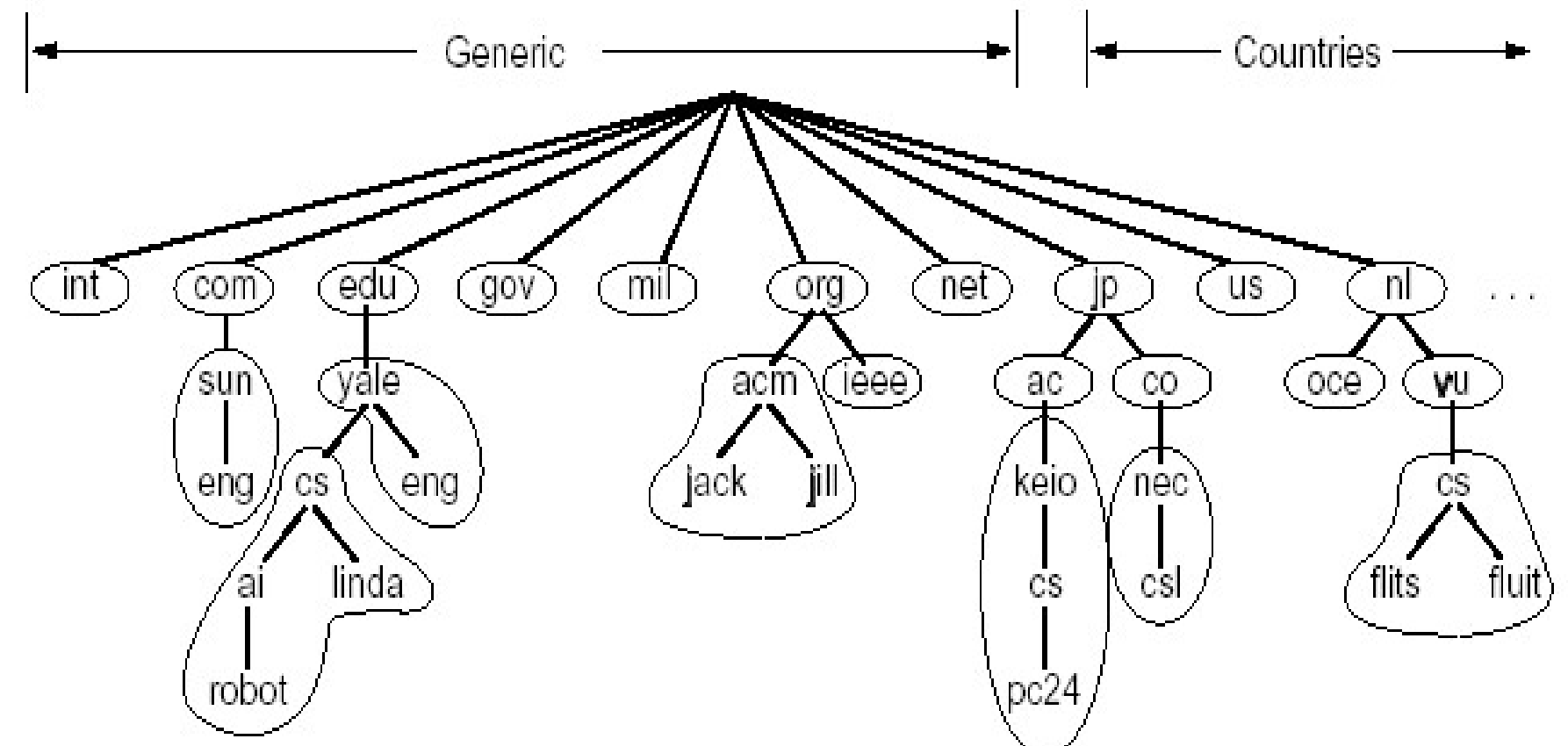
DNS域名结构
一个平面的命名会有很多重名, DNS采用了树状结构
Internet根被划分为几百个顶级域名:
- 通用的: .com, .edu, .gov, .org, …
- 国家的: .cn, .us, .jp, …
每个(子)域下可以分为若干子域, 树叶是主机
DNS根名字服务器总共有13个
域名用.间隔不同级别, 从根往树叶, 每个层次隔开, 每个域的划分方式不同
csw.jlu.edu.cncn是顶级域名, edu是二级, …
域的划分是逻辑的的, 和物理网络没有关系. 同一个域的主机可以在不同网络上:
a.jlu.edu.cn, b.jlu.edu.cn可以解析到不同位置
名字服务器(Name Server)
集中式的服务器没有容错, 我们需要分布式的解决问题
将名字空间划分为一个个的区域(zone), 区域的划分由管理者自己决定
每个区域有一个权威名字服务器, 维护管辖范围内的权威信息(域名到IP的映射). 名字服务器可以在区域之外
上级维护着下级的指针, 用以继续解析
TLD服务器
顶级域名服务器, 负责通用 顶级域名(org, net, edu, …)和所有国家级域名(cn, uk, us, …)的解析
- Network solutions公司维护com TLD服务器
- Educause公司维护edu TLD服务器
名字服务器维护的资源记录
资源记录(resource records)存储域名-IP(其他)映射关系, 与子域服务器的位置等
存储在名字服务器的分布式数据库中
格式(字段): (domain_name, TTL, type, class, vlaue)
- 域名本身
- TTL: time to live, 生存时间, 权威记录的TTL是无穷大, 其他记录TTL耗尽后, 会请求权威名字服务器更新
- class: 类别, 互联网为IN
- type:
- A: value=ipv4
- CNAME: value=域名
- MX: alue=邮件服务器别名(正规名)
- NS: value=权威服务器域名
某个名字服务器的分布式数据库的表可能如下
| domain_name | TTL | type | class | value |
|---|---|---|---|---|
| csw.jlu.edu.cn | 3600 | A | IN | 202.119.32.1 |
| www.csw.jlu.edu.cn | 3600 | CNAME | IN | csw.jlu.edu.cn |
| csw.jlu.edu.cn | 86400 | MX | IN | 10 mail.csw.jlu.edu.cn |
| csw.jlu.edu.cn | 86400 | NS | IN | ns1.jlu.edu.cn |
| csw.jlu.edu.cn | 86400 | NS | IN | ns2.jlu.edu.cn |
| mails.csw.jlu.edu.cn | 3600 | A | IN | 202.119.32.2 |
DNS工作过程
- 本地应用调用本地解析器(resolver)
- 本地解析器作为客户端, 向本地DNS名字服务器发送UDP的查询报文(本地DNS服务器的地址手动配/DHCP, 一般在网络内)
- 名字服务器返回响应报文
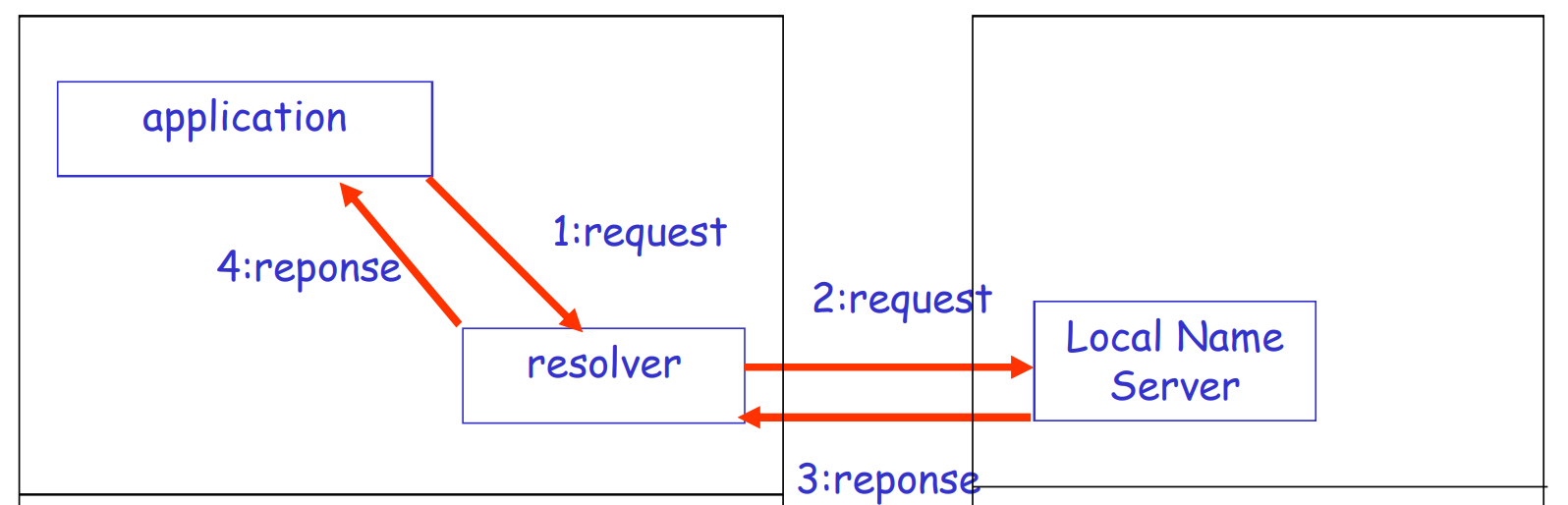
本地名字服务器
并不严格属于层次结构, 每个ISP(小区, 大学)都可以有自己的
缓存了很多信息, 如果命中就返回, 如果没有命中, 则从全球的根服务器开始, 依次向上查询
- 查询任意一个(13个之一)根服务器, 得到
.cn的权威名字服务器地址 - 查询
.cn的权威名字服务器地址, 得到edu.cn的权威名字服务器地址 - …
- 查询
jlu.edu.cn的权威名字服务器, 得到csw.jlu.edu.cn的确切IP地址
当然, 如果缓存了edu.cn的名字服务器地址, 则可以直接从这一步开始查询
胶水记录(Glue Record)
形似ns1.jlu.edu.cn这样的DNS服务会存储*.jlu.edu.cn, jlu.edu.cn这些域名的权威记录
为了防止递归查询, 实际上, ns1.jlu.edu.cn的权威记录在edu.cn对应的DNS服务器里, 这叫做胶水记录(Glue Record)
DNS协议与报文

维护: 新增一个域
假设现在要注册域名sssn.tech, 需要经过如下步骤
在负责.tech的顶级域名服务器中新增两条记录, 一条是sssn.tech的权威服务器地址(NS记录), 一条是sssn.tech 子域名的服务器地址
即, tech TLD服务器中新增两条记录
sssn.tech, dns1.sssn.tech, NS
dns1.sssn.tech, 1.1.1.1, A2.6 P2P应用
纯P2P架构
- 没有(或极少)一直在运行的服务器
- 任意端系统都可以直接通信
- 利用peer的服务能力
- Peer节点间歇上网, 每次IP 地址都有可能变化
- 分散了流量压力
例子: 文件分发(BitTorrent), 流媒体(KanKan), VoIP(Skype)
文件分发: C/S vs P2P
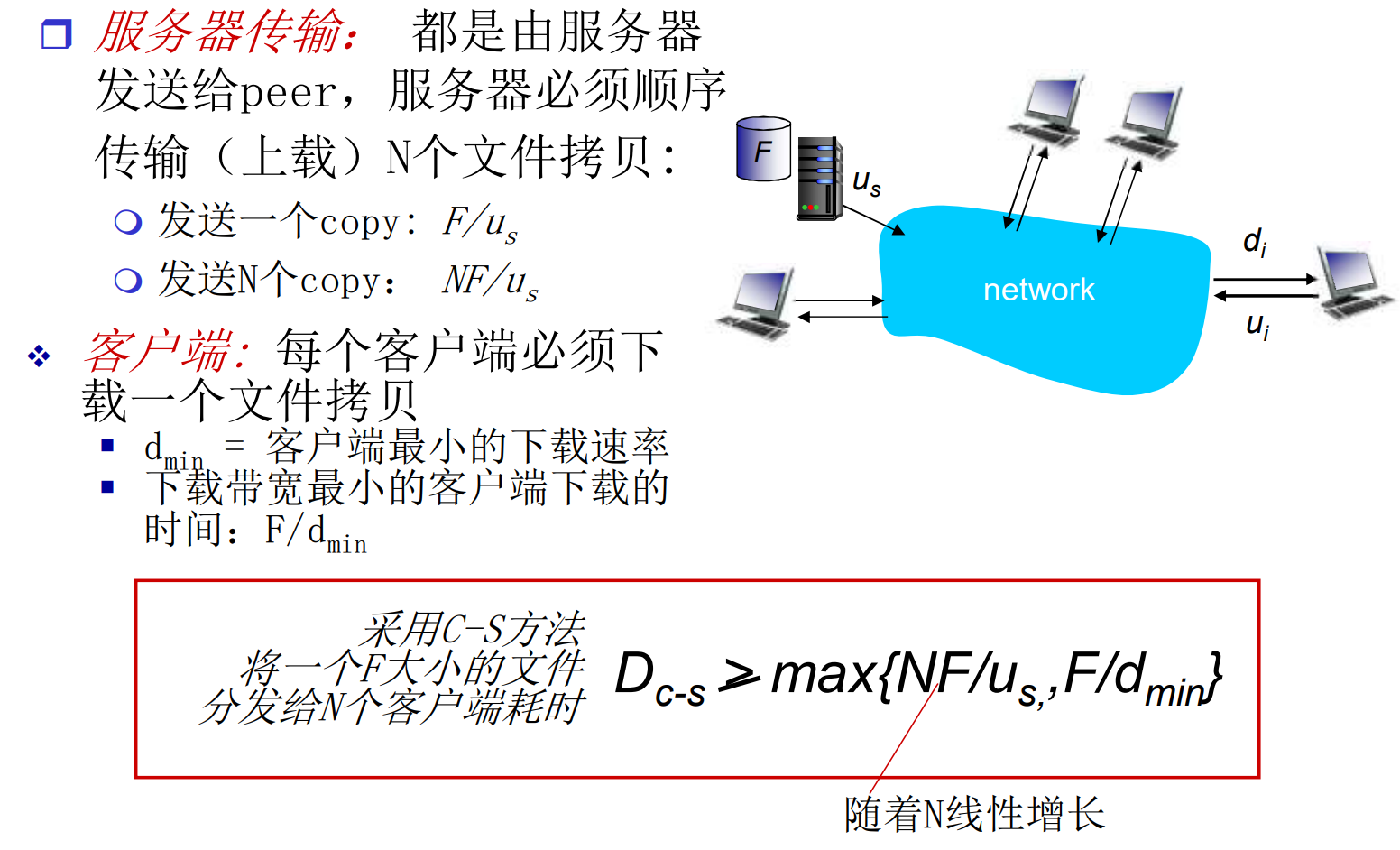
在C/S模式中, 从一个服务器分发文件, 大小为F, 到N个peer需要多长时间? 短板效应:
在P2P模式中
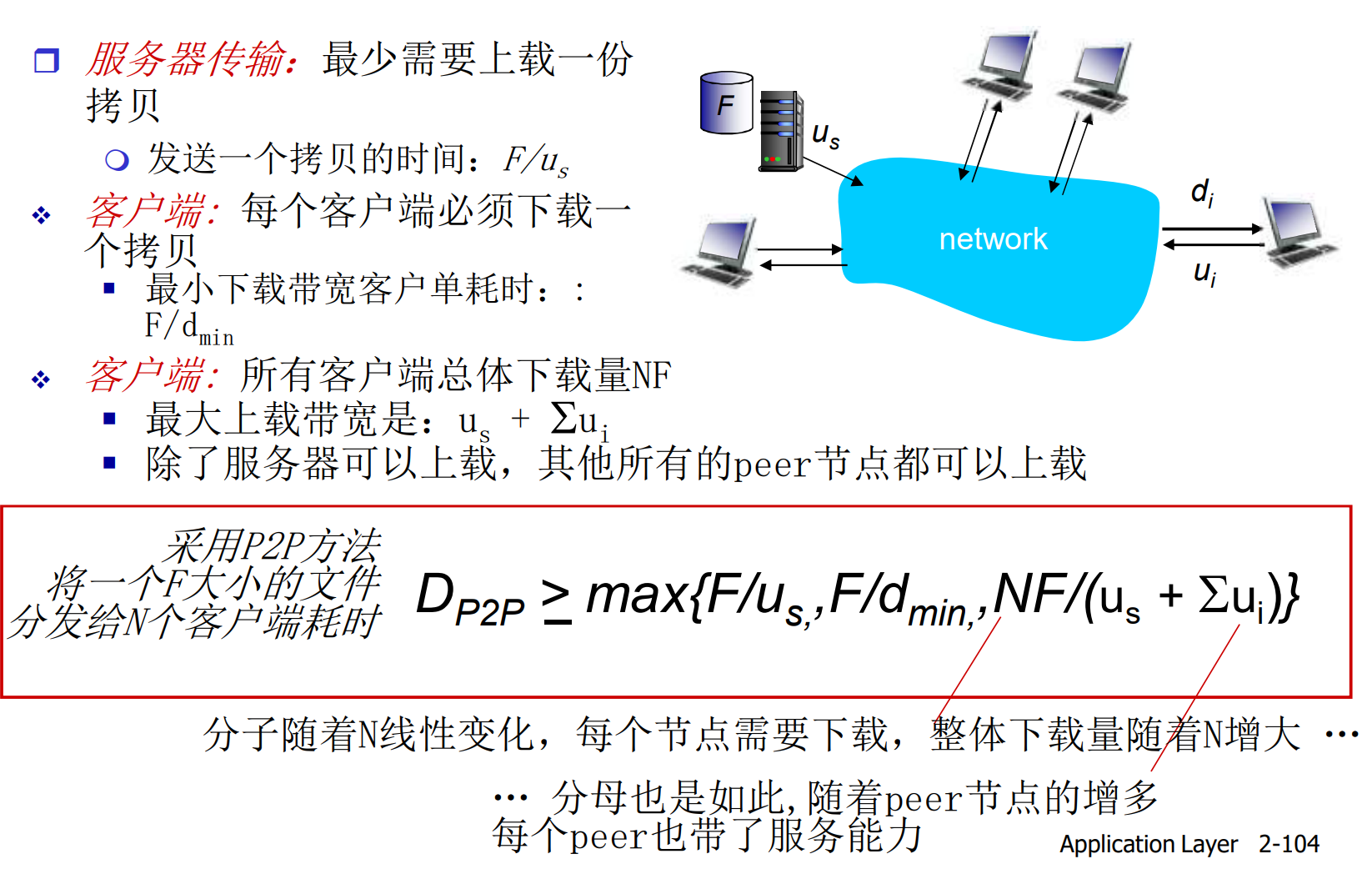
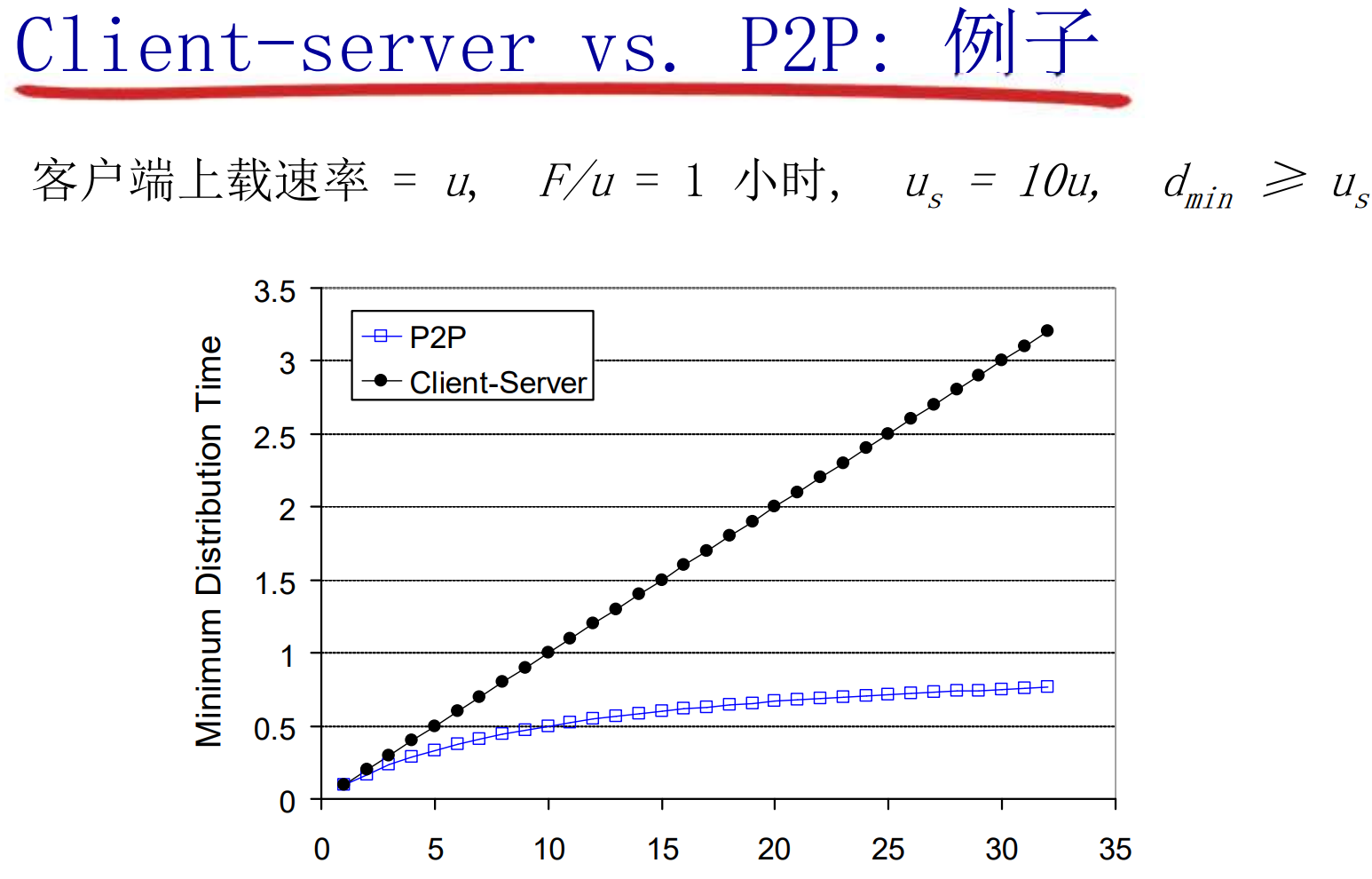
P2P模式是动态的, 可管理性较差
P2P的管理方式: 结构化/非结构化
P2P的管理方式可以分为非结构化的和结构化的两种
结构化P2P又被称作基于分布式散列表(DHT)的P2P
peer节点在应用层之间互相的逻辑连接形成了覆盖网(overlay), 如果覆盖网是任意的, 没有算法组织的, 则是非结构化, 反之则为固定的, 结构化的覆盖网
非结构化P2P: 集中式目录
Napster是典型的例子: 有一个中心的目录服务器, 维护各个节点的资源信息. 当一位客户需要资源时, 查询服务器获得有资源的peer名单, 然后再请求peer
当Alice从对等方Bob下载文件F时, 服务器也维护了Alice的信息, 则其他用户也可以同时从Alice处下载F
每个节点上线时, 都需要向目录服务器报告自身IP与本地的资源, 服务器维护了当前活跃的用户列表. 下线时, 也需要汇报
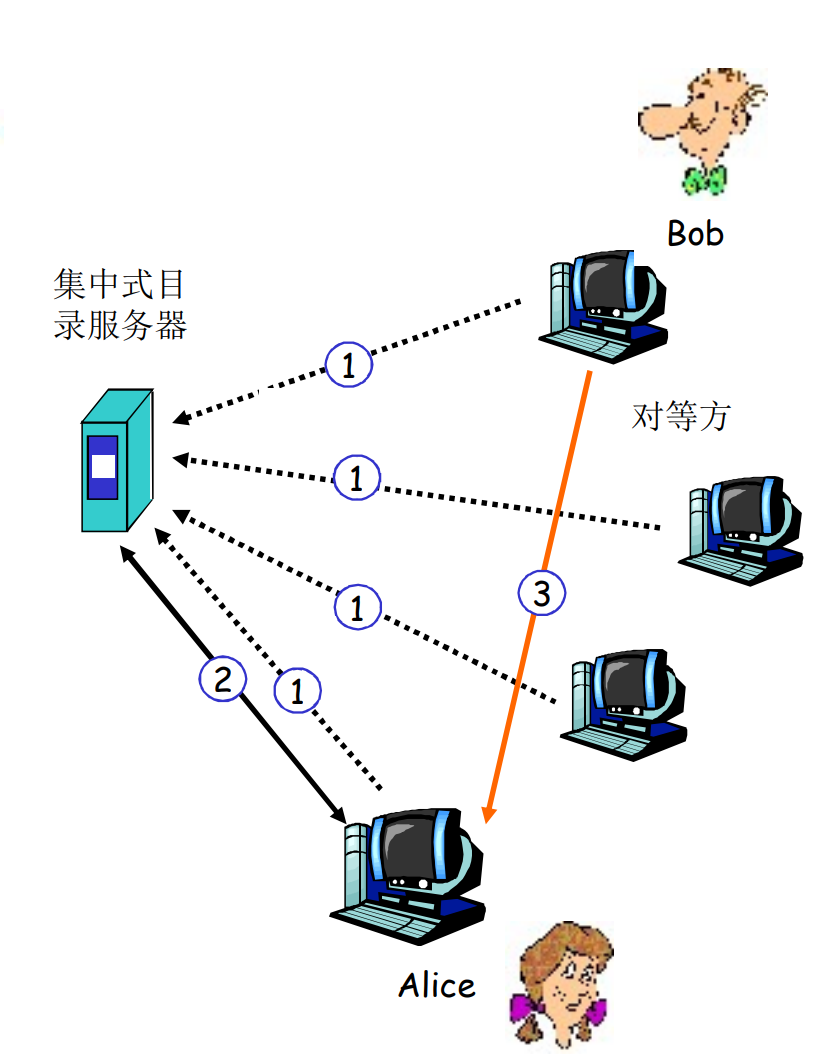
存在的问题: 单点故障(目录服务器), 性能瓶颈, 版权侵犯
非结构化P2P: 完全分布式
Gnutella是很好的例子, 没有中心化服务器, 所有节点都是peer. 代码开源, 协议公开(这使得其他人开始随意开发符合协议的第三方客户端)
所有节点构建出overlay, 每个节点大概8-10个邻居
洪泛(flooding)查询:
当Alice需要文件F时, 会对所有邻居发起查询, 所有邻居同样会转发查询, 拥有资源的节点会回复信息
Alice拿到回复信息后, 可以选择peer来下载
为了防止查询环路, 请求过多可以
- 设置TTL
- 令节点记住查询
节点的overlay这样构建:
当下载客户端软件时, 软件内置了一些大概率在线的节点, 客户端ping这些节点, 这些节点会ping自己的邻居, 令他们继续转发ping, 并令向客户回复pong
客户端根据回复的pong, 随机挑选一些作为peer. 当客户端下线时, 要通知自己的peer, peer收到下线通知后, 会补充自己的peer数量, 以维持正常运行
非结构化P2P: 混合体
KazaA是典型的利用不对称性的例子
每个对等方可以是组长或者组员, 组员和组长有TCP连接, 组长之间有TCP连接
组长会维护组员的信息
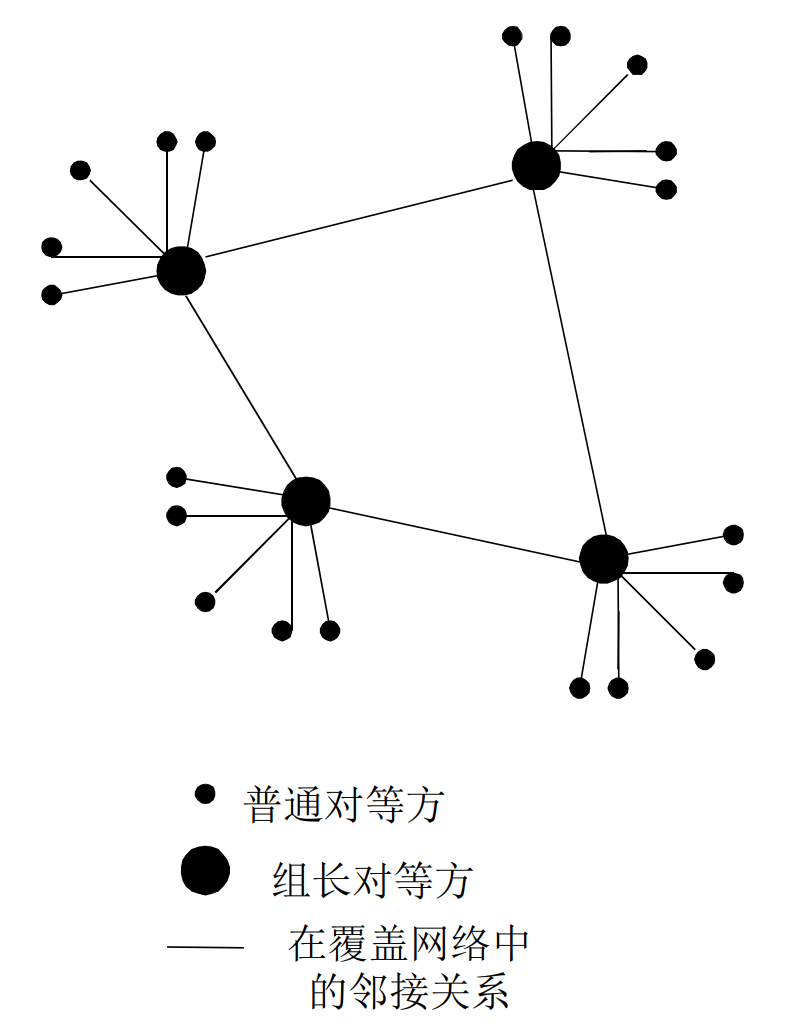
组长维护这样的表: 文件, 文本描述, 哈希值
用户用描述向组长发起查询, 组长先查询自己的表, 如果没有, 则转发请求给其他组长
BitTorrent
文件被分为一个个的块(256KB)
用户被分为一个的Torrent(洪流, 组), 组内交换文件块.
每个节点维护一个Bitmap, 维护自己的文件的每个块的持有情况. 定期泛洪, 每个节点交换Bitmap, 同步文件持有信息
一个新客户端加入Torrent之后, Bitmap是空的. 他随机请求四个稀缺的块来下载, 在本地维护(启动资源), 然后他可以按需请求
在节点向其他节点提供服务时, 优先向为自己提供更多服务的节点分配更多资源(奉献者优先)
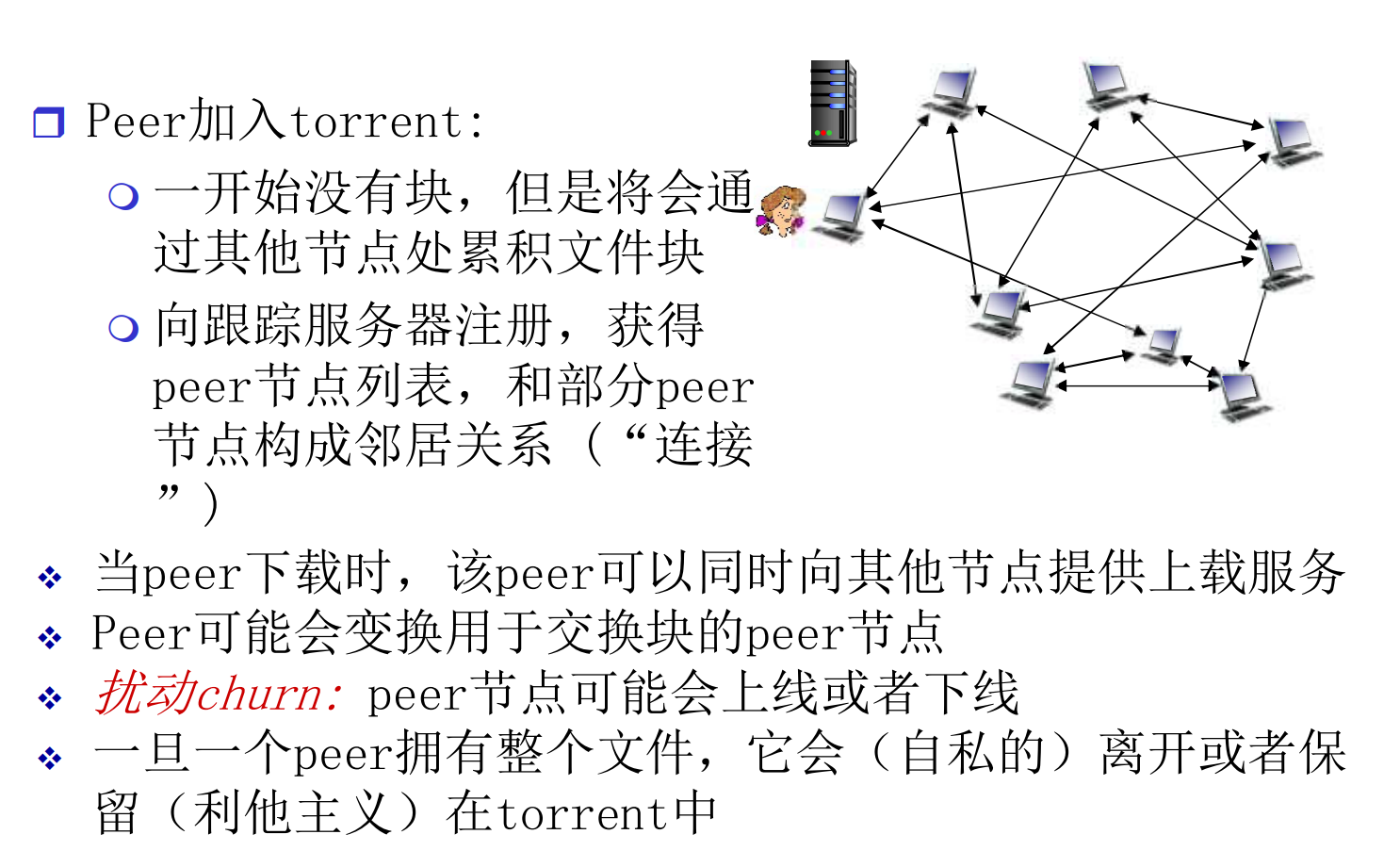
如果拥有了整个文件, 就会留下种子
2.7 CDN内容分发网络
背景: 互联网中70%左右的流量都被视频业务占据. 如何并发的, 向百万级的用户提供视频服务
解决方案: 分布式的, 应用层的异构解决方案
流化播放(Streaming)
边下边播, 本地有缓冲区
DASH协议: 基于HTTP的流化协议
视频每8-10s切成一片, 处理成不同解析度, 不同压缩标准的块. 这样, 一个视频就有了多种版本
维护一个告示文件(manifest file), 描述每个块的信息和URL
客户端在点播时候, 下载告示文件, 一边播放, 一边决定后续请求哪些块(根据网络和本地环境动态请求)
挑战: 中心服务器的并发压力太大
内容分发网络(CDN, Content Distribution Networks)
互联网内容提供商(比如Netfilx, YouTube)向CDN公司购买服务, 将内容提前部署在分布式的CDN服务器上, 作为缓存节点
用户在请求内容时, 由CDN服务器提供
CDN公司有两种主流的服务器部署策略
- enter deep: 将服务器部署在local ISP中, 位于网络底层, 为本地用户提供高质量服务, 但是需要更多硬件
- bring home: 部署在少数几个关键位置, 比如ISP的连接位置, 需要更强性能
CDN运行在网络的应用层上, 位置在网络的边缘
OOT挑战
- 用户从哪些CDN节点获取内容
- CDN阶段存储哪些内容
- 用户在网络拥塞时的行为
简单的CDN内容访问场景
Bob作为客户端, 请求视频http://netcinema.com/av10492
视频存储在CDN, 位于http://kingcdn.com/neta338
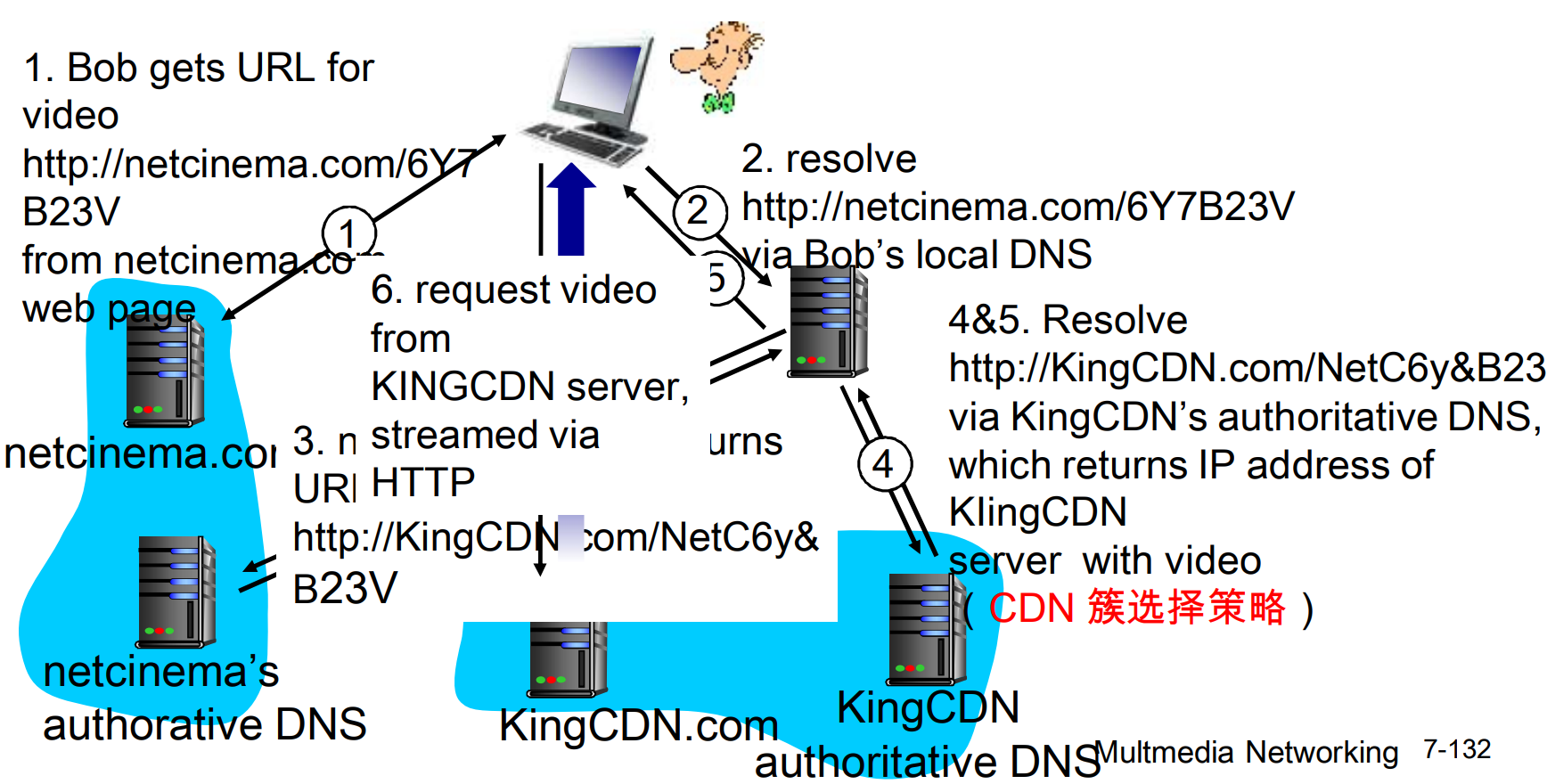
上面的图看着复杂, 总结下来过程不难:
- Bob 的浏览器请求
http://netcinema.com/av10492 - 浏览器通过 local DNS 查询
netcinema.com的 IP 地址 - 如果 local DNS 没有缓存,会向上层递归查询,直到权威 DNS 服务器
- 权威 DNS 服务器返回一个 CNAME 记录,例如
kingcdn.com,指向 CDN 的域名 - 浏览器继续请求
http://kingcdn.com/neta338 - CDN 的 DNS 服务器根据 Bob 的网络位置分配一个合适的 CDN 边缘服务器
- 浏览器向分配的 CDN 边缘服务器发起请求,获取资源
上述过程中, 路径从/av10492到/neta338的变化是HTTP 301/302重定向, 或者后端业务逻辑做的, 和CNAME记录没有关系
2.8 TCP套接字编程
套接字了解即可
2.9 UDP套接字编程
套接字了解即可
Chap3. 传输层
3.1 传输层概述和服务
传输服务和协议
传输层向上提供的服务是应用进程之间的, 以报文为单位的逻辑通讯
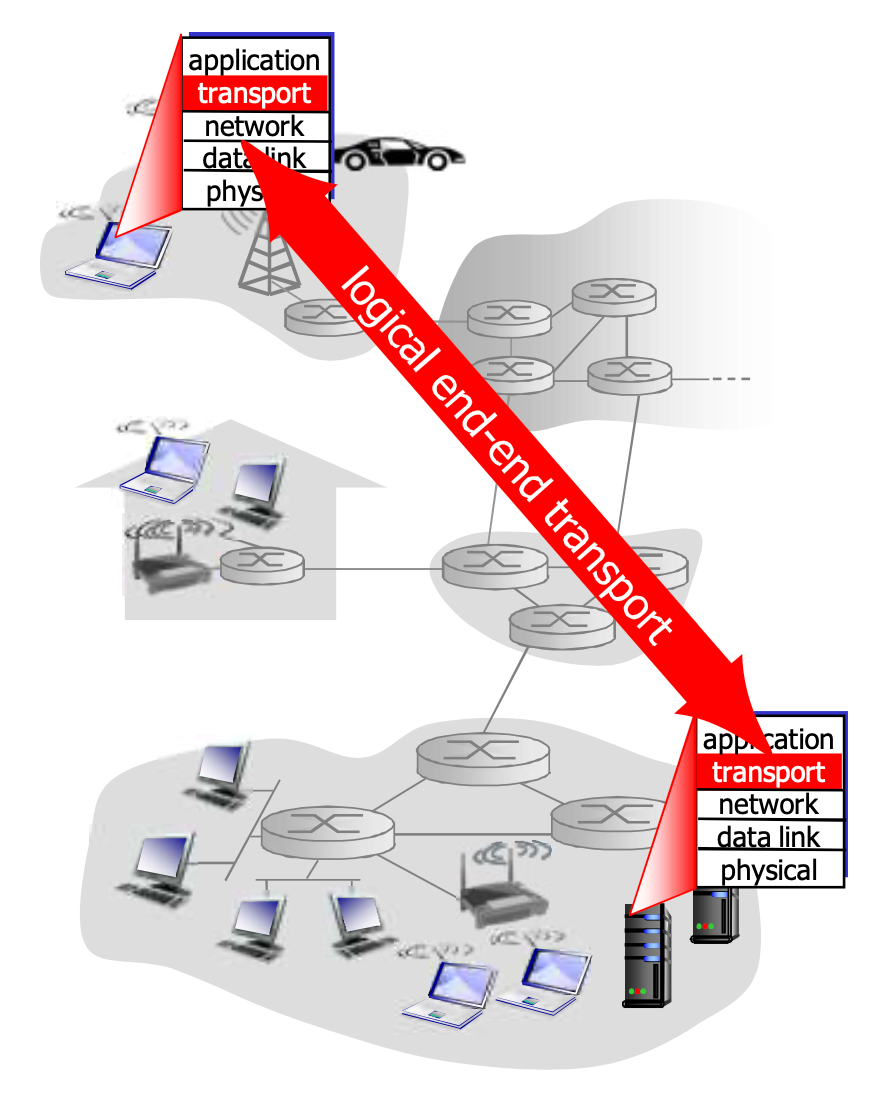
在发送端, TCP/UDP会将报文分成报文段(segment), 移交给网络层, 所以段是传输层的PDU
在接收端, 收到报文段后, 去掉段头, 重新排序, 以字节流的形式交给应用层. 上面已经提到, 字节流只保证顺序, 不提供界限
传输层向上提供TCP/UDP两种协议, 下方只有一种IP协议. 网络层只能提供以分组数据报为单位, 尽力而为的存储转发服务
传输层 vs 网络层
网络层提供主机到主机的通讯, 传输层细化为进程到进程的通讯. 传输层依赖于网络层的服务, 并在基础上加强:
- 乱序 -> 有序
- 明文 -> 密文
- 丢失 -> 纠错
左侧是传输层的特性, 网络层在其基础上, 完善了功能, 向应用层提供更好的服务
并不是所有品质都可以加强: 延迟, 带宽等无能为力
传输层在网络层基础上, 提供的另一个重要功能是复用与解复用, 即, 作为发送端时候, 要将各个进程的数据打包发送, 而作为接收端时, 需要接包数据, 恢复到进程级别
类比Alice家给Bob家写信, Alice家有12人, Bob家有12人, 总共就有144封信
Alice家的管家将144封信打包在一起, 放入自家信箱
作为邮政公司, 将Alice家的信统一带到Bob家即可
Bob家的管家在信箱收取, 然后区分每个成员的信, 交给具体的人
传输层协议
可靠的, 保序的传输: TCP
- 多路复用, 解复用
- 拥塞控制
- 流量控制
- 建立连接
不可靠, 不保序的传输: UDP
- 多路复用, 解复用
- 没有为尽力而为的IP服务提供更多加强
都不提供的服务
- 延时保证, 带宽保证
3.2 多路复用与解复用
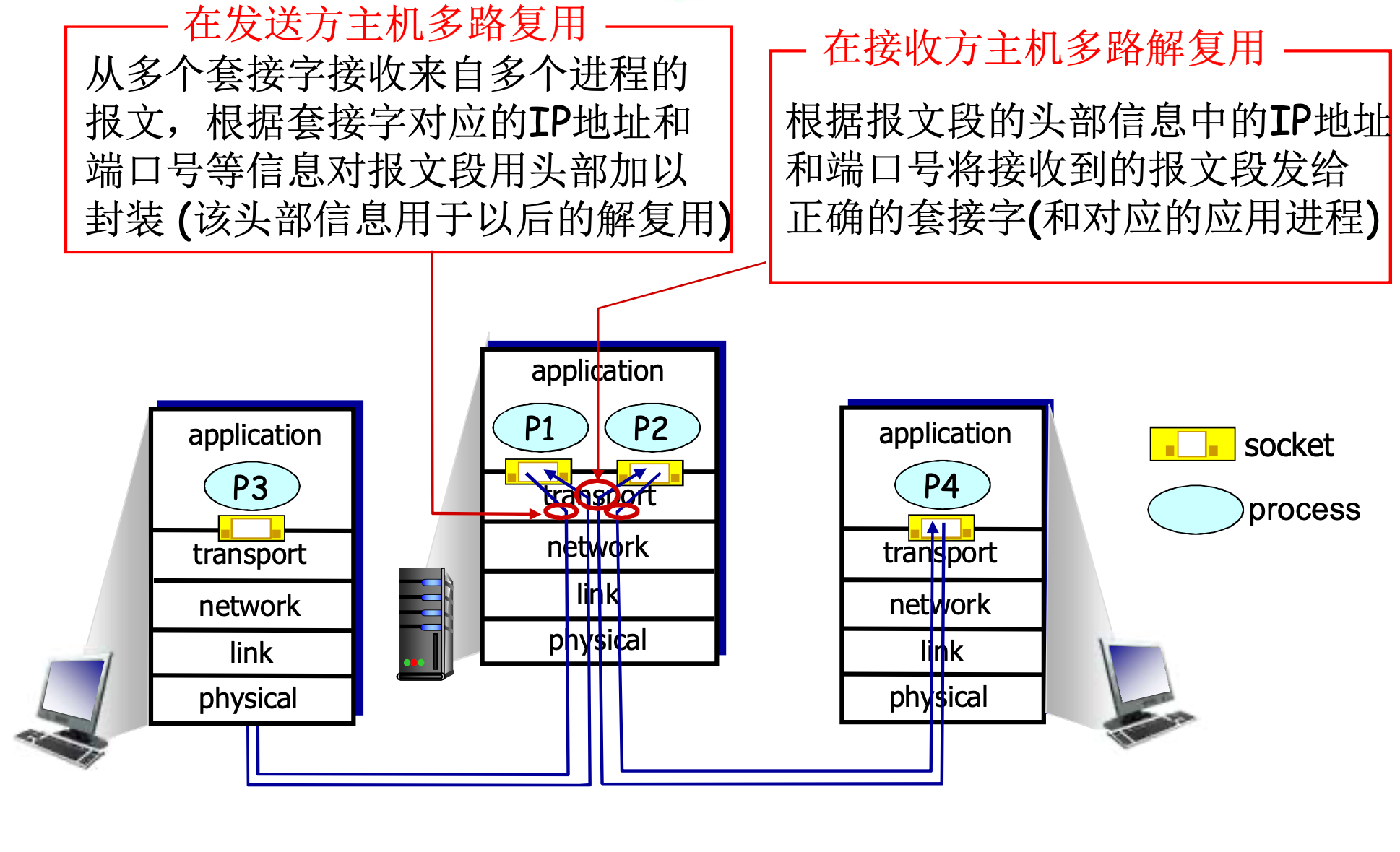
多路解复用的工作原理
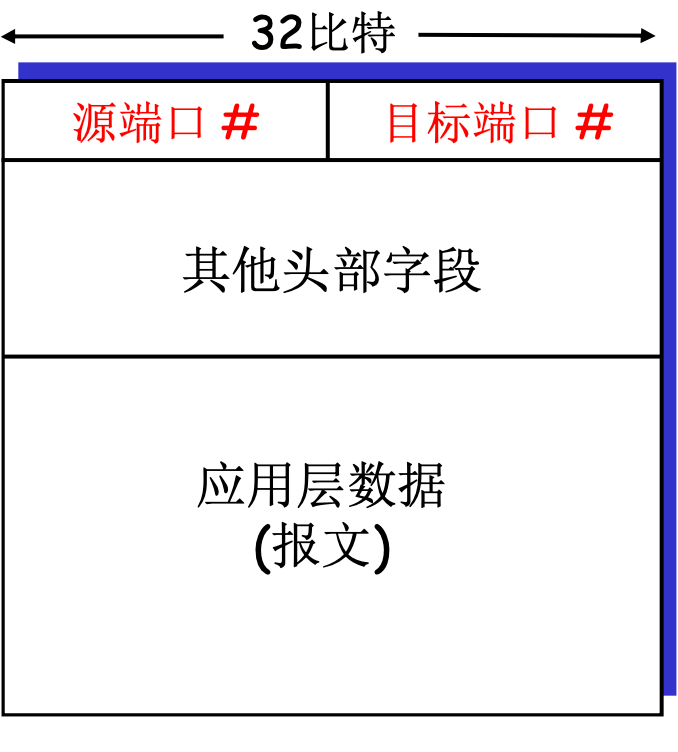
主机收到IP数据报
- 每个数据报标有源地址, 目标地址, 源端口号, 目标端口号
- 每个数据报承载一个传输层报文段
OS结合IP与端口号将报文发送给对应的套接字
UDP套接字: [本地IP, 本地端口]
TCP套接字: [本地IP, 本地端口, 远程IP, 远程端口]
假设一个主机的IP唯一, 有n个逻辑端口, 不考虑其他限制, 则:
- 最多建立n个UDP套接字
- 可以建立无限个TCP套接字
3.3 无连接传输: UDP
UDP: 用户数据报协议
在网络层IP协议的基础上, 除了用多路复用解复用实现了进程到进程到通讯, UDP没有更近一步的其他功能
- 尽力而为: 可能丢失, 可能乱序
- 无连接: 不需要握手, 每个UDP报文段独立处理
UDP被用于流媒体, DNS等应用(一次往返搞定, 事务型的应用)
UDP也可以实现可靠传输, 需要在应用层上加其他机制
为什么要有UDP?
- 不建立连接, 延时小
- 报文段的头部很小(开销小, 只有8字节, TCP有20字节)
UDP是直肠子, 不做拥塞控制
UDP校验和: 错误控制
没有通过校验和的UDP报文段会被丢弃
发送方:
- 将报文段内容视为一个的16比特整数
- 校验和: 加法和, 进位回滚, 最终结果取反
- 发送方将校验和放在头部
接收方:
- 检查校验和, 如果不符合一定错误
- 如果符合, 也不一定正确(残存错误)
3.4 可靠数据传输(RDT)原理
问题描述
RDT在应用层, 传输层和数据链路层都很重要
是网络top10问题之一
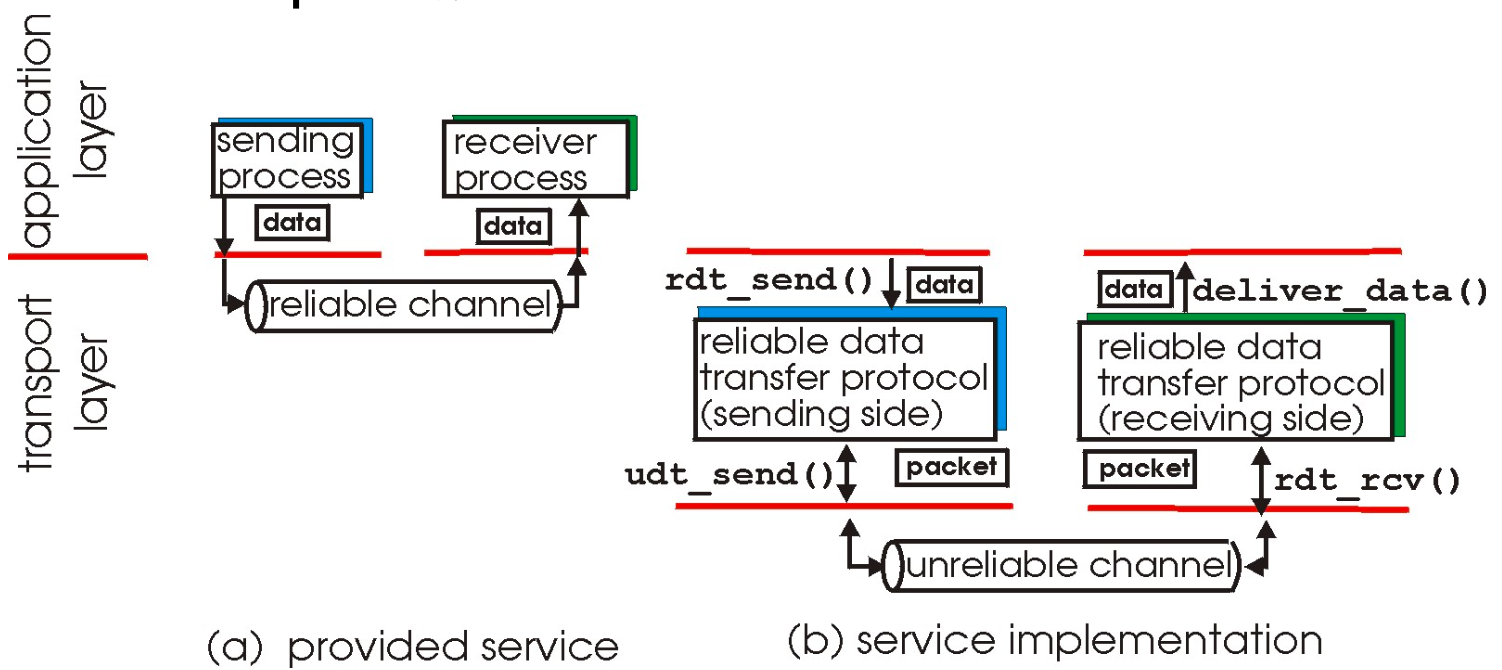
上面右图右下角写错了, 是udt_rcv(), 即不可靠的接收
要在下层不可靠服务的基础上, 向上层提供可靠的服务
底层channel的不可靠性决定RDT的复杂性: 越不可靠RDT的任务就越多, 反之如果channel比较可靠, 则RDT就只需补齐一点差距即可
接下来我们将:
- 渐进式的开发RDT的发送方和接收方
- 只考虑单向数据传输
- 但控制信息是双向流动的(接收方确认, 反馈等等)
- 双向数据传输问题实际上是2个单向问题综合
- 使用有限状态机(FSM)描述发送方和接收方
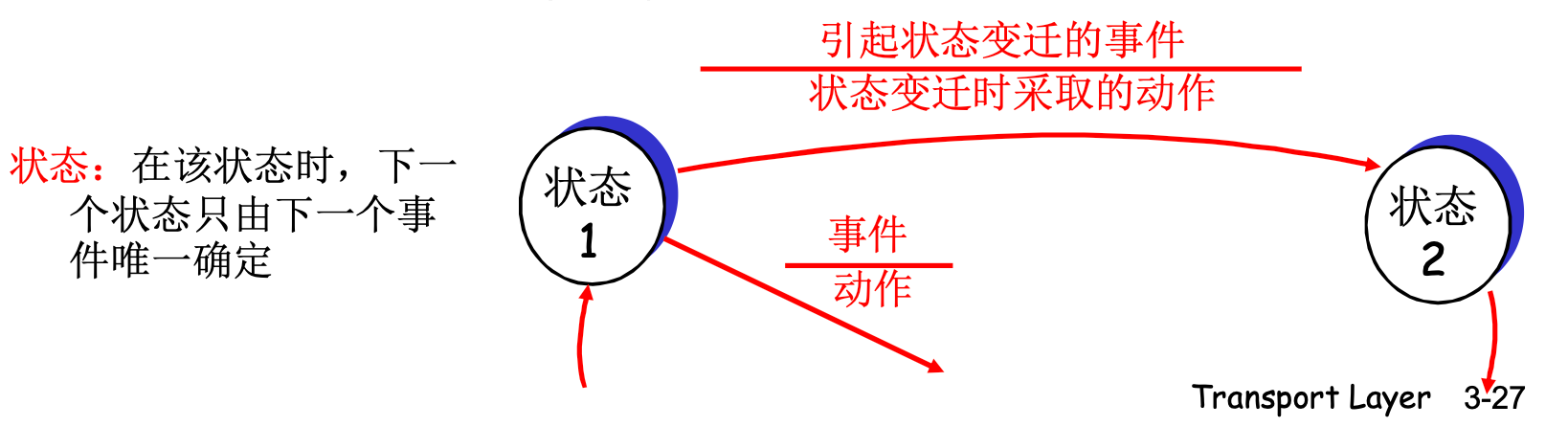
FSM: 有向图, 用节点和边表示状态本身和状态迁移
用分子表示事件, 分母表示迁移时采取的动作
RDT 1.0: 在可靠信道上的可靠数据传输
假设下层信道是完全可靠的
- 没有比特出错
- 没有分组丢失
发送方和接收方的FSM
- 发送方将数据发送到下层通道
- 接收方从下层信道接收数据
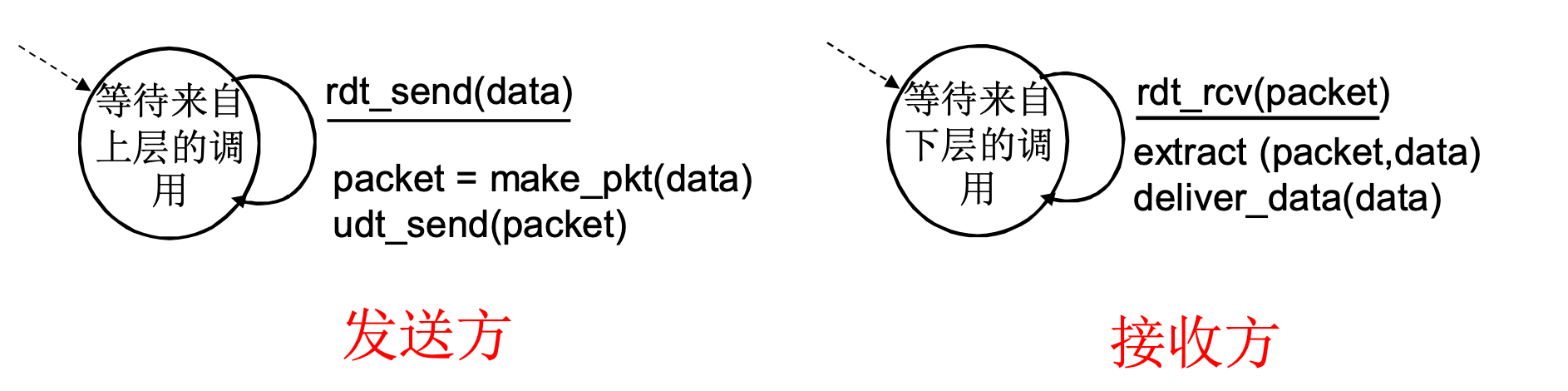
因为下层可靠, RDT 1.0 没有什么任务, 封装解封装即可
RDT 2.0: 具有比特差错的信道
下层信道可能会出错: 分组中的比特反转
- 用校验和来检查比特差错
D | EDC - 接收方校验成功回复ACK, 否则回复NAK, 此时需要重传
- 发送方需要保留副本, 以便出错重传
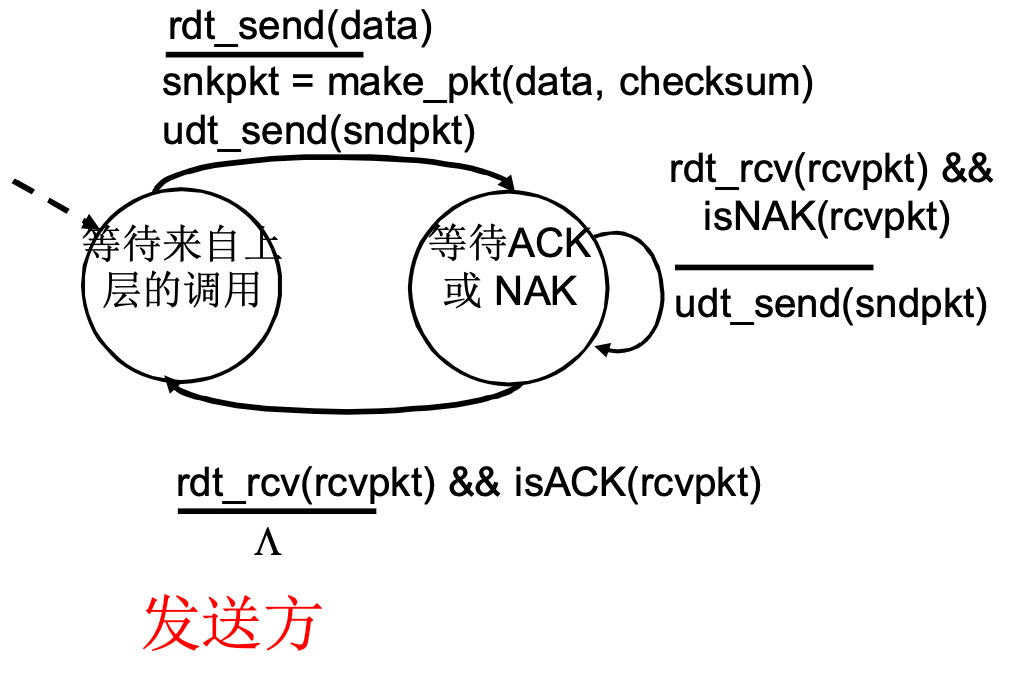
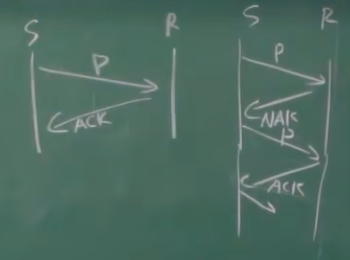
RDT 2.0 -> 2.1: 修复ACK缺陷
RDT 2.0的缺陷: ACK, NAK信息也有出错的可能(听不清)
2.1加入分组序号机制, 并且在ACK/NAK里也引入校验编码
作为发送方:
- ACK/NAK听不清, 重发消息, 直到ACK
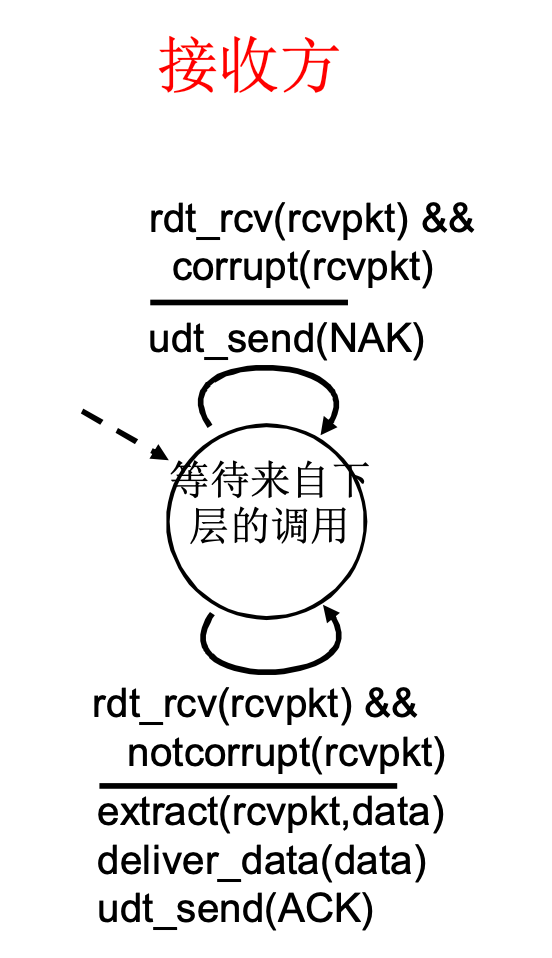
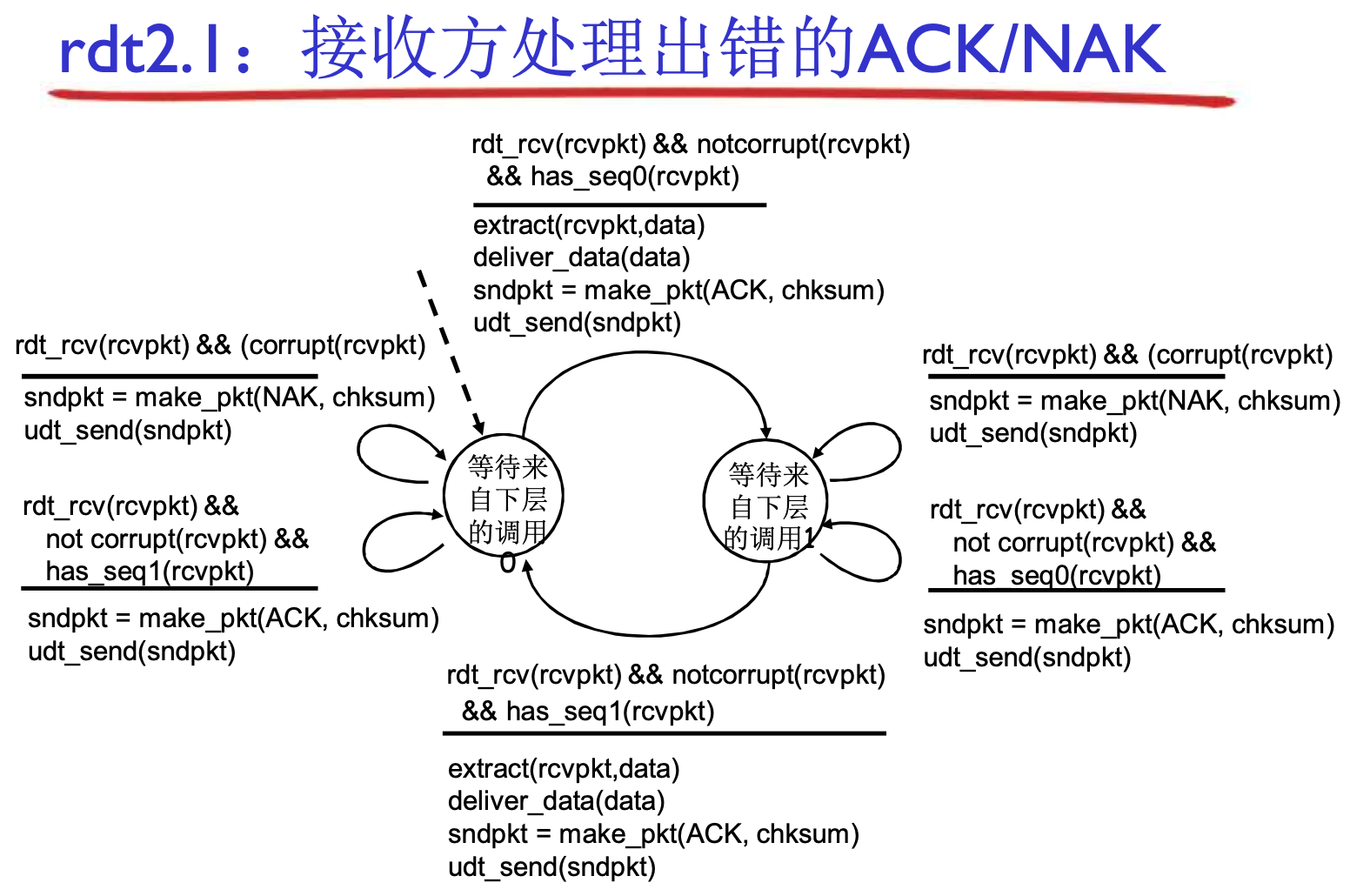
作为接收方:
- 回复NAK, 收到重发消息
- 回复ACK, 收到重发消息? 因为有序号, 所以知道这条没用, 丢弃掉, 继续回复ACK
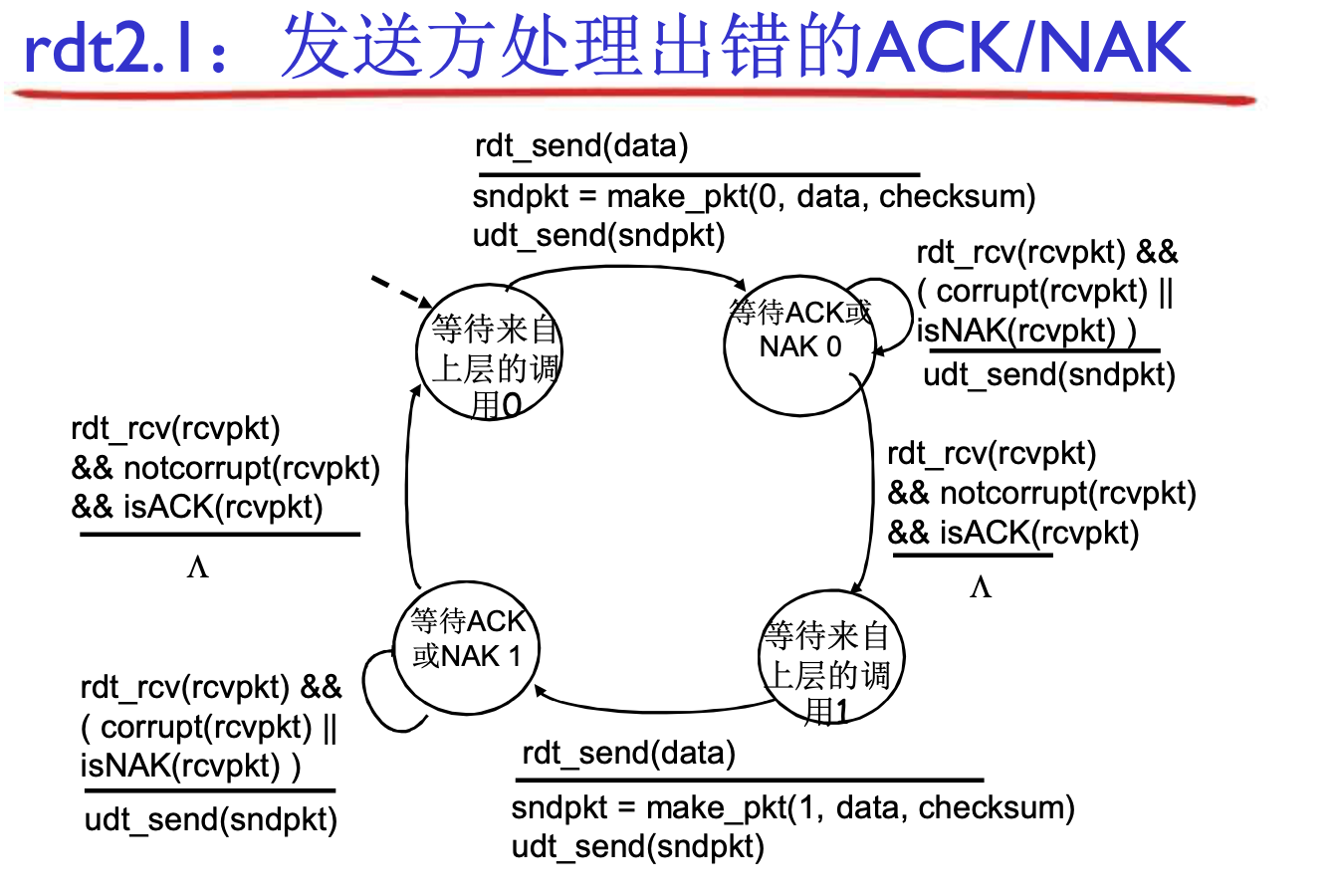
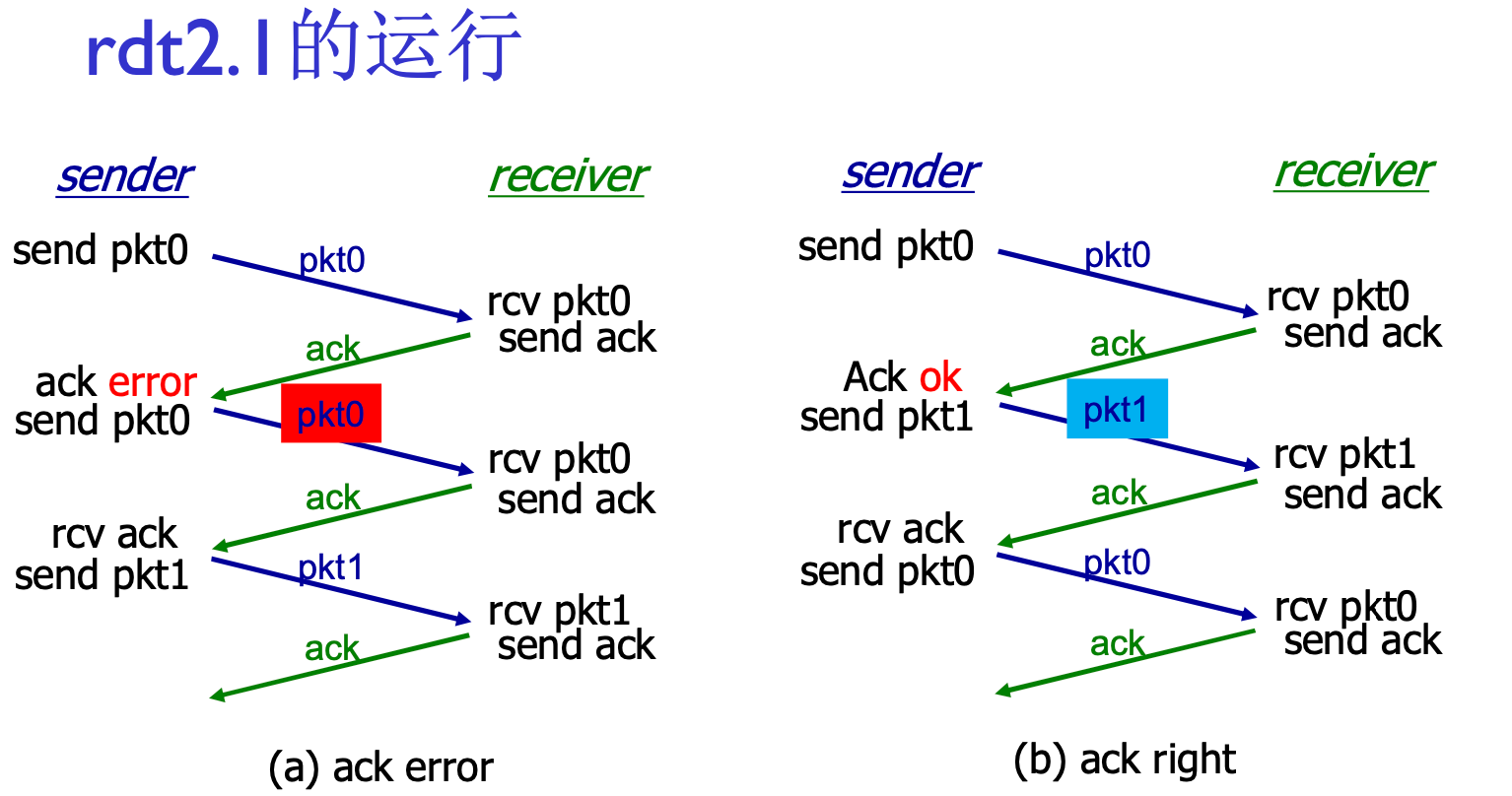
作为发送方, 两个序列号(0, 1)就够用了
RDT 2.2: NAK-free协议
如果每个分组都ACK-NAK太麻烦了
功能同RDT 2.1, 但是只使用带编号的ACK: 作为接收方, 如果第5个分组校验失败了, 发送ACK4也能达到相应的效果
用前一个分组的ACK代替当前分组的NAK, 确认信息减少了一半
这个做法为以后的协议一次发送多个数据单位做了铺垫
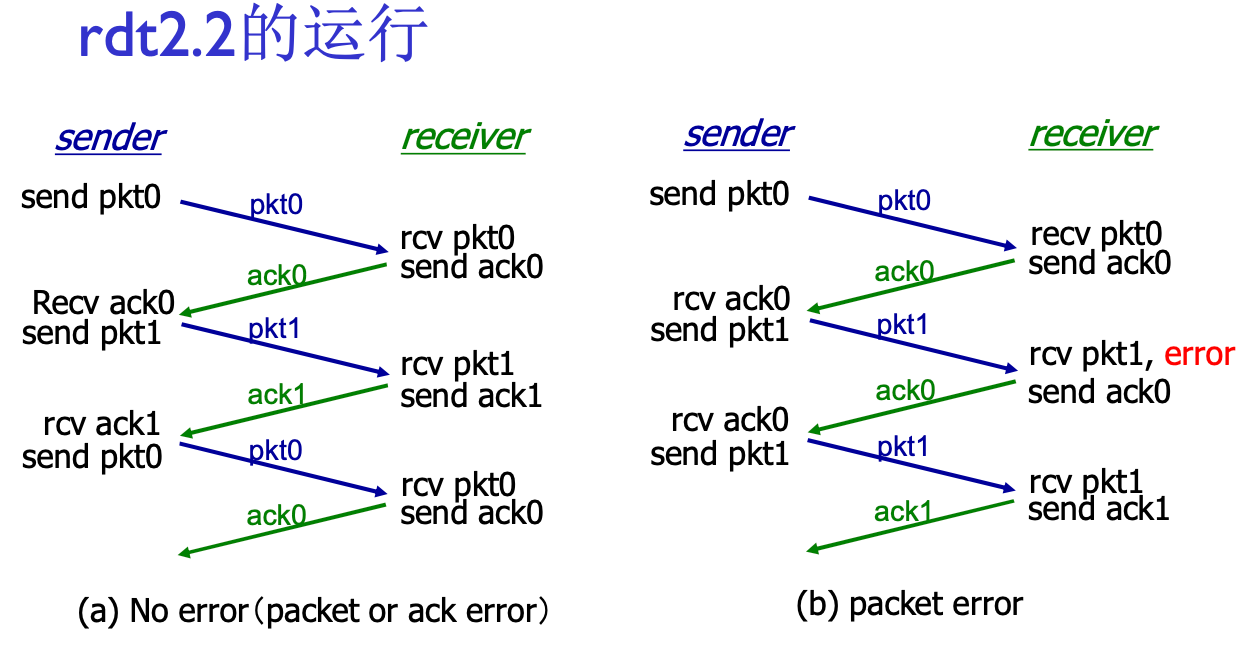
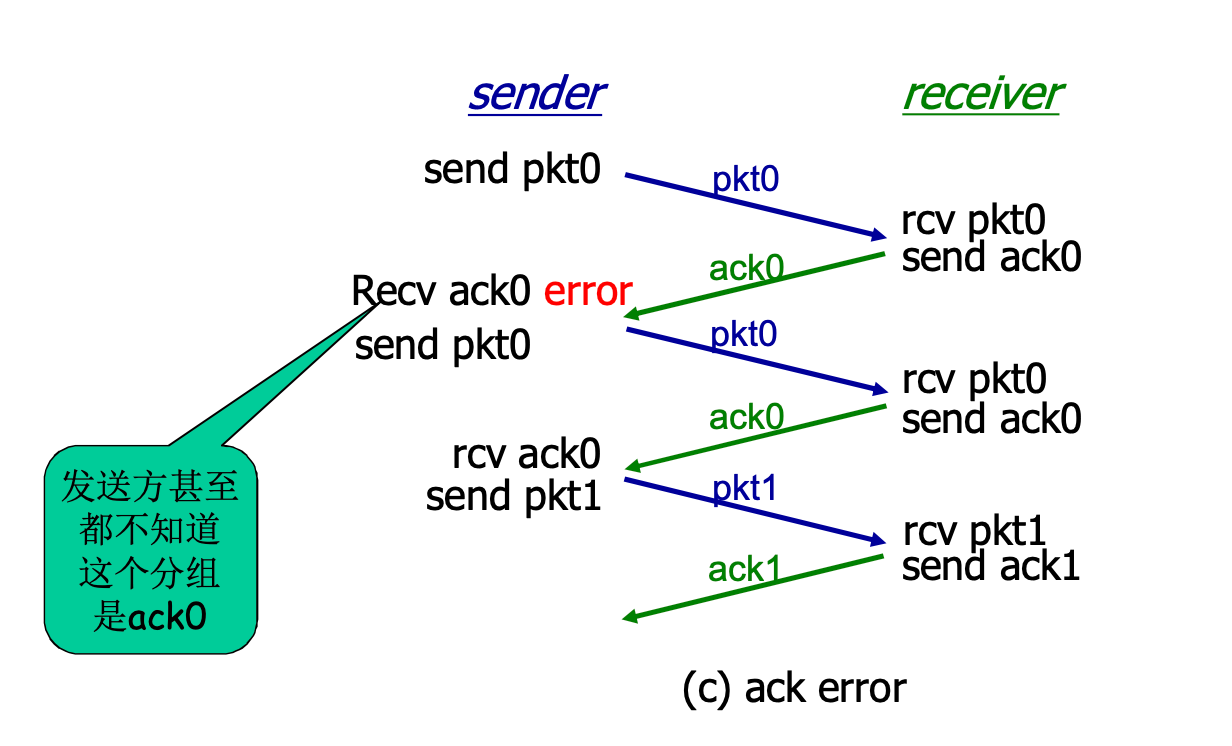
超时重传机制: 发送方发送一个分组后, 一段时间没有收到回复, 则认为丢失, 再发一遍
如果实际上没丢, 发重复了? 没有影响, 分组有序号, 接收方直接丢弃即可
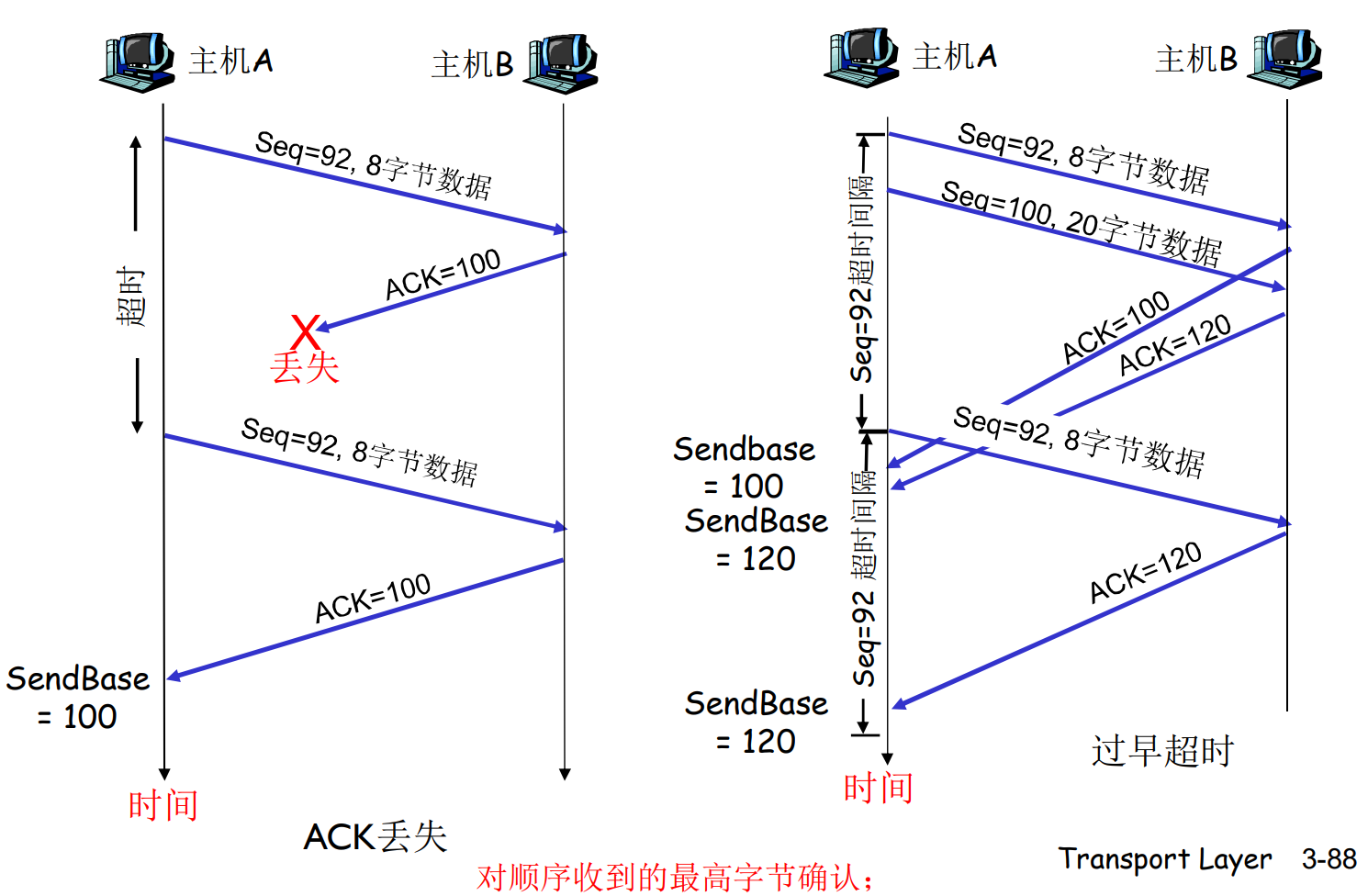
RDT 3.0: 具有比特差错与分组丢失的信道
新的假设: 下层信道可能会反转比特, 或者直接丢失一个分组(数据/ACK), 比如, 路由器缓存队列满了, 后面的分组直接丢掉
RDT 2 面临这种情况会死锁: 两方互相等
此时需要超时重传机制, 时间设置为比正常往返稍多一些即可
在数据链路层, 传输层中, 超时时间算法不一样, 也可以动态计算
- 链路层是静态的, 传输层是动态的
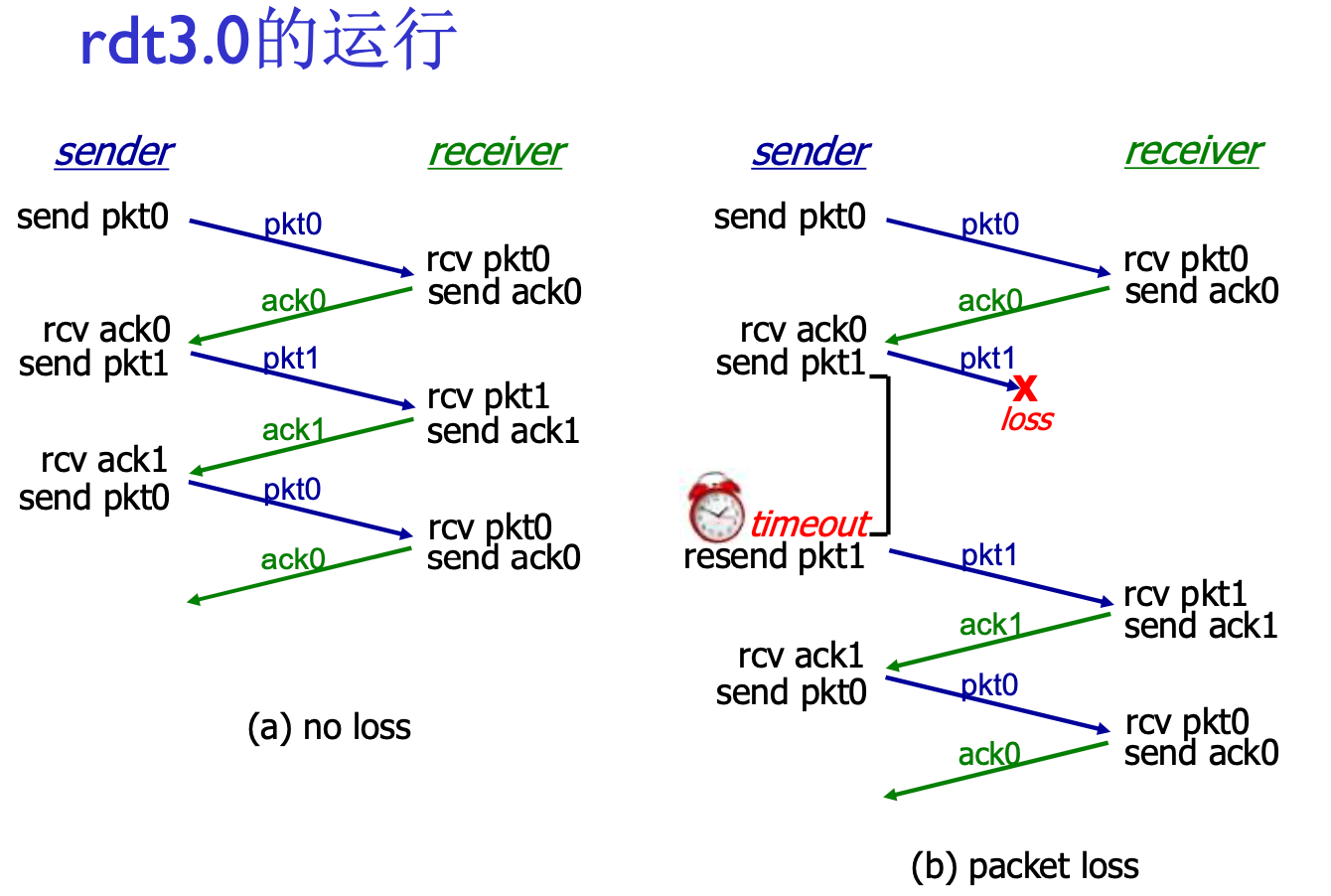
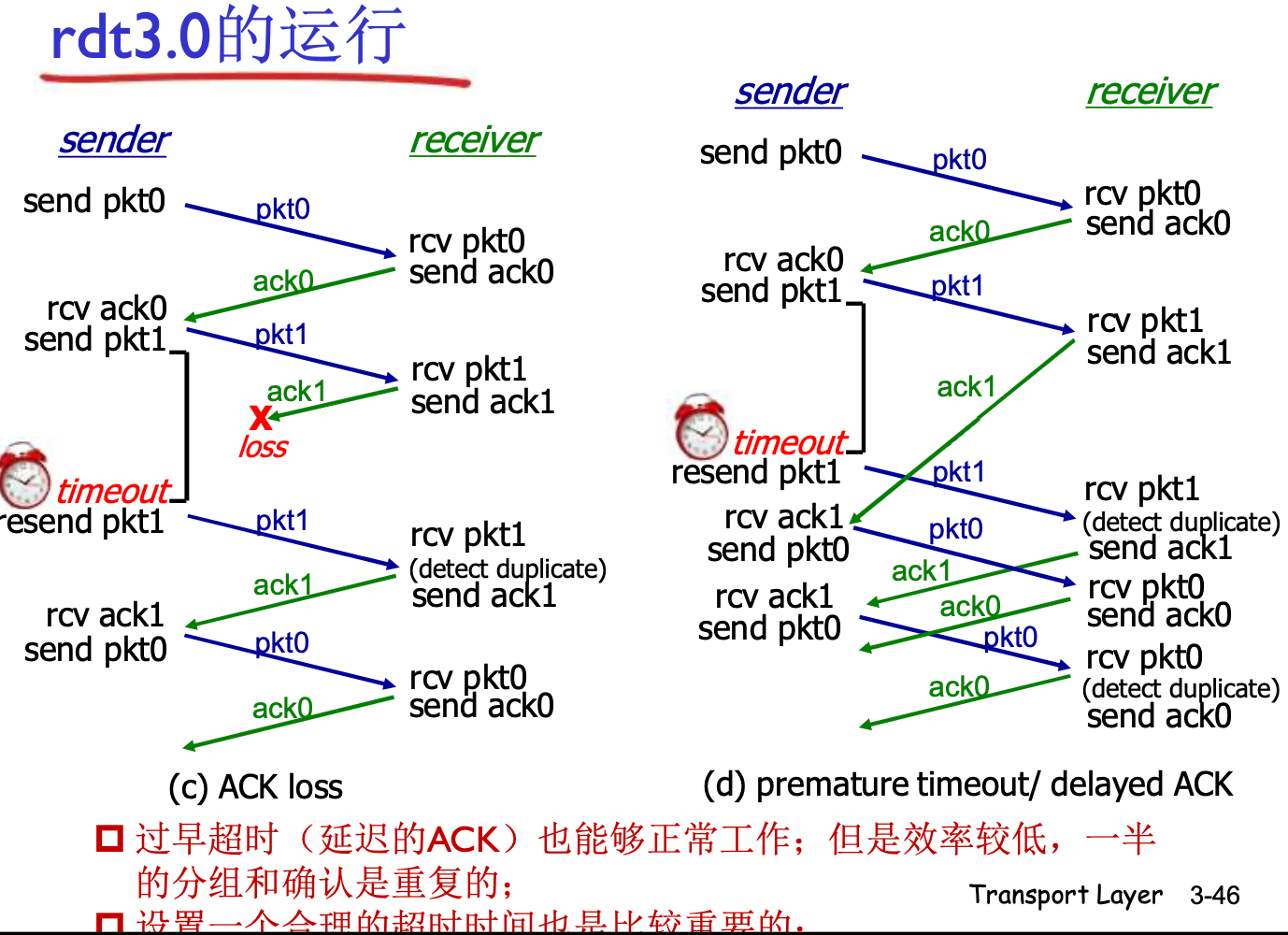
超时定时器的设置很有学问: 一般设置为99.9%丢失的情况
如果不合理(过早超时), 就会造成上面右边的情况: ACK1慢了一点, 造成了不同步工作. 此时仍然可以正常工作, 但是效率收到影响
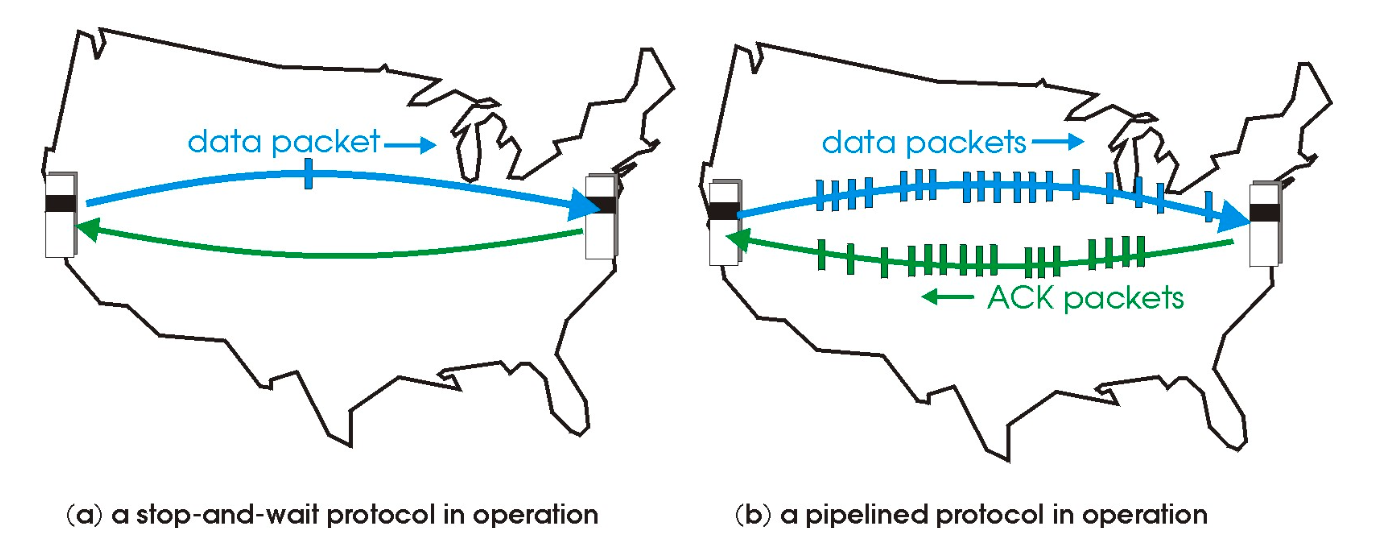
RDT 3.0 是比较完备的协议, 可以应对多种复杂情况, 但是在对信道的利用率过低: 停-等操作
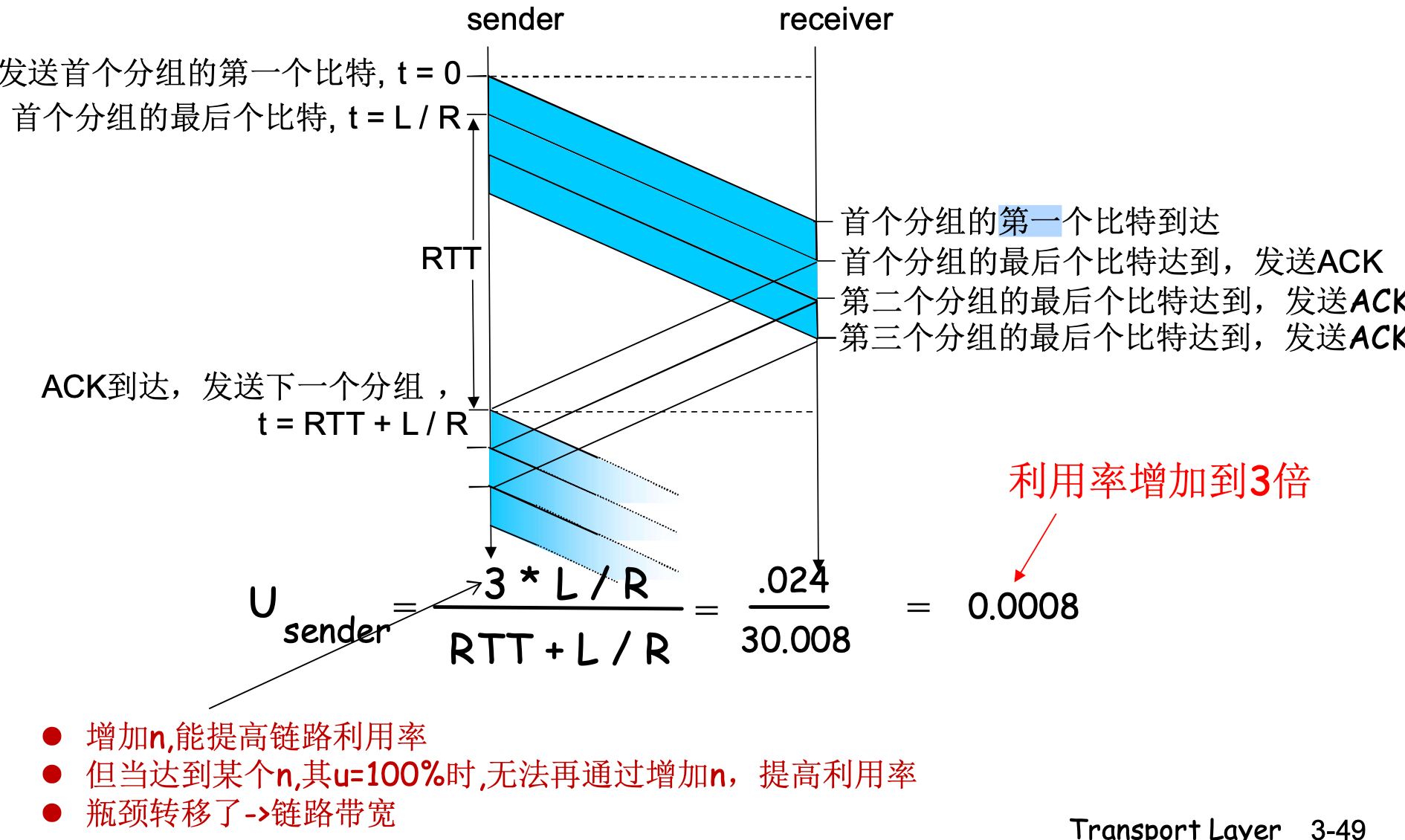
上图中, 发送, 接收方大部分时间都在等待, 吞吐量的瓶颈在协议本身: 一次只能发一个
这种情况经常发生在信道带宽充足, 距离遥远的情况下
流水线协议
允许发送方在未经确认的前提下一次发送多个分组, 提高信道利用率
- 必须增加序号范围: 用多个bit表示分组序号
- 发送方/接收方需要有缓冲区
- 发送方缓冲: 没有得到确认, 需要重传
- 接收方缓冲: 匹配上层取用数据速度, 处理乱序问题
有两种通用的流水线协议:
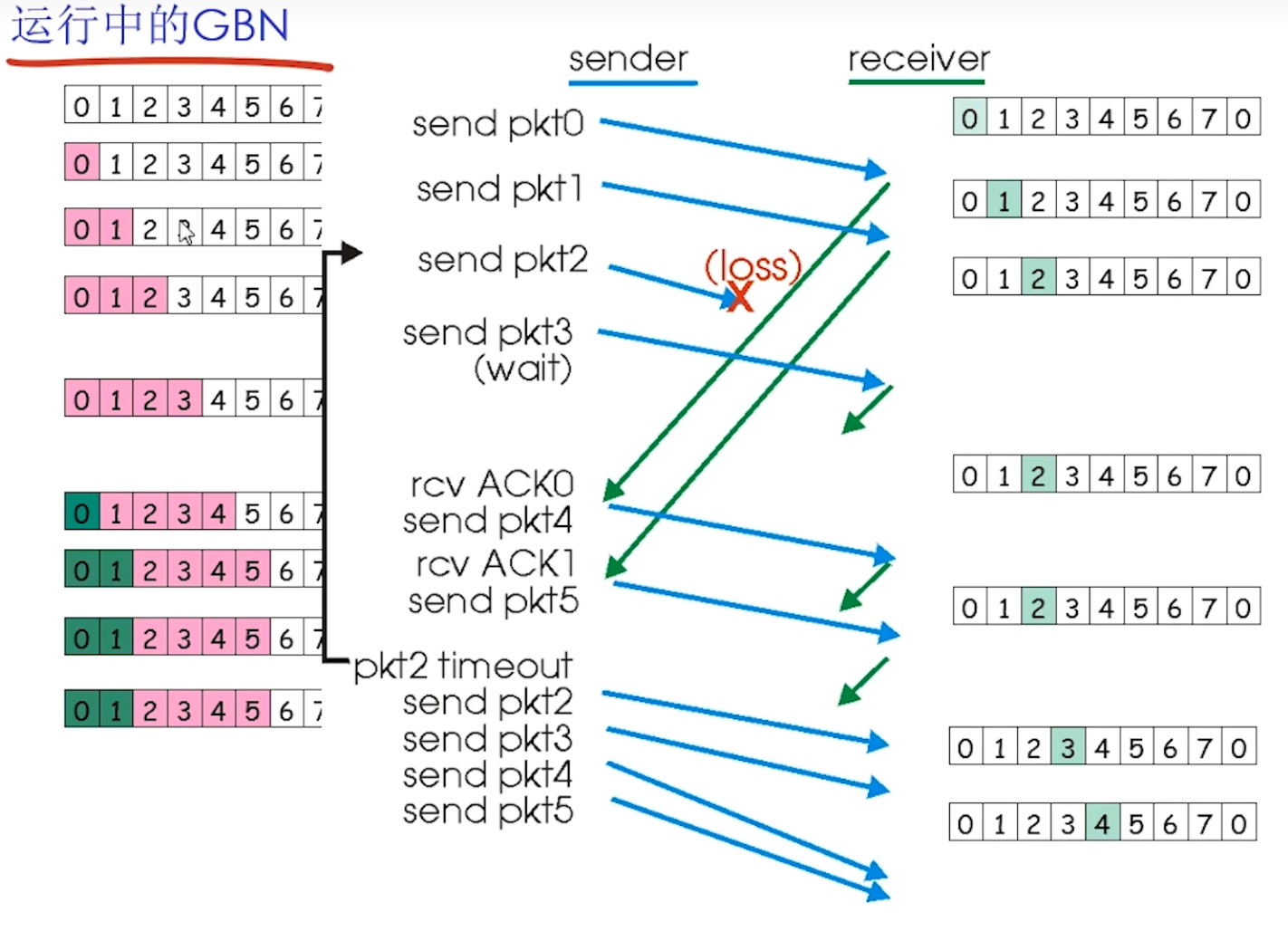
- 回退N步(GBN)
- 选择重传(SR)
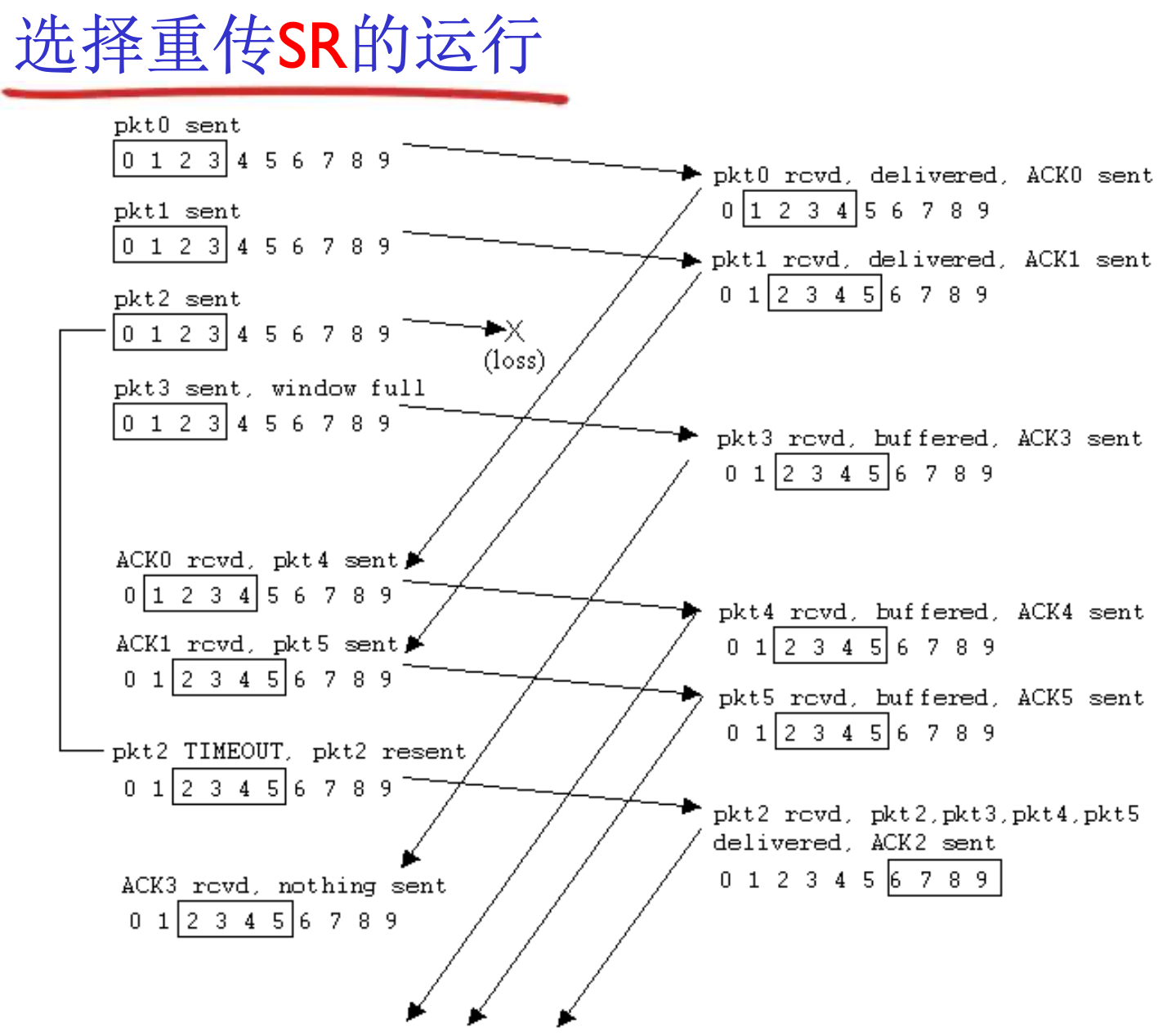
滑动窗口(Sliding window)协议
当S方window=1, R方window=1时, 退化为了停止等待协议(Stop & Wait), RDT 3.0就是这样的协议
当S方window>1, R方window=1时, 是GBN协议
当S方window>1, R方window>1时, 是SR协议
GBN, SR都是流水线协议
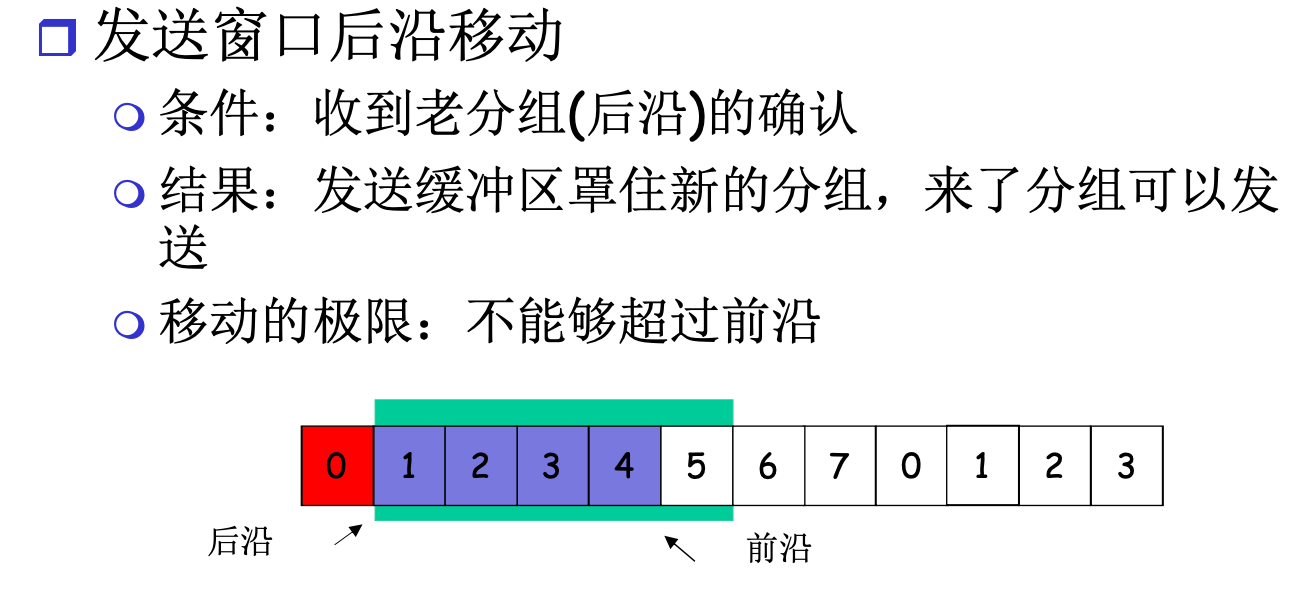
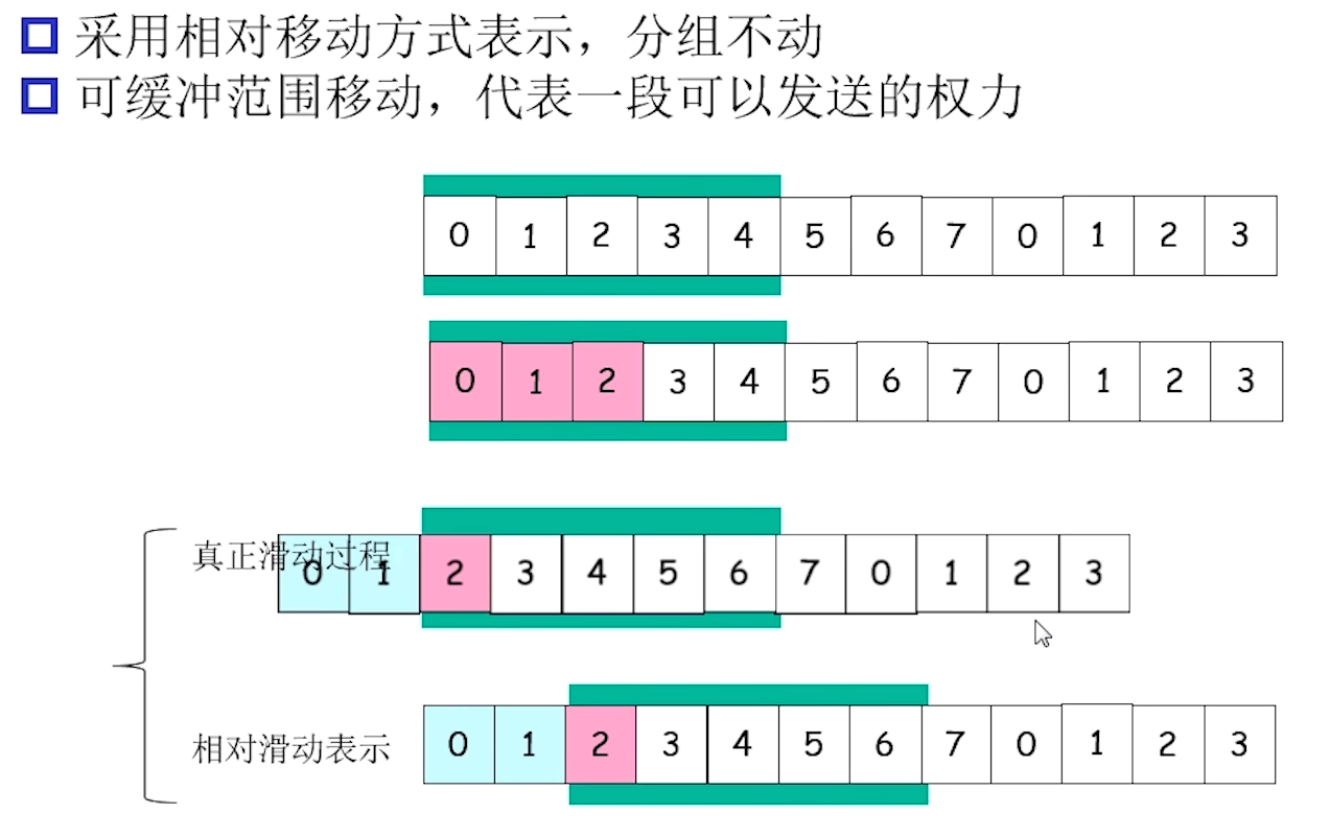
发送缓冲区: 内存中的一个区域, 存储即将发送的分组, 和没有ACK的分组

接收窗口: 接收缓冲区, 表示正在等待接收的分组
- size = 1, 不能乱序, GBN
- size > 1, 可以乱序, SR
落在窗口内的编号的分组会回复ACK, 而落在接收窗口外的编号的分组会被抛弃掉, 并回复当前收到顺序到来的, 最高分组的确认
假设size=2, 已经收到了1, 正在等待2, 3, 此时收到了5, 5会被抛弃掉, 并回复ack=1
当低序号被ACK后, 窗口会滑动
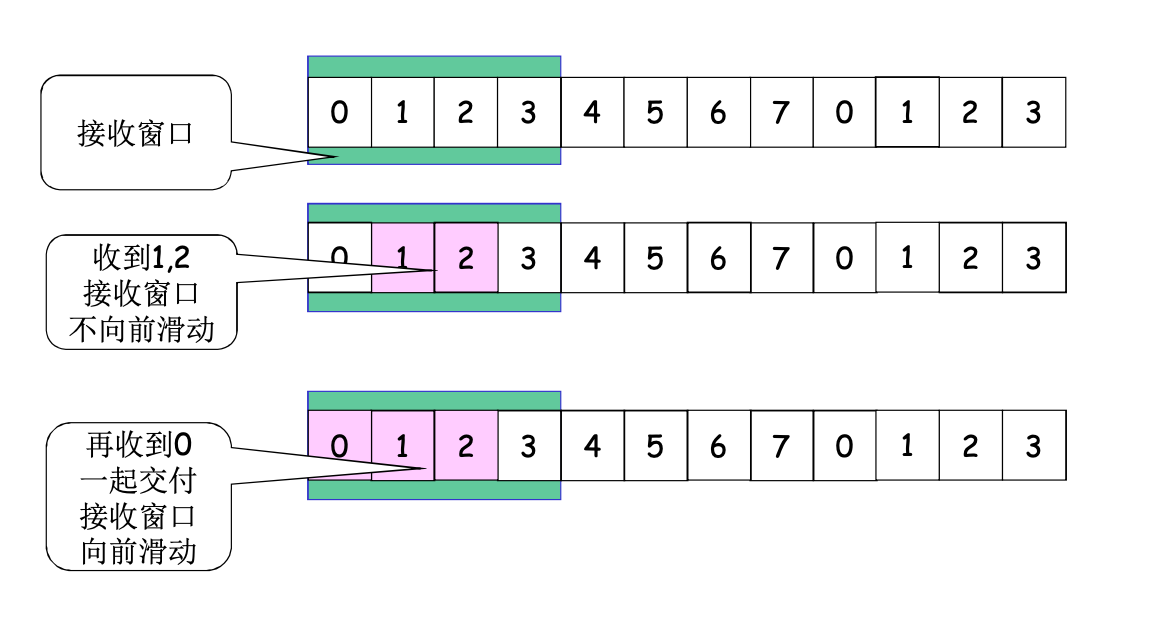
SR的确认不具备累计确认的含义, 而是独立确认, 即, ACK=3只代表确认3, 不明确1, 2两个分组的状态
相对的, GBN的确认具备累计含义



3.5 面向连接的传输: TCP
TCP概述
点对点: 一个发送方, 一个接收方
可靠的, 保序的字节流: 没有报文边界
管道化(流水线): TCP拥塞控制和流量控制管理窗口大小
发送和接收缓存
全双工数据: 一个连接双向流动, MSS: 最大报文段
面向连接: 正式通信前, 要握手, 维持状态
流量控制: 发送方不会淹没接收方
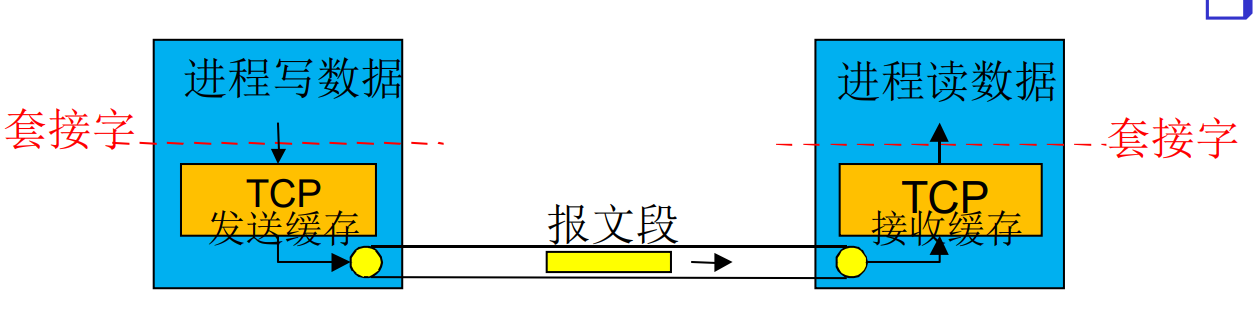
在应用层发送方, 各个应用程序有自己的协议, 以各种格式封装数据, 然后发送给TCP套接字. 穿过套接字后, 统一被当作字节流看待
TCP长长的字节流来自于套接字, 在发送时会切成size<=MSS的报文段, 装上TCP头部发送出去
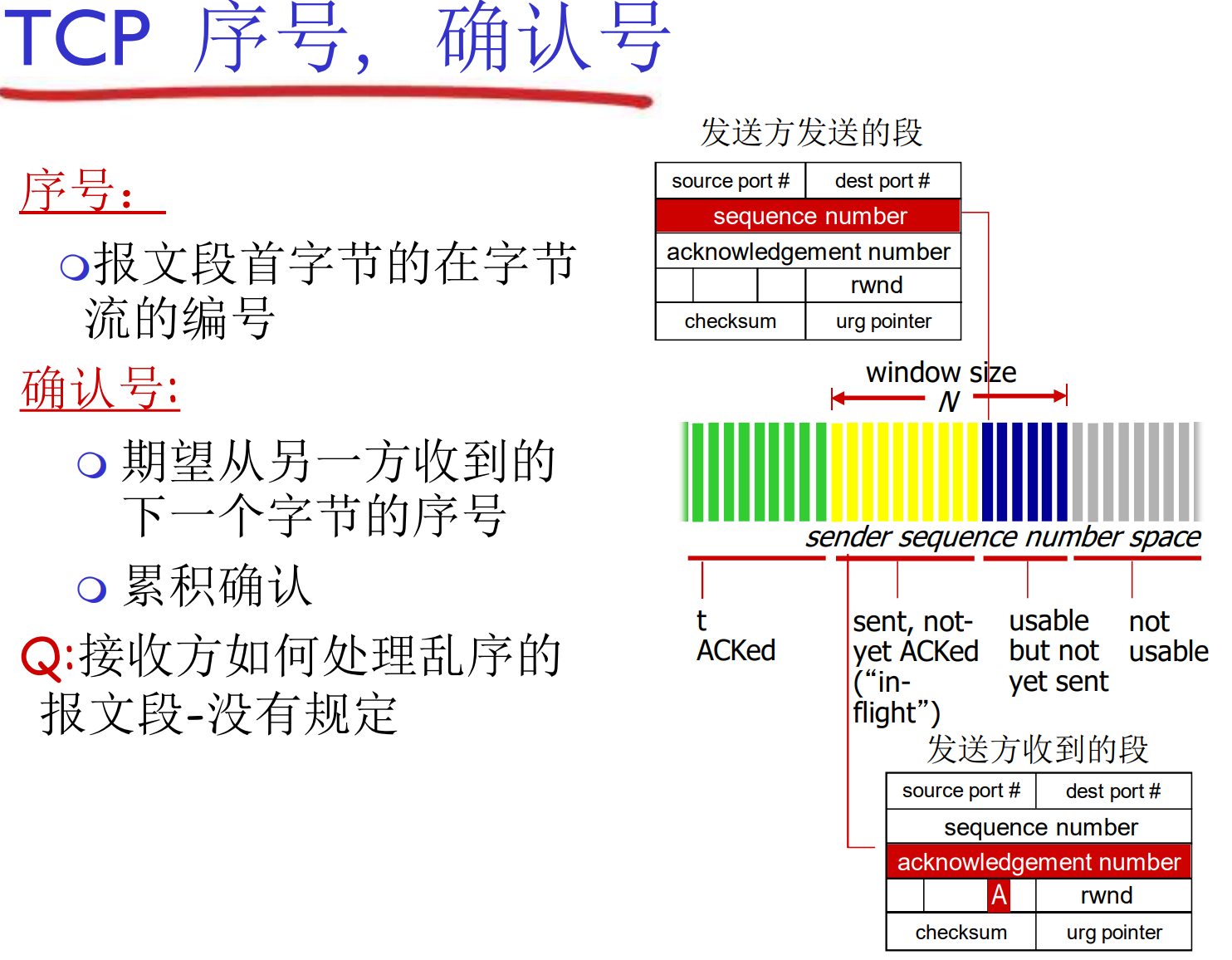
TCP报文结构
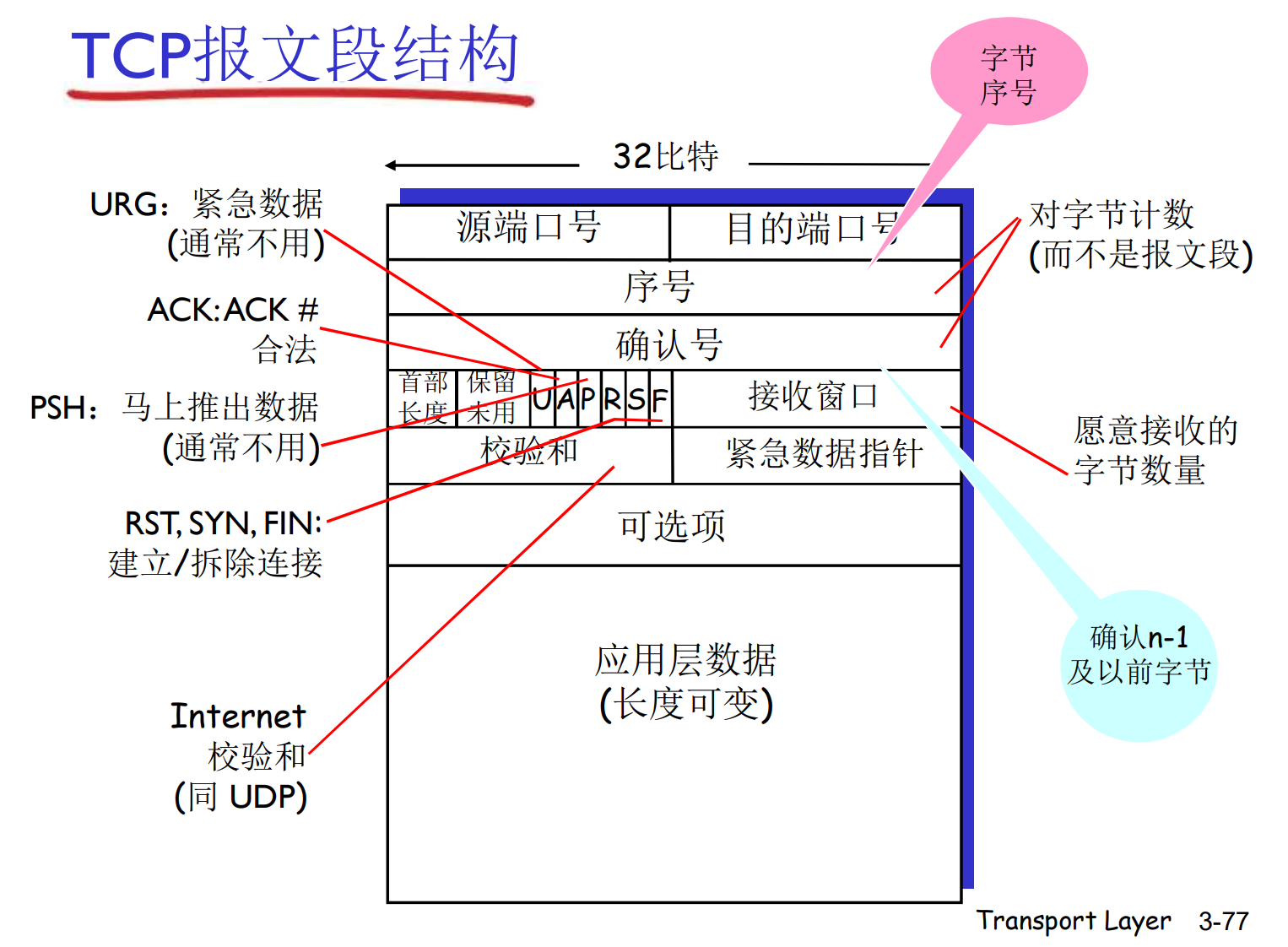
上面的序号是以字节为编号的序号, 是这个报文段的第一个字节在整个字节流中的偏移量
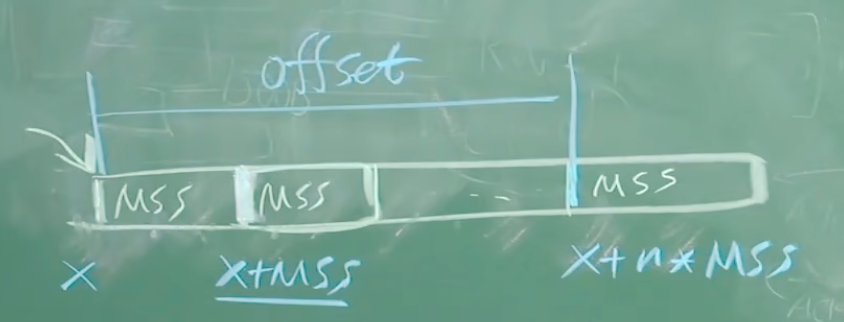
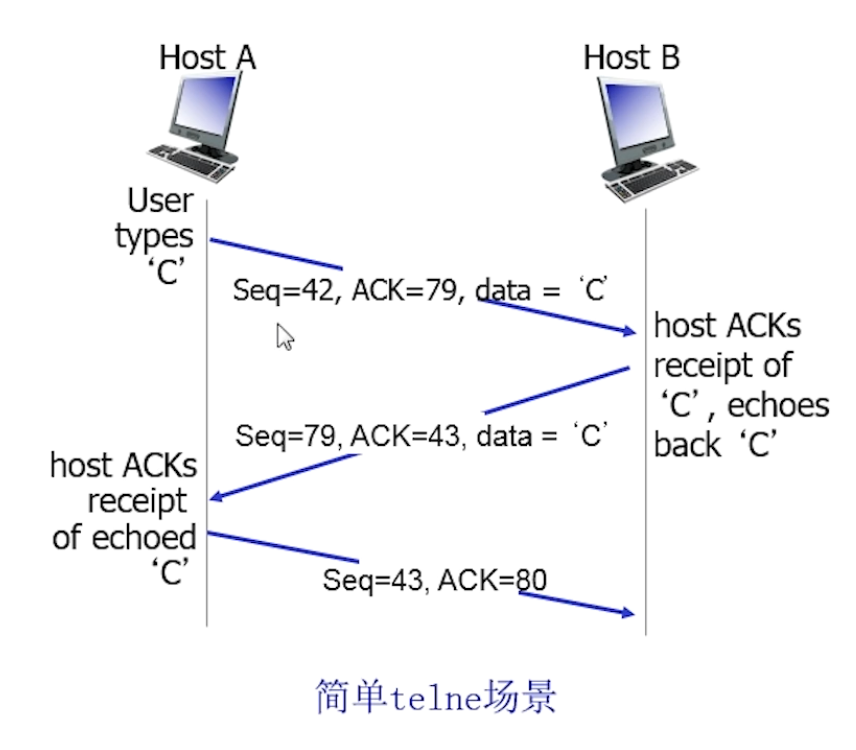
这是因为TCP是面向字节流的协议, 而不是面向报文段的协议. 起始字节序号x通常是随机的, 这有助于防止旧的TCP连接干扰
在TCP中, ACK是累积确认, ACK=555表示接收到了554及以前的全部数据, 表示期待, 同样的是对字节的计数, 而不是报文段
TCP的超时时间是自适应的
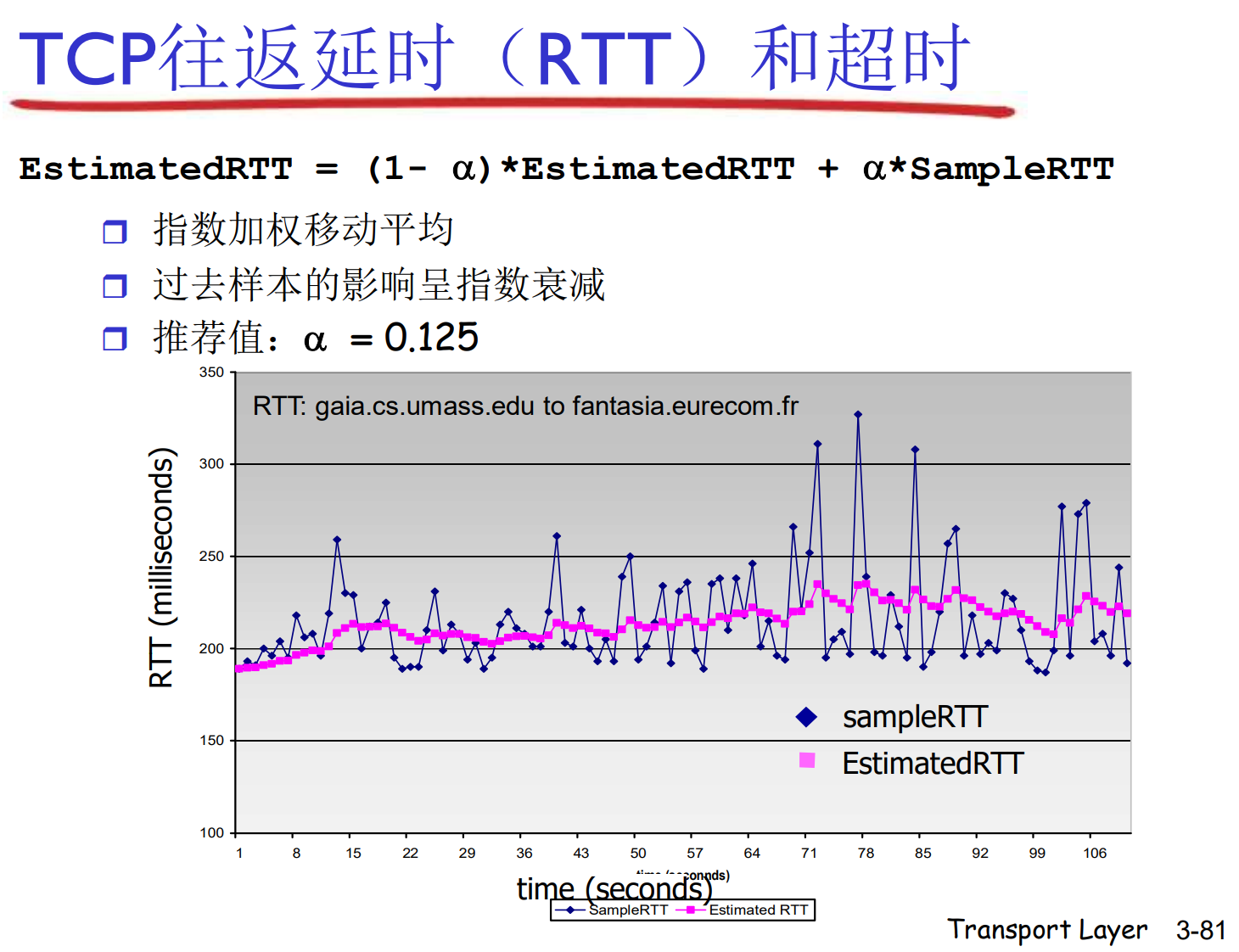
TCP的往返延时(RTT)和超时
TCP面临的实际通讯环境很复杂, RTT可能时高时低: 需要测量RTT
TCP: 可靠数据传输
TCP使用管道化的报文段
- 类似GBN/SR, 一次发多组
TCP使用累计确认ACK
- 类似GBN, 但TCP的ACK表示期望
TCP使用单个重传定时器
- 类似GBN, 每个窗口有一个定时器, 超时全部重发
TCP不规定乱序处理
- 在实际情况中, 经常类似SR, 有接收窗口
名词解释:
cwnd(Congestion Window), 拥塞窗口
rwnd(Receiver Window), 接收窗口
TCP发送方事件
定时器和最早未确认的报文段关联
超时重传: 如果超时, 重传最老报文段, 即窗口内的第一个报文段, 重新启动定时器
收到确认: 更新确认序号, 如果还有未确认的报文段, 重新启动定时器
三个相同ACK, 立即重传要求的单个报文段
TCP接收方事件
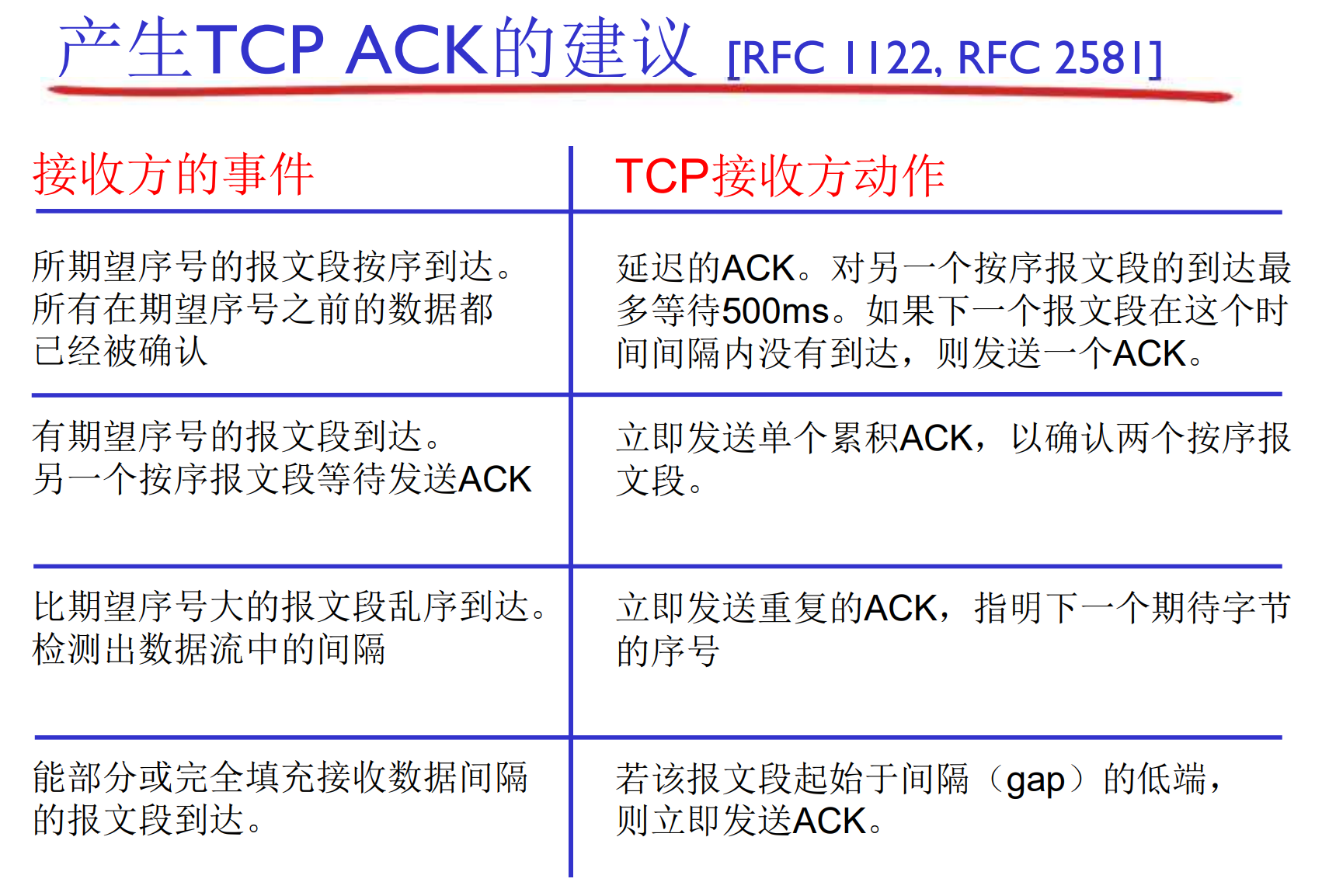
正常情况下, 有隐忍不发的规则, 尽量减少对发送方的干扰: 辅助计时器
TCP流量控制
接收方控制发送方, 不让发送方一次发送太多, 太快, 以至于让接收方自己的缓冲区溢出
接收方在回复消息时, 在TCP报文头部中的rwnd字段通告自己空闲的buffer大小
- RcvBuffer通过socket选项设置, 经典大小为4096字节
- OS有时会自动调整RcvBuffer
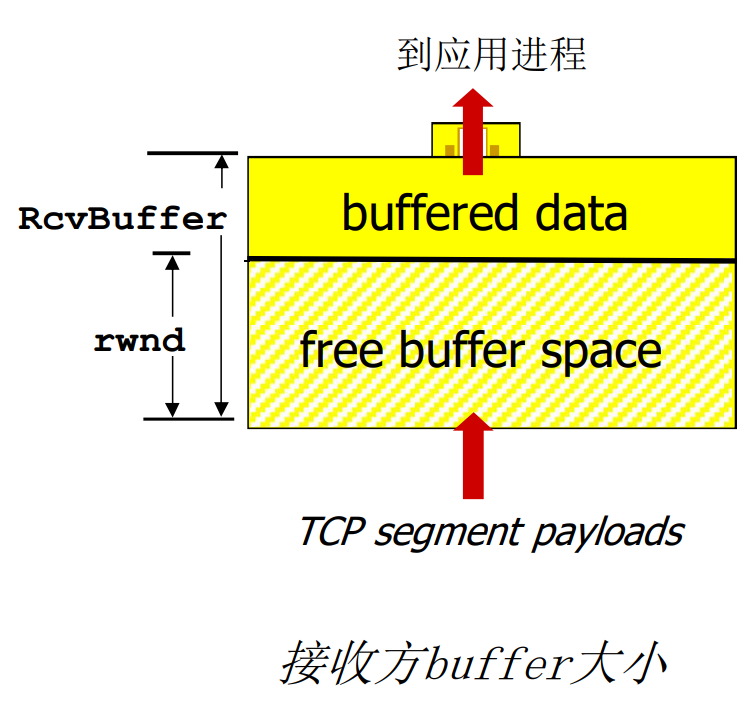
当接收方丢弃乱序报文的时候: RcvWindow = RcvBuffer – [LastByteRcvd – LastByteRead]
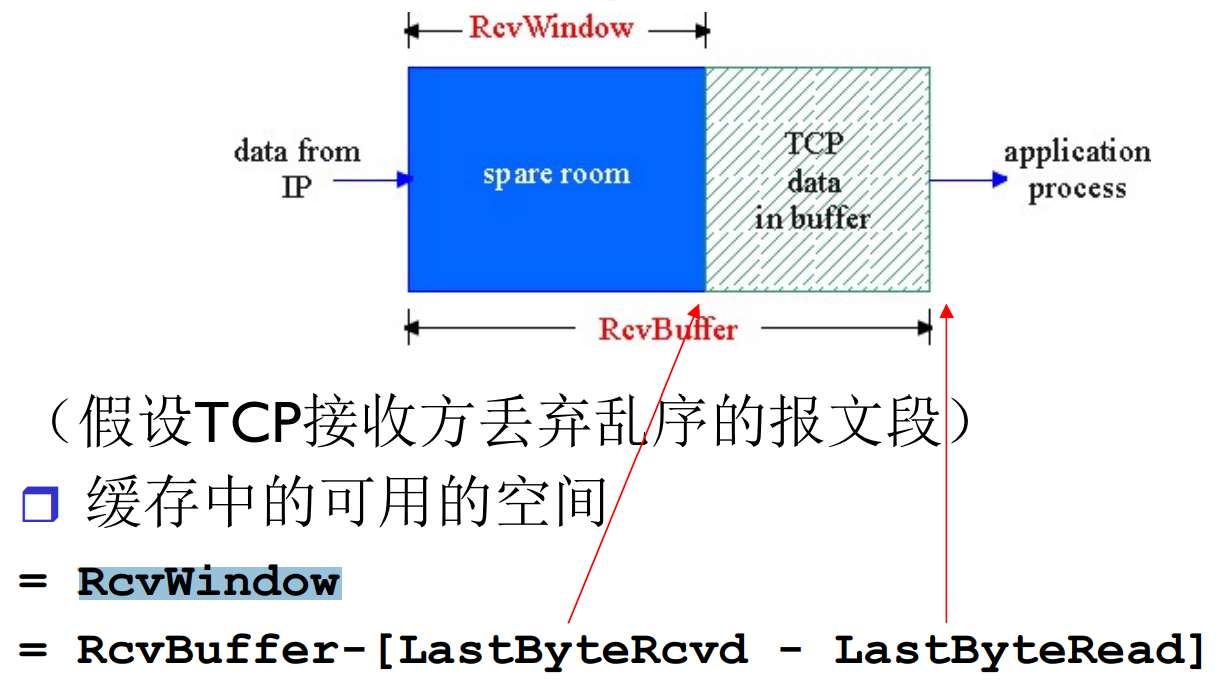
- TCP data in buffer是应用没来得及读读数据
捎带技术(Piggybacking): 在全双工通讯中效果最佳, 即, 两个对等体相互收发消息, 此时ACK和Data冗余程度很大, 可以将ACK和要发送的Data放在一起发送, 节省性能
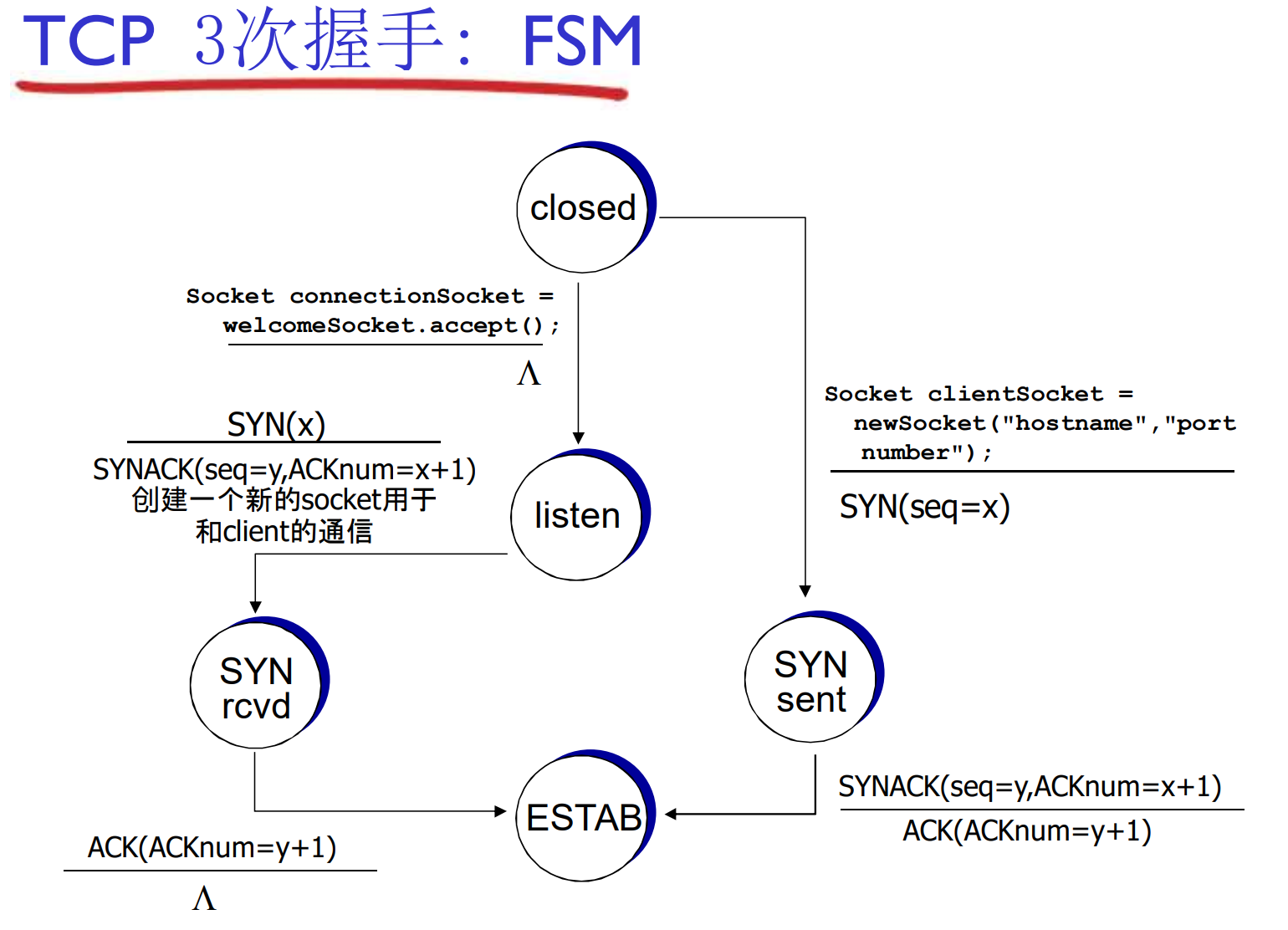
TCP连接管理: 3次握手
在正式交换数据之前, 发送方和接收方握手建立通信关系
- 双方同意连接
- 约定连接参数: 缓冲区, 双方初始字节编号
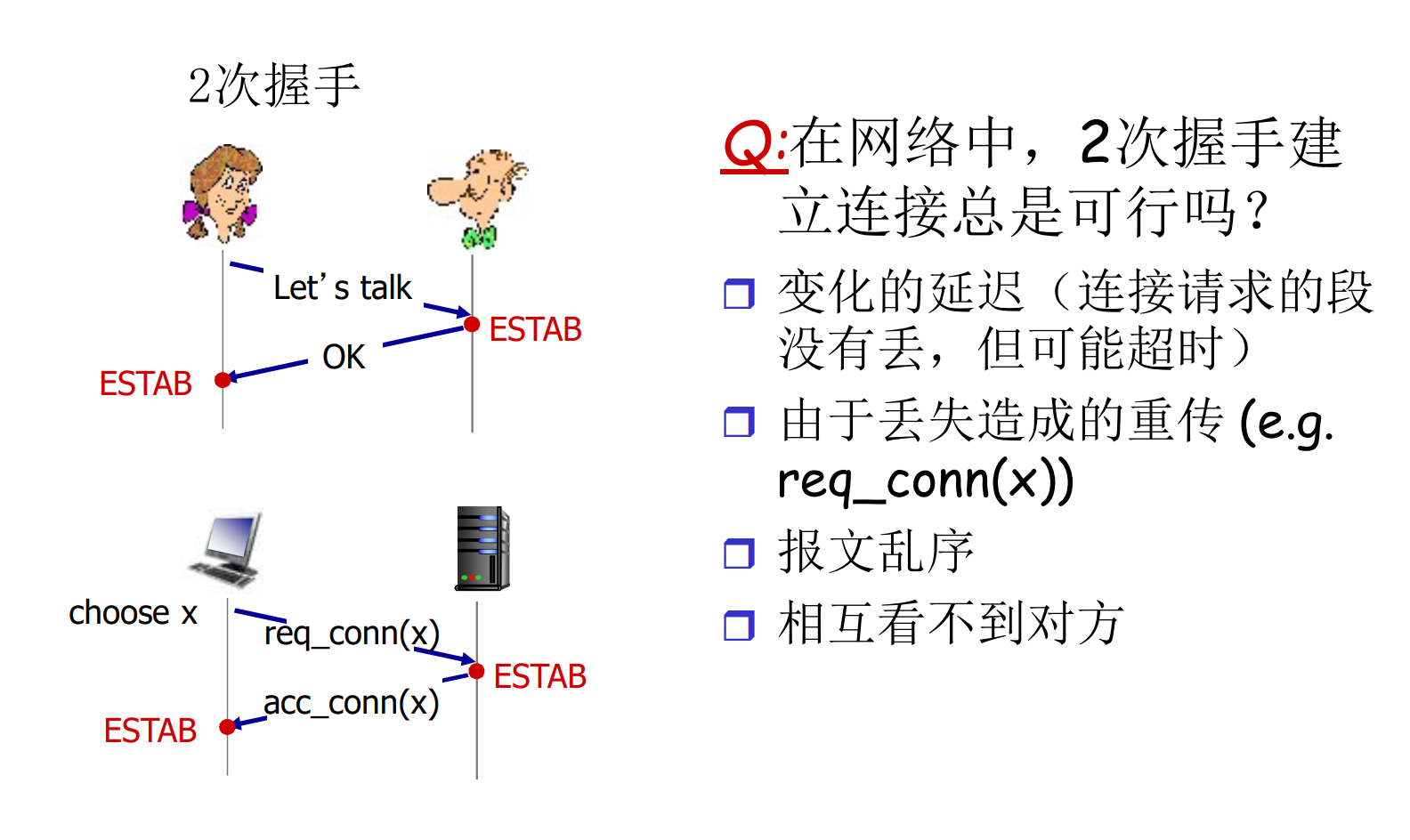
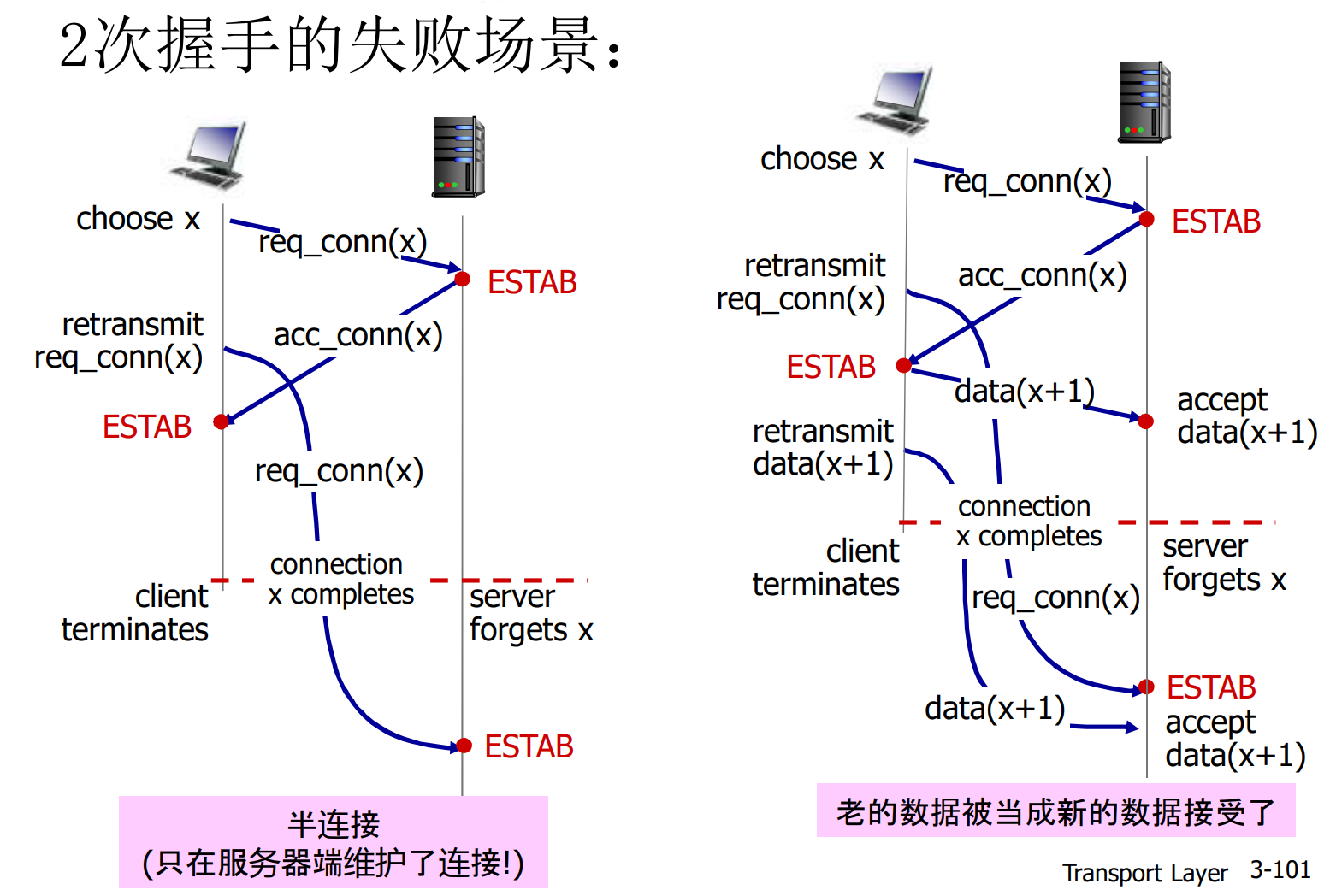
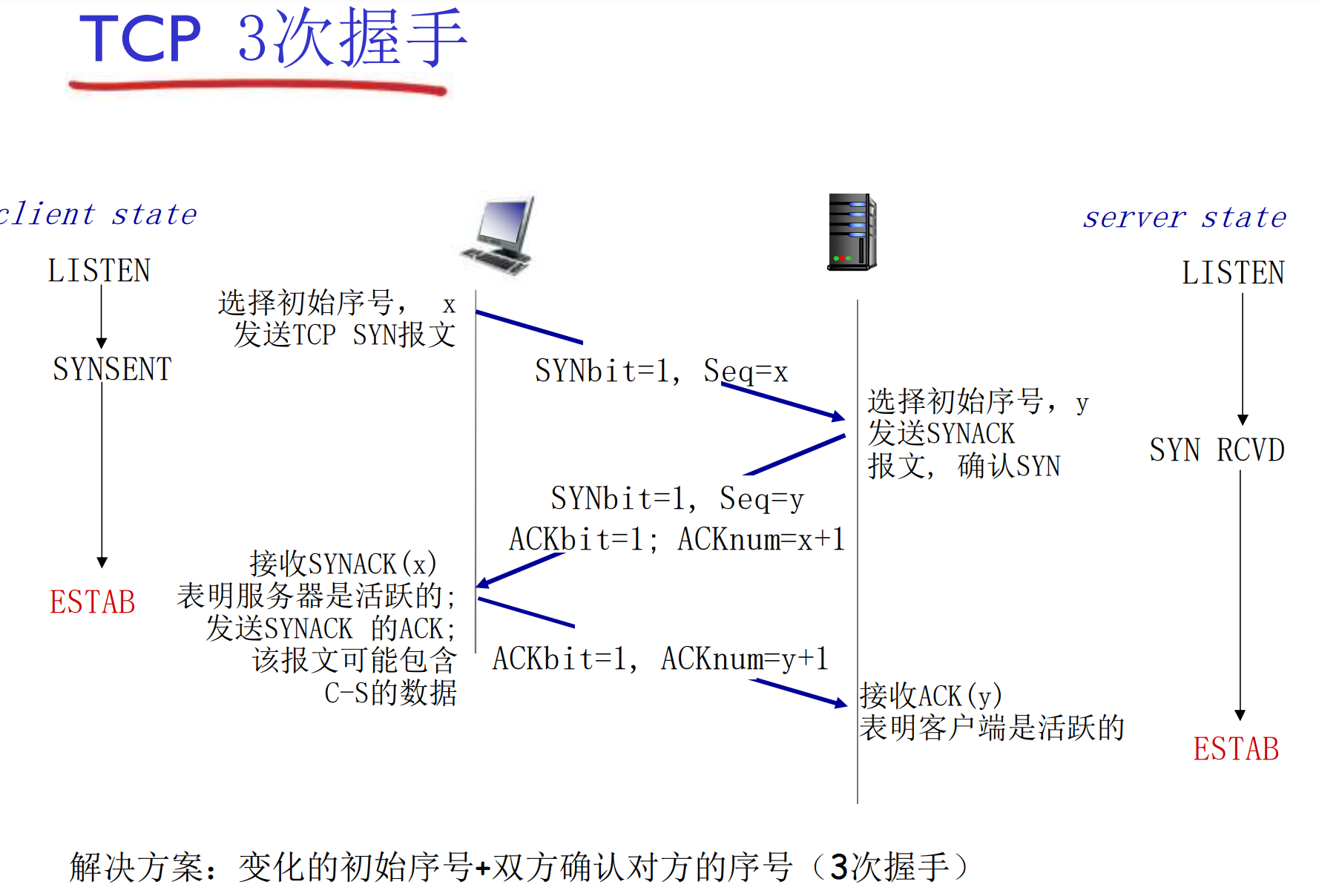
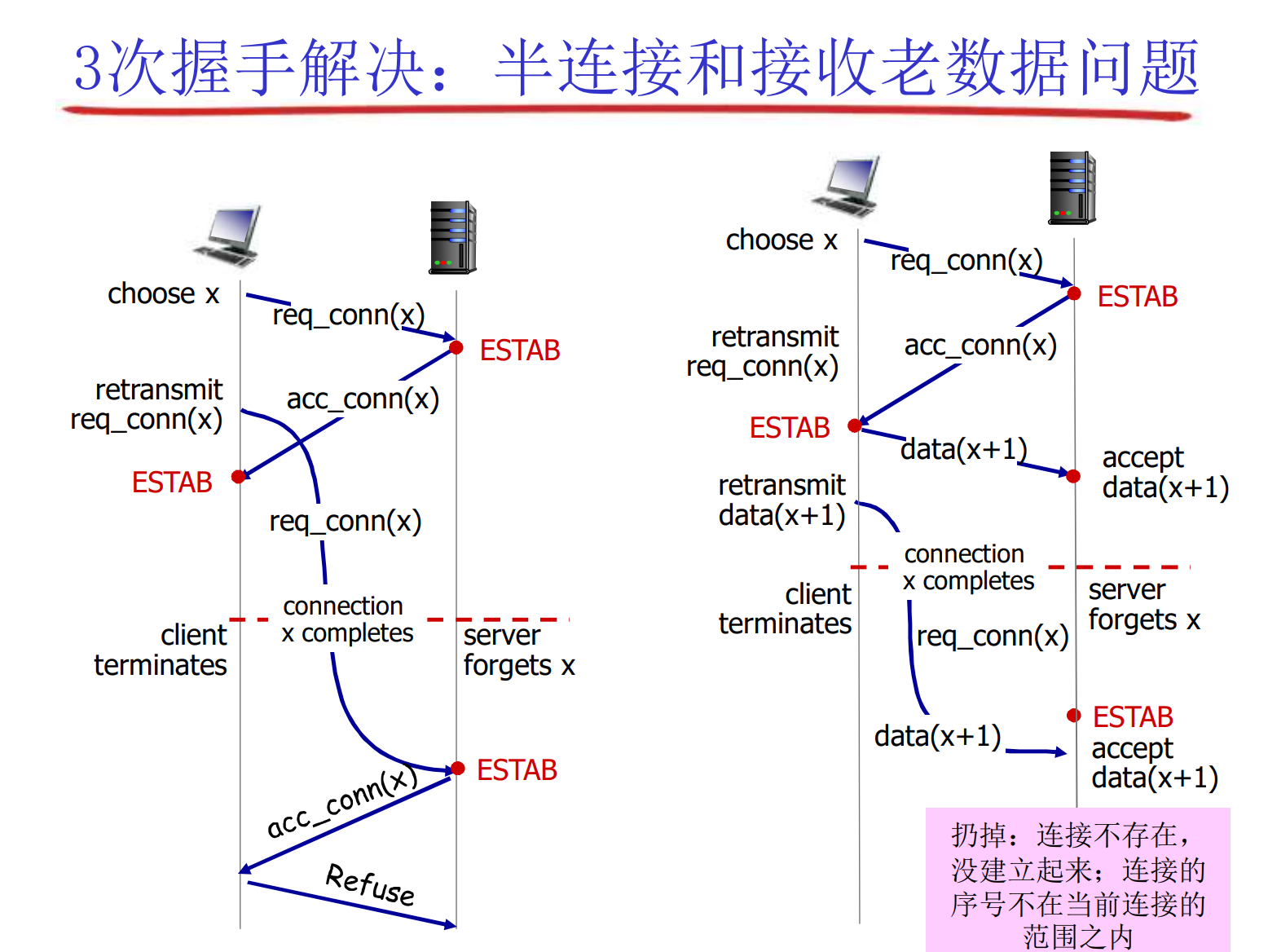
随机初始序号x, y的作用: 假设客户端用555端口与Web服务器的80端口连接, 正常通讯期间, 客户端重发了一个分组P, 分组P因为网络原因滞留在路上, 很久都没有到达, 后来连接被关闭
很久之后, 客户端重新用555端口与Web服务器的80端口连接, 连接建立后, 分组P姗姗来迟, 此时服务器有可能误以为P是当前连接的数据(实际上是老连接的无效数据)
有了x, y, 我们就可以识别分组P是否是当前连接的数据
TCP连接的拆除(不完美的四次握手原则)
实际上是两个半连接的分别拆除, 但有可能会出现一方维持半连接的情况: 最后一次通讯总是不可靠的
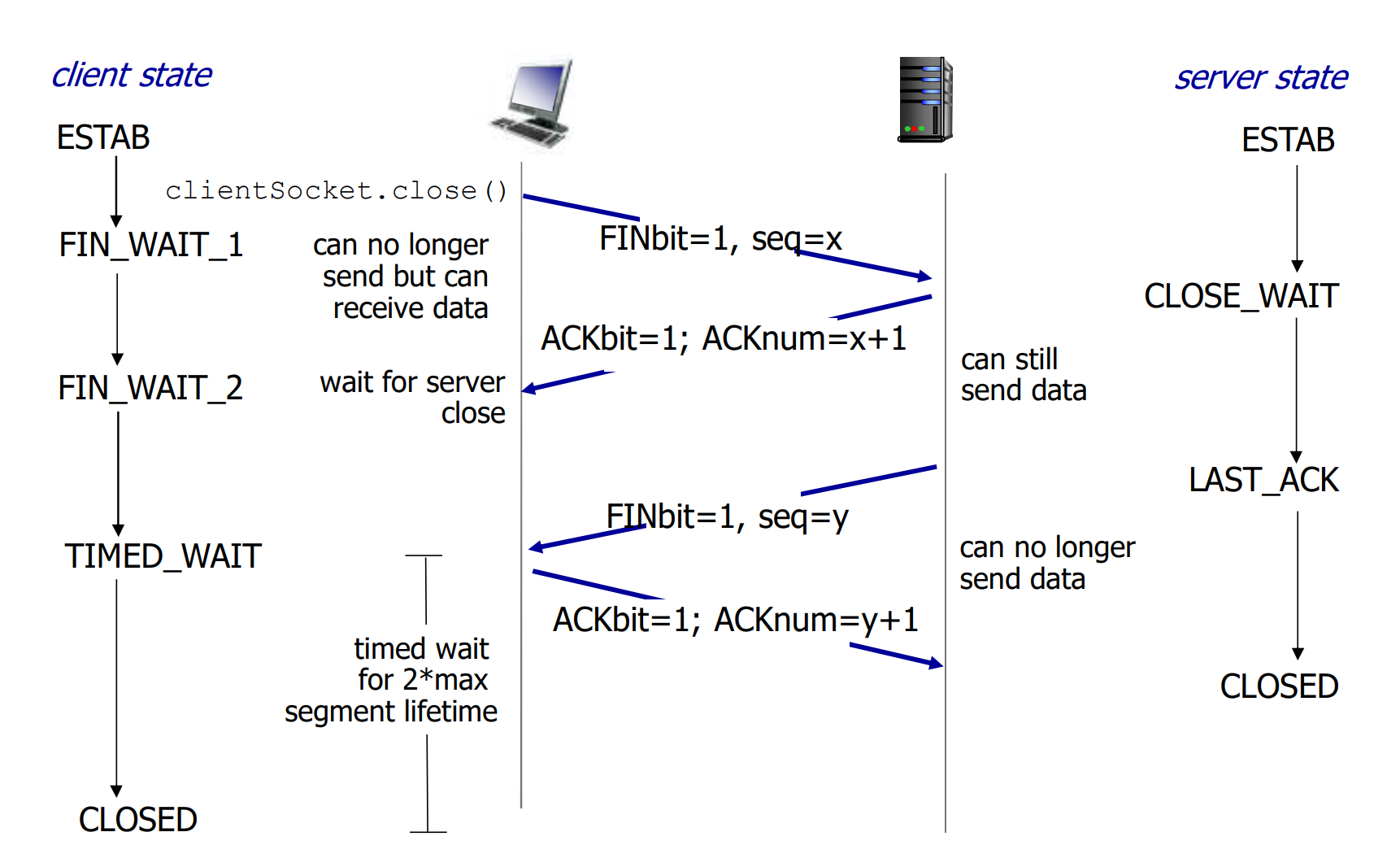
主动方的最后一次ACK发送后, 有可能丢失了, 但是自己无法知道, 关闭了连接. 此时被动方会触发超时重传FIN, 多次重传失败后, 才会关闭连接
3.6 拥塞控制原理
太多的数据需要传输, 超过了网络的承载能力
- 流量控制是发送方和接收方的协调
- 拥塞控制是发送方和网络的协调
拥塞控制也是网络TOP10问题, 拥塞的主要原因和表现有
- 网络带宽瓶颈: 延时无限增大
- 路由器缓冲区溢出: 丢包

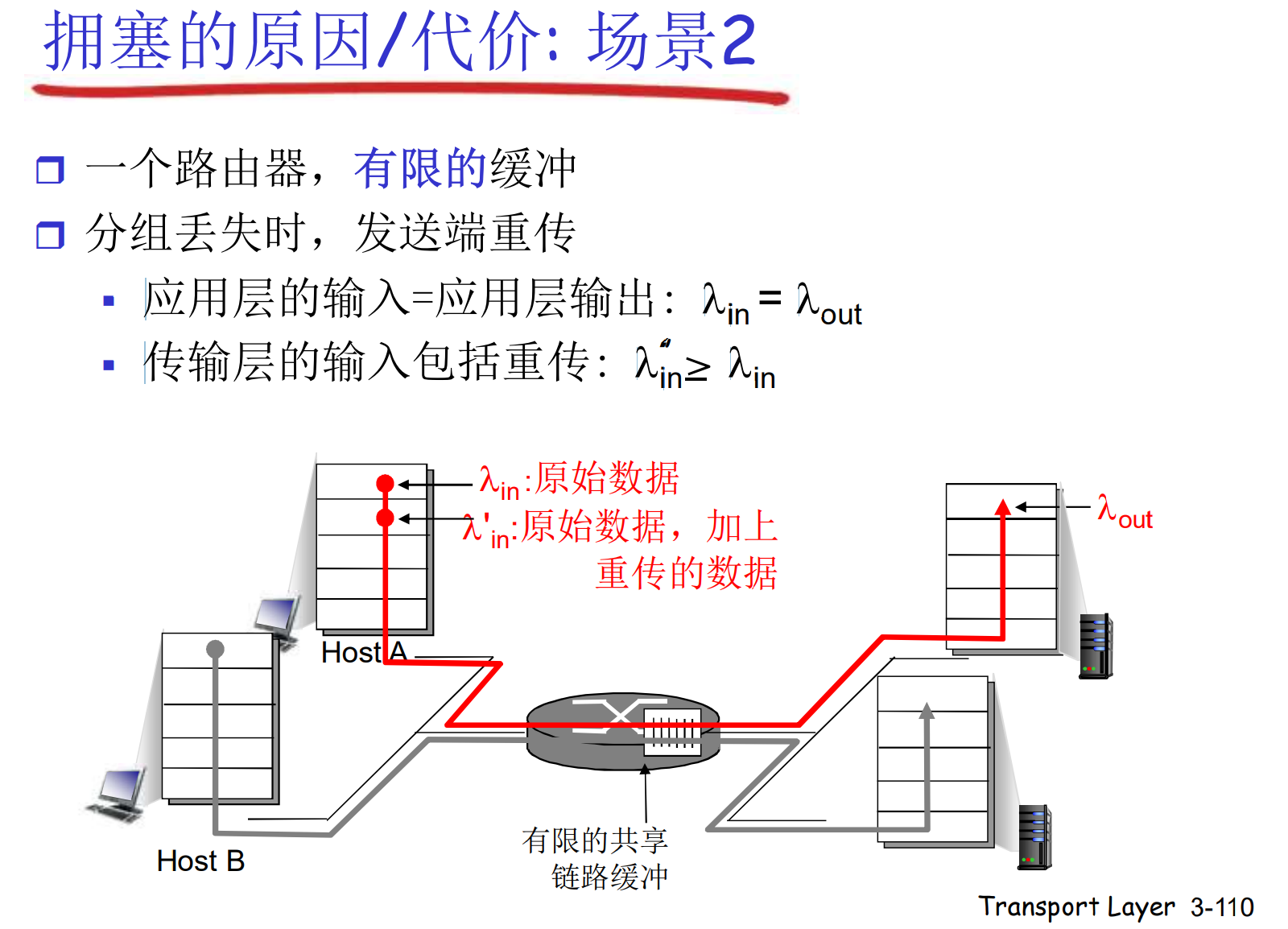
在拥塞的时候, 频繁的超时重传会让网络中有效信息的占比极具下降: 为了让接收方达到有效网络输出lambda, 也许需要数倍的输入
网络拥塞的发生不是线性的, 如果不加以控制, 只要出现一点拥塞, 会使各个发送方灌入无效信息, 持续加剧拥塞情况, 导致在正常工作中瞬间崩溃
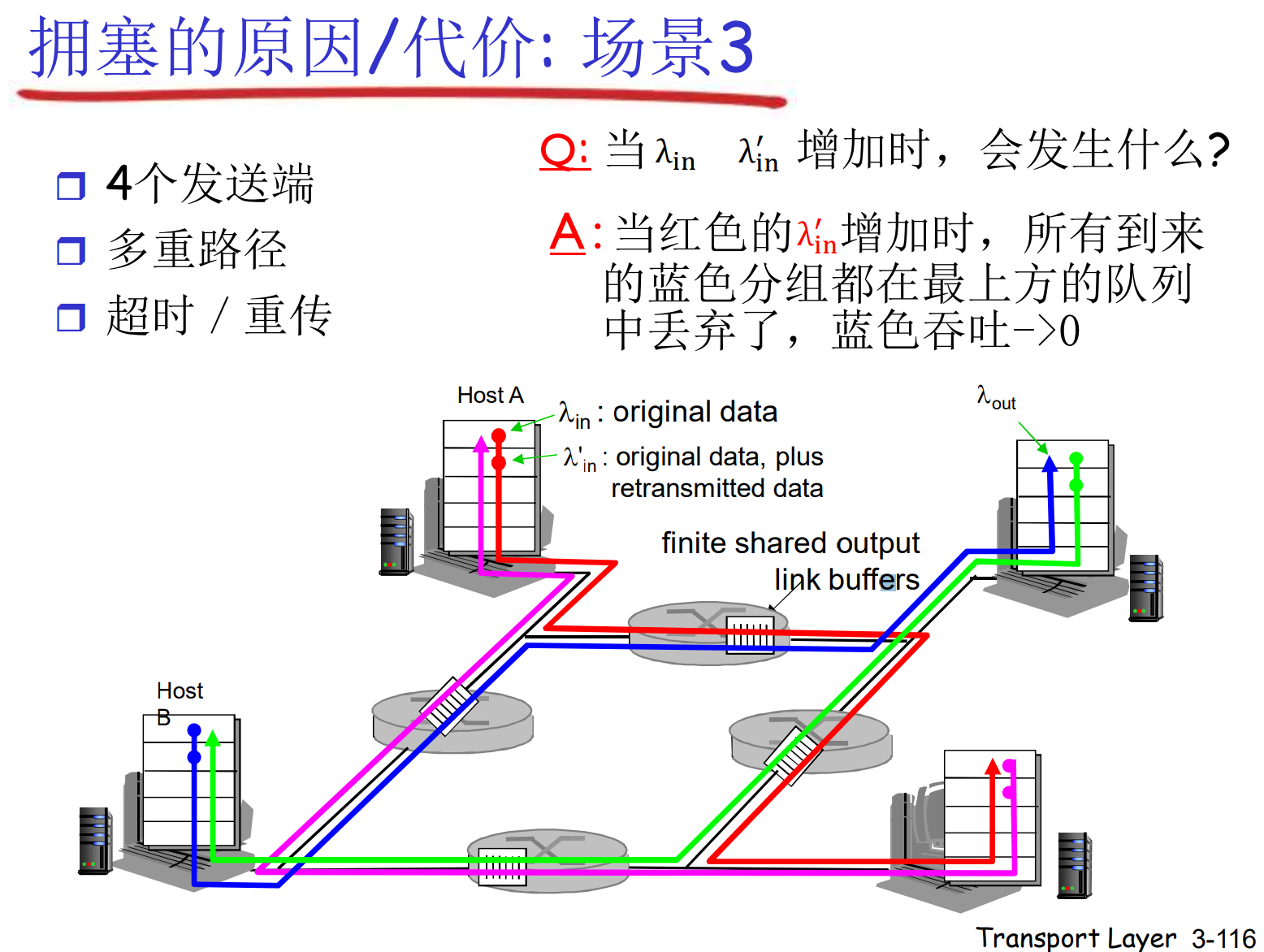
在上图中, 主机对距离较近的跳的路由器有优势, 会挤占其他主机的请求, 让他们被丢弃, 但是在远端的跳, 又反而被其他主机挤占, 自己被丢弃. 这种相互制约的情况下, 无论各个主机如何努力的注入数据, 整个网络都没有输出: 网络死锁
又一个拥塞的代价: 一个分组被抛弃时, 之前上游的资源全部被浪费掉了
拥塞控制方法
- 端到端的控制: 端系统通过延迟和丢包判断是否拥塞(TCP的方法)
- 网络辅助控制: 网络给端系统一定显式反馈
网络辅助控制实例: ATM ABR拥塞机制
ABR(Available bit rate): 弹性服务模式
- 如果路径没有压力, 发送方可以使用全部可用带宽
- 如果路径拥塞, 限制发送方的最大发送带宽
网络中发送的基本单位叫信元, 有两种, 数据信元和资源管理信元(RM cell).
资源管理信元在发送端间隔插入, 在接收端直接返回, 在网络核心被交换机打上标志
- NI bit: 轻微拥塞, 不要再增加注入速率
- CI bit: 明显拥塞, 降低注入速率
- ER: 显式速率, 发送方填写, 交换机修改
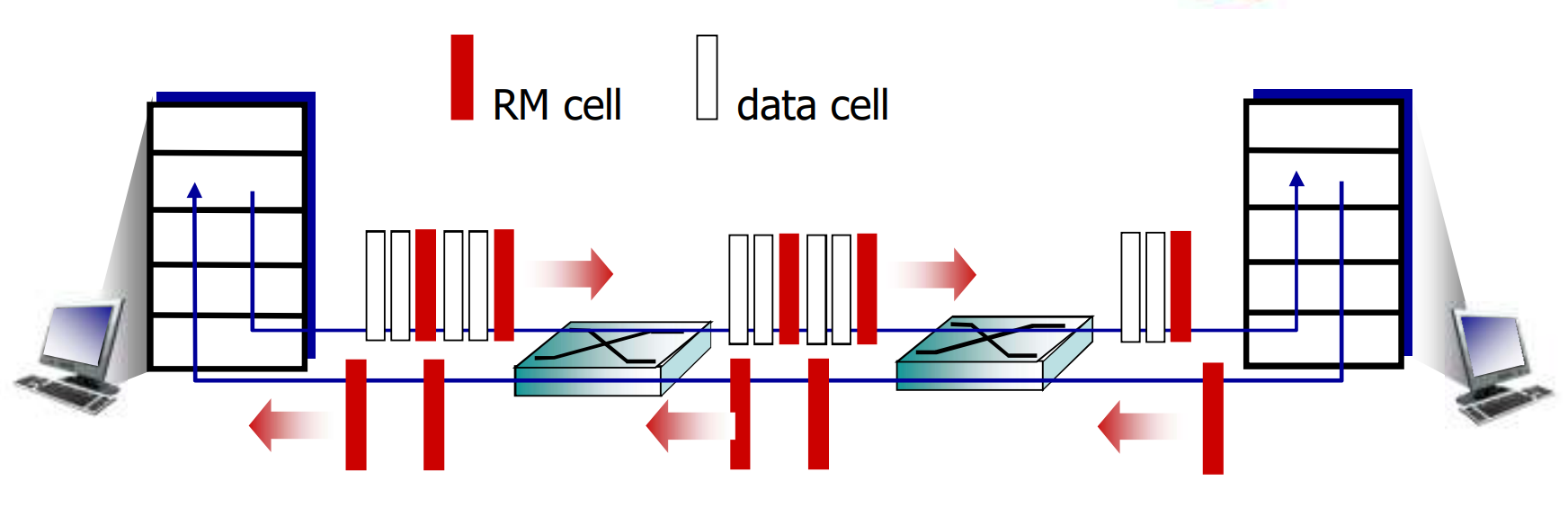
在一次Round trip中, 发送方通过传回的RM cell来动态调整注入速率
3.7 TCP拥塞控制
TCP拥塞控制机制
在TCP中, 网络不提供反馈信息, 而是采用端到端的拥塞控制
这种做法降低了网络核心的复杂度, 将复杂度转移到边缘
发送方探测拥塞
每个段确认超时(丢失)了: 大概率拥塞
- 可能是网络已经拥塞, 路由器缓存溢出(大概率)
- 可能是因为出错, 在校验中被丢弃(小概率)
3次重复ACK: 轻微拥塞
- 3次重复ACK代表接收方正在乱序收到后续报文段, 但是ACK的段一直没有抵达
- 目标段可能已经丢失, 但是由于超时时间比较保守, 暂未超时
- 说明网络即将拥塞
发送方维护变量CongWin: 已发送但是未确认的数据量(Byte), 有: LastByteSent – LastByteAcked <= CongWin
令 rate = CongWin / RTT, 单位 byte/sec, 即当前每秒钟向网络注入的最大速率
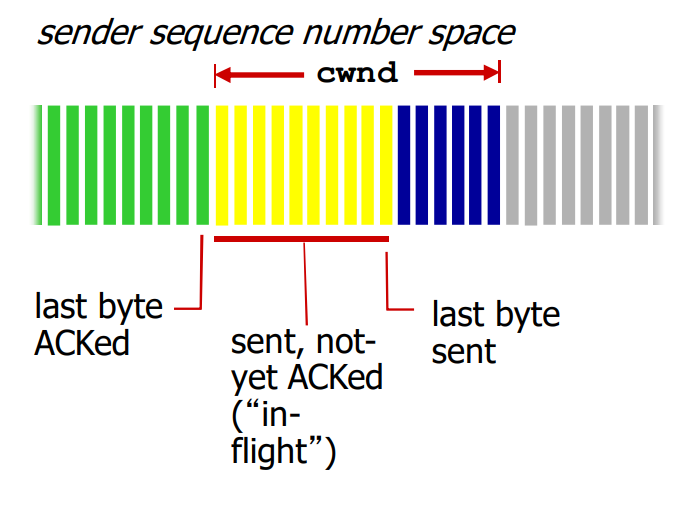
发送速率控制算法
CongWin是动态的, 感知网络拥塞程度的函数
- 超时: CongWin = MSS, 进入SS阶段, 然后每个RTT倍增直到CongWin / 2, 从而进入CA阶段
- 3个重复ACK: CongWin = CongWin / 2, CA阶段
- 除上述外, 说明网络良好, CongWin可以增加
- SS, 慢启动阶段: 快速倍增
- CA, 拥塞避免阶段: 慢速线性
复习: MSS, Maximum Segment Size, TCP最大报文段大小
在上面令cwnd = MSS, 实际上就是调整窗口为一个报文段的长度了名次解释:
SS, Slow-Start, 慢启动
CA, Congestion-Avoidance, 拥塞避免
联合控制方法
TCP发送端需要控制发送窗口, 即, 发送但是未确认的数据量同时满足流量控制, 拥塞控制的要求
SendWin = min{CongWin, RecvWin}, 其中
- CongWin是本地动态测算的
- RecvWin是捎带技术中, 接收方ACK信息携带的
比如, 当前cwnd = 4000B, 接收方rwnd = 1024B, 则发送方要控制发送速率, 每单位时间最多注入min{cwnd, rwnd}的数据, 即1024B
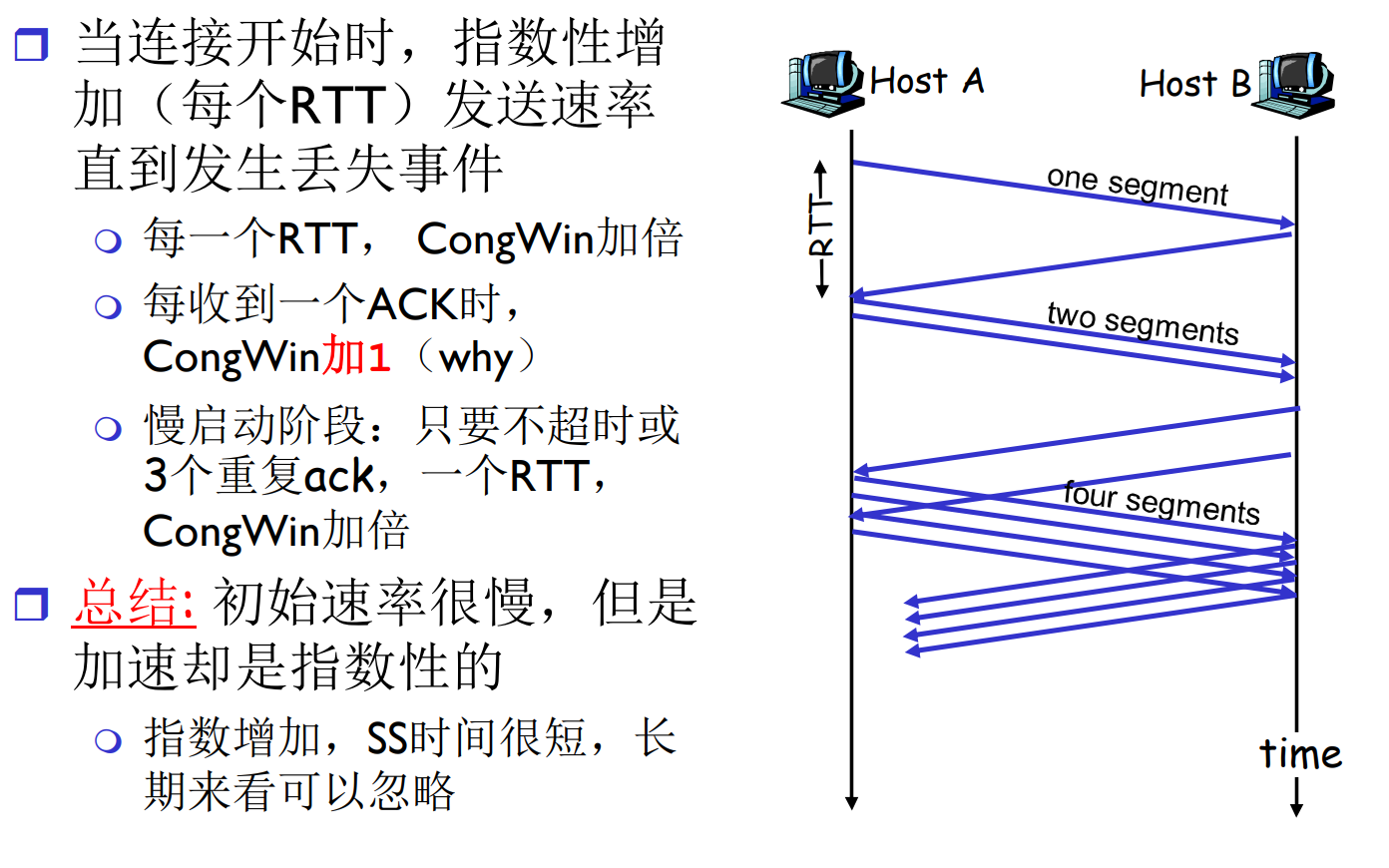
拥塞控制策略: 慢启动
TCP刚刚建立时, cwnd = MSS
比如, 刚刚建立连接, cwnd = MSS = 1450B& RTT = 200ms
则初始速率 = 58.4kbps
此时的可用带宽可能很大, 每个RTT都翻倍cwnd, 直到发生丢失或者重复ACK事件
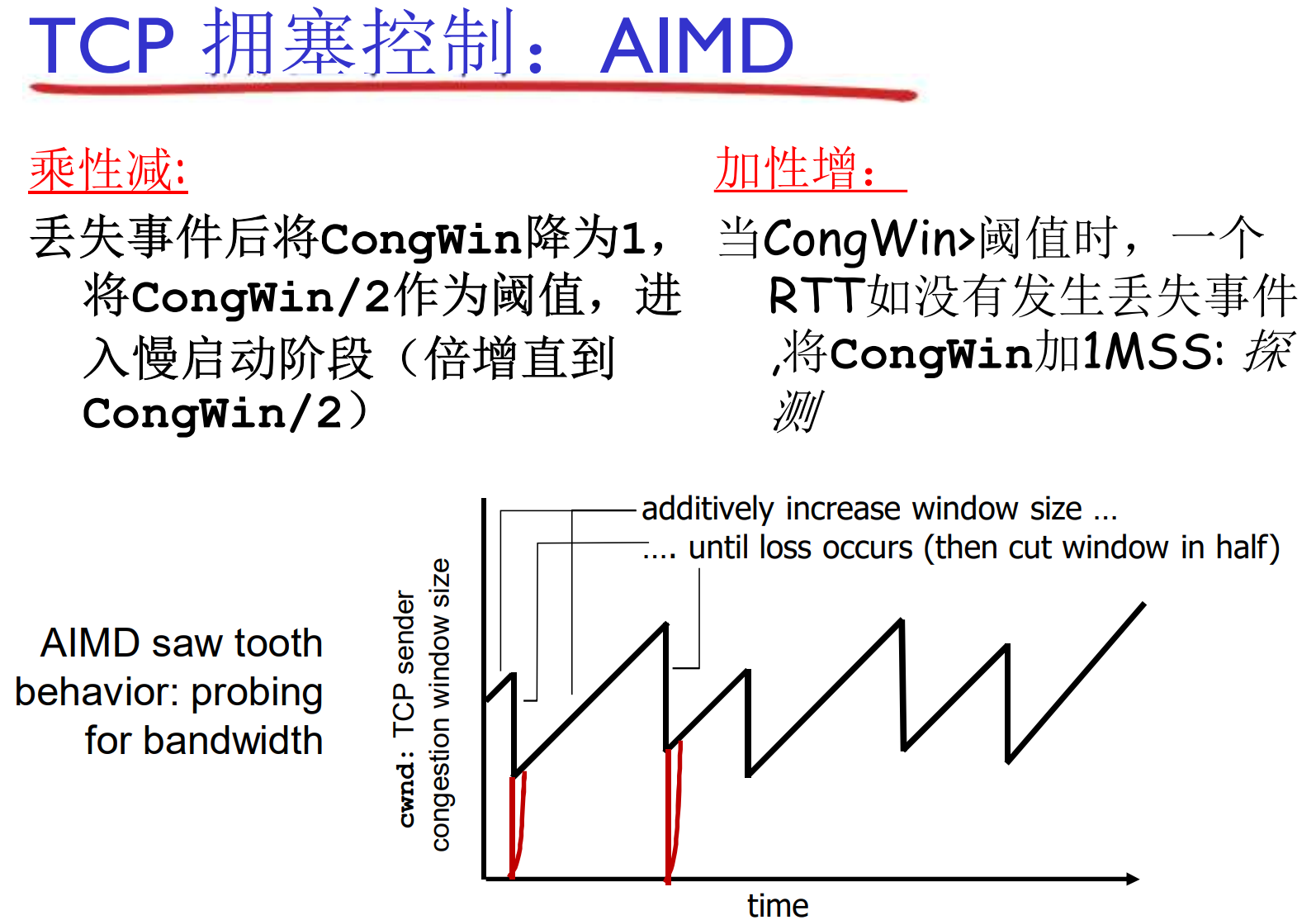
一个例子:
cwnd = 1, 2, 4, 8, 16, 32[丢失, 重制, 设置警戒值16, 进入SS]
cwnd = 1, 2, 4, 8, 16, 17, 18, 19, 20, 21, 22[丢失, 设置警戒值11SS]
cwnd = 1, 2, 4, 8, 11, 12, 13, 14[3个冗余ack, 从警戒值7开始, 直接进入CA]
cwnd = 7, 8, 9, …
即, 丢失(严重拥塞)与冗余ACK(轻微拥塞)的控制策略有区别
慢启动其实并不慢, SS的迭代只需几次就可以触碰到线路性能瓶颈

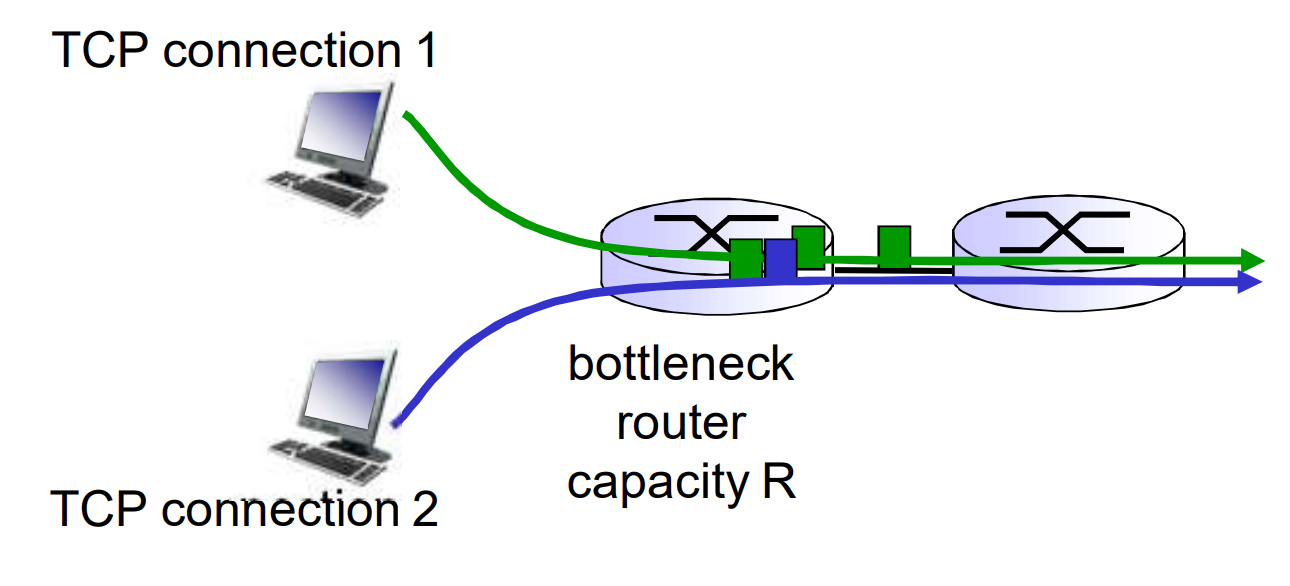
TCP的公平性
在两个主机竞争瓶颈带宽资源的时候, 每个主机能获得 1/n 的带宽
Chap4. 网络层: 数据平面
从第四章开始, 离开网络边缘, 进入网络核心的部分
4.1 导论
网络层服务
网络层在发送主机和接收主机对之间传送段(segment)
- 在发送端, 将段封装到数据报中
- 在接收段, 将段上交给传输层实体
网络层协议存在于每一个主机和路由器
与传输层的端到端服务比较
- 传输层: 两个进程之间, 一般只体现在端系统上(TCP连接)
- 网络层: 两个主机之间, 涉及到路径上的路由器
网络层关键功能
- 转发: 局部功能, 路由器将收到的分组解封装, 分析, 再封装, 从指定接口发出, 送到特定的网络
- 路由: 全局算法, 决定分组从发送主机到目标接收主机到路径
可以用旅行类比: 转发是单个岔路的选择, 而路由是全局的路线规划
数据平面与控制平面
数据平面:
在本地, 每个路由器的功能, 决定从路由器的输入端口到达的分组如何转发到输出端口
- 传统方式: 目标地址+转发表
- SDN方式: 多个字段+流表
控制平面:
网络范围内的逻辑, 决定数据报如何在路由器间路由, 数据报从源到目标主机的端到端路径
- 传统路由算法: 路由器中实现
- SDN: 远程服务器实现
名次解释: SDN, Software Defined Network, 软件定义网络, 一种可编程的网络实现
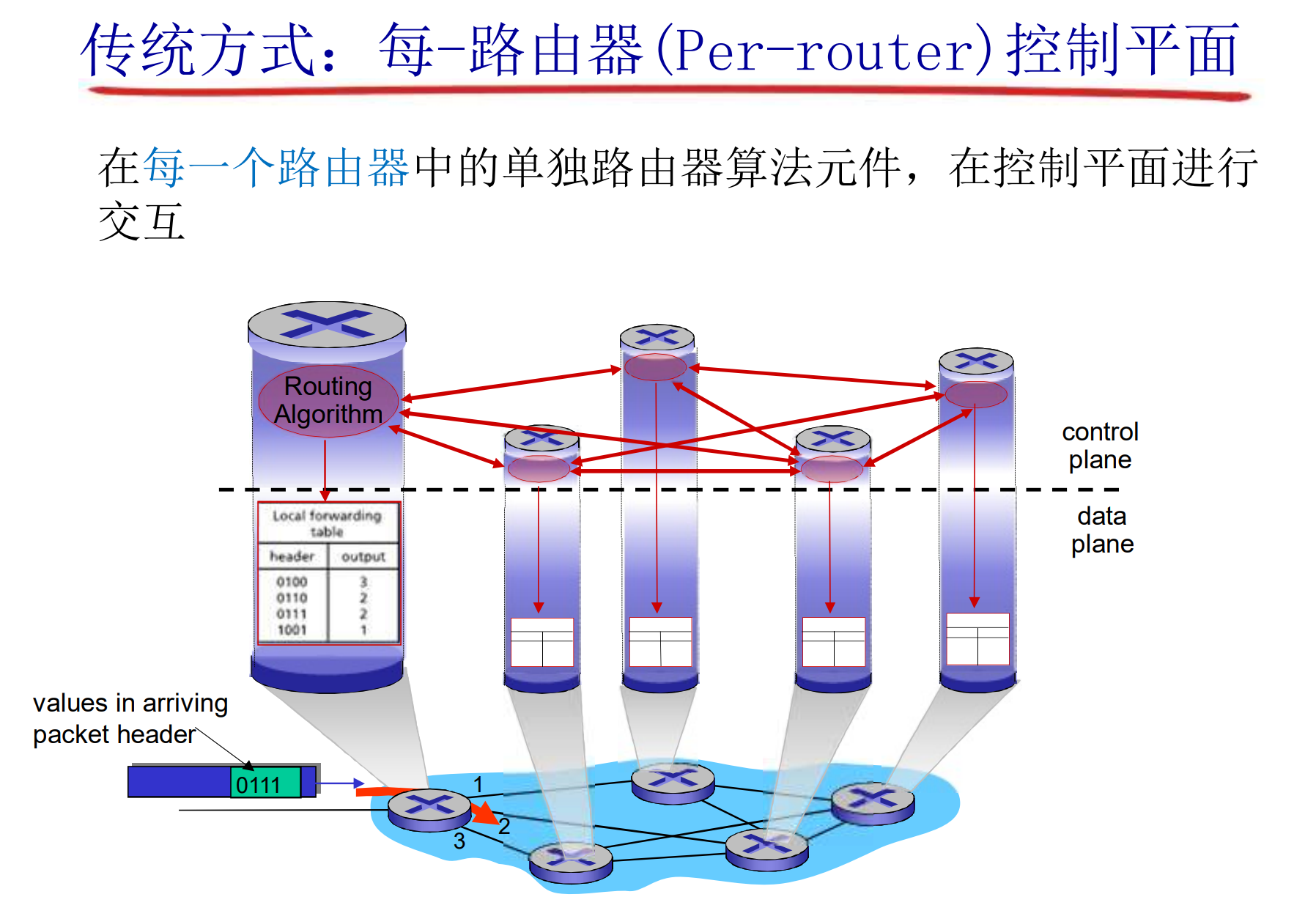
在传统方式中, 控制平面与数据平面紧耦合, 实现在每个具体的路由器中, 是分布式的
- 路由器算出路由表(控制平面), 然后分组根据路由表的规则转发(数据平面)
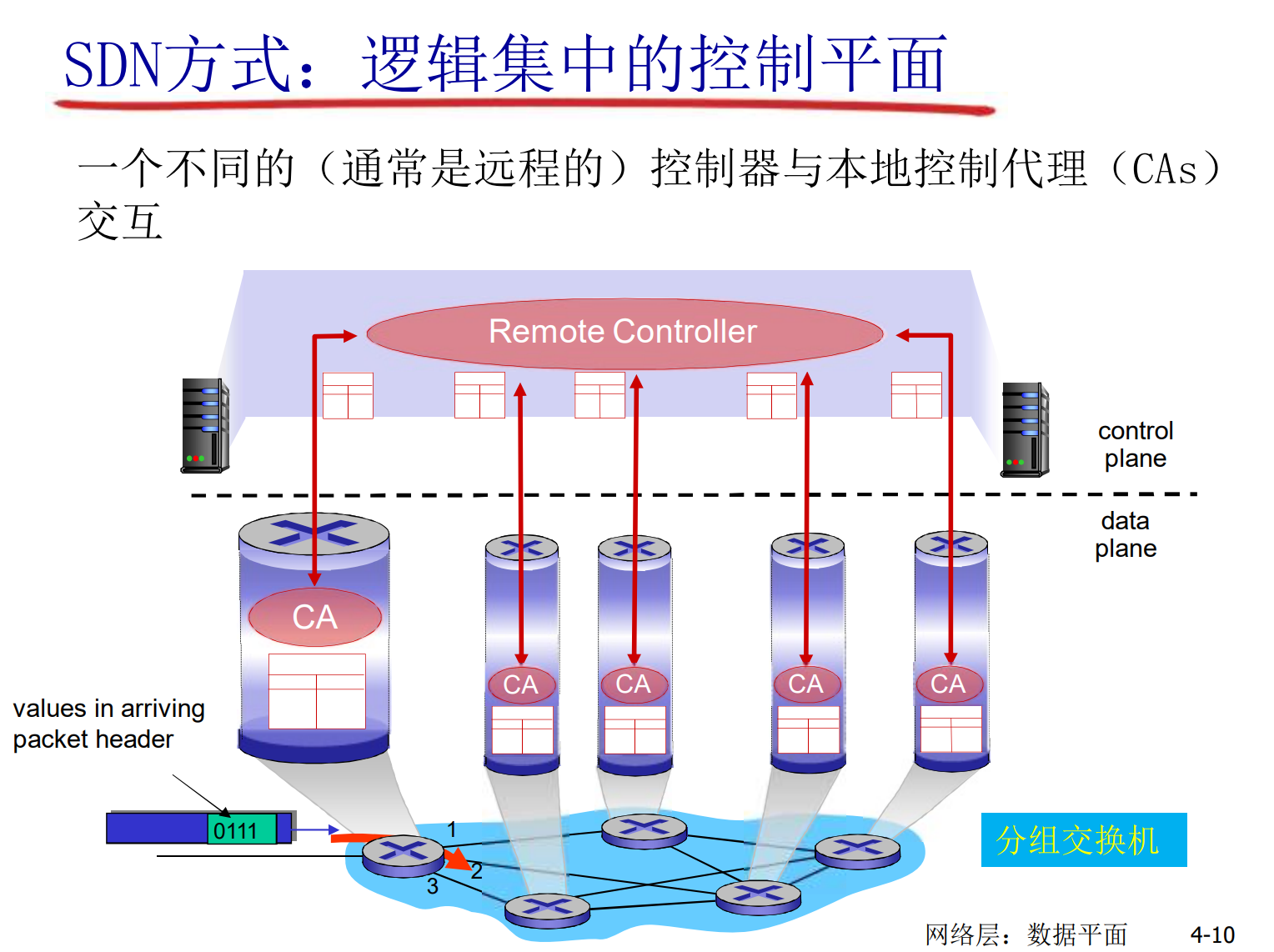
在SDN中, 远端服务器运行着网络操作系统, 通过南向接口将流表交付路由器(控制平面), 路由器根据流表对分组进行多个字段的匹配转发
- 远端服务器可以编程, 流表的算法很灵活, 具备弹性, 是集中式的
多个字段可能有: 源MAC, 目标MAC, 源IP, 目标IP, 源Port, 目标Port, 等等
匹配多个字段后, 可以选择出合适的动作: 转发, 阻塞, 泛洪, 修改, 等等
网络层服务模型
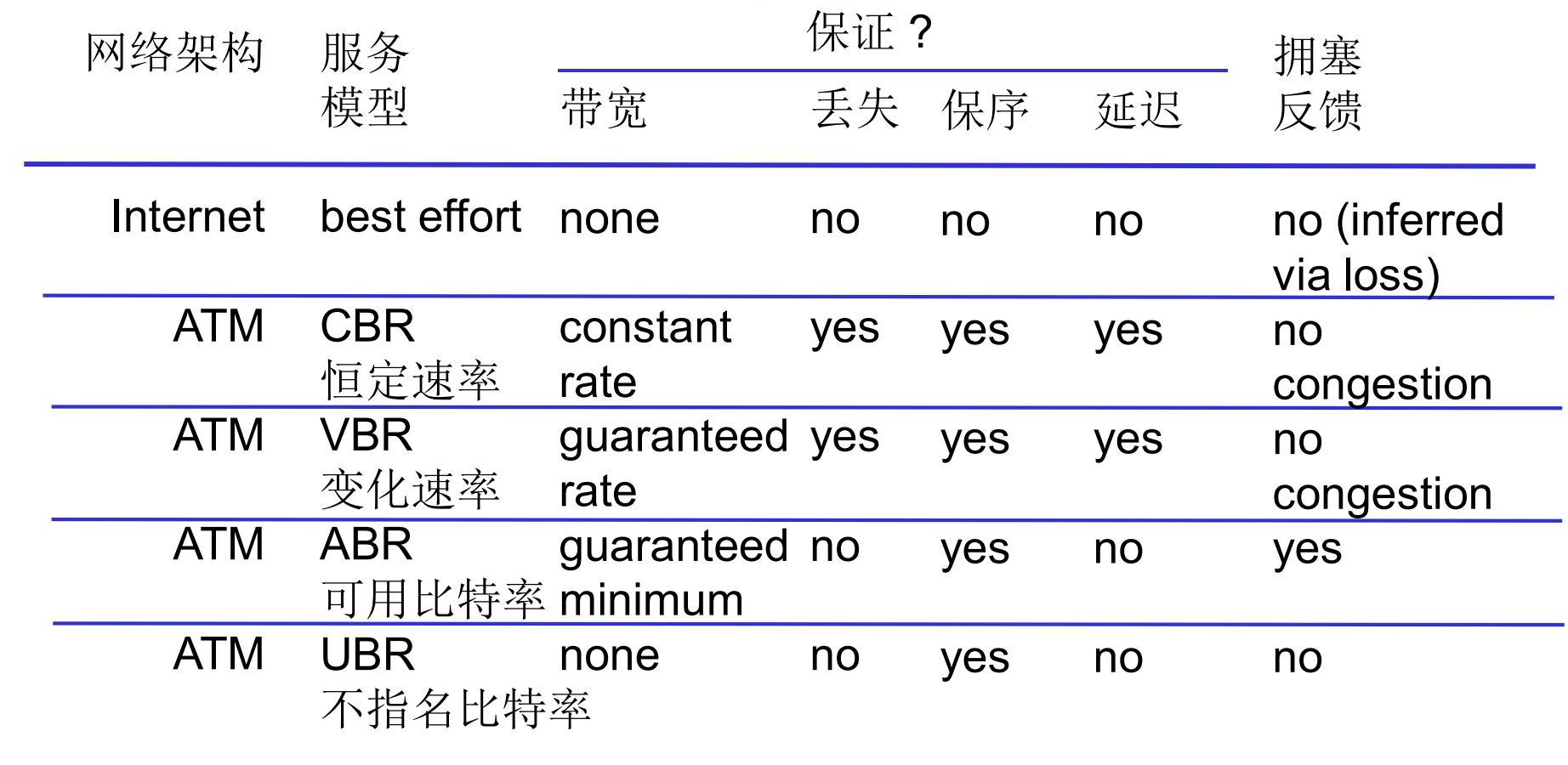
有带宽, 丢失, 保序, 延迟, 拥塞反馈等指标可以衡量一个网络的服务质量. 一种网络模型对应了一组指标
4.2 路由器组成
路由器结构概况
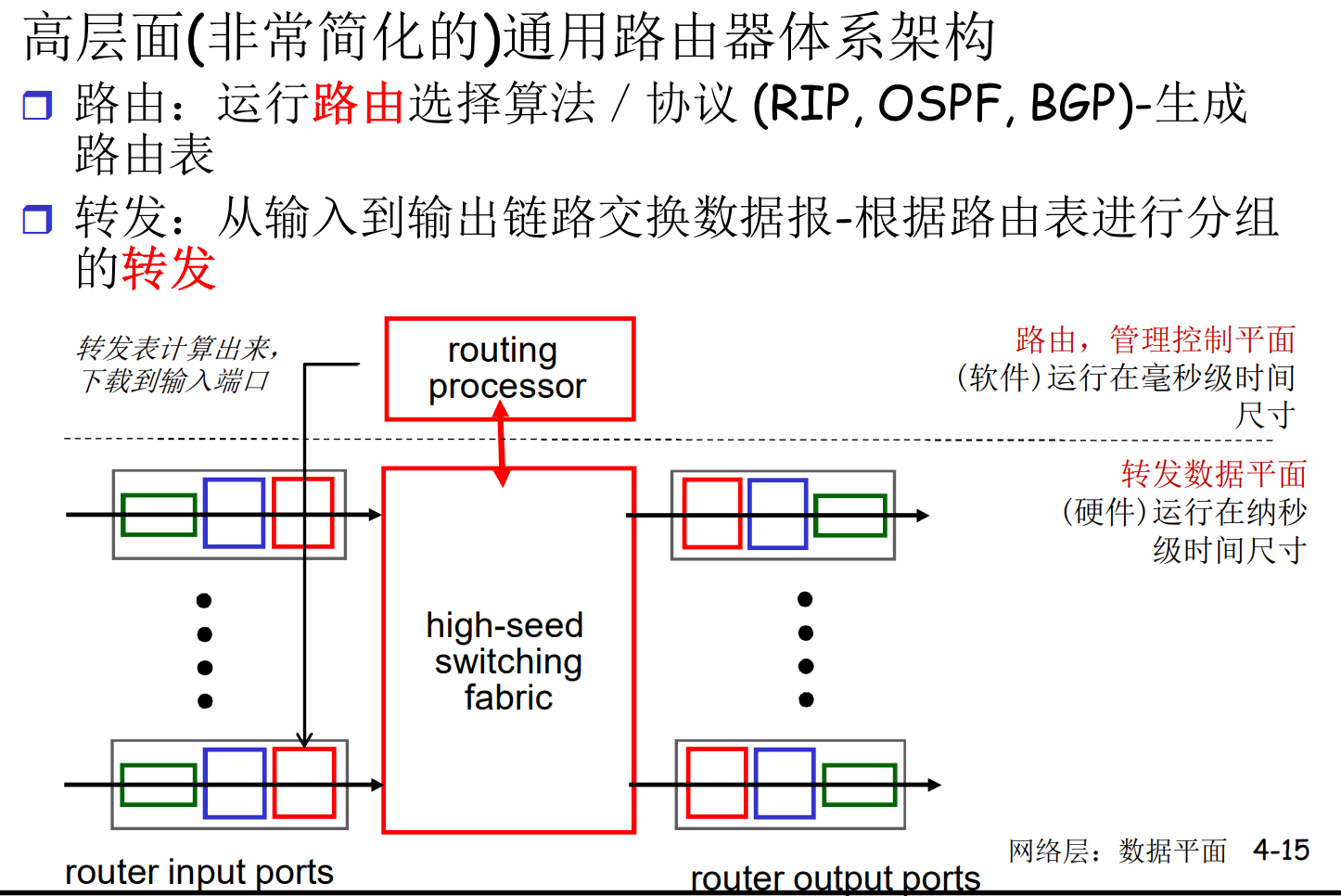
虽然在模型中讨论了路由器的输入, 输出端口, 但是在实际情况中, 路由器的端口是双向绑定的: 即是输入, 也是输出
输入端口功能
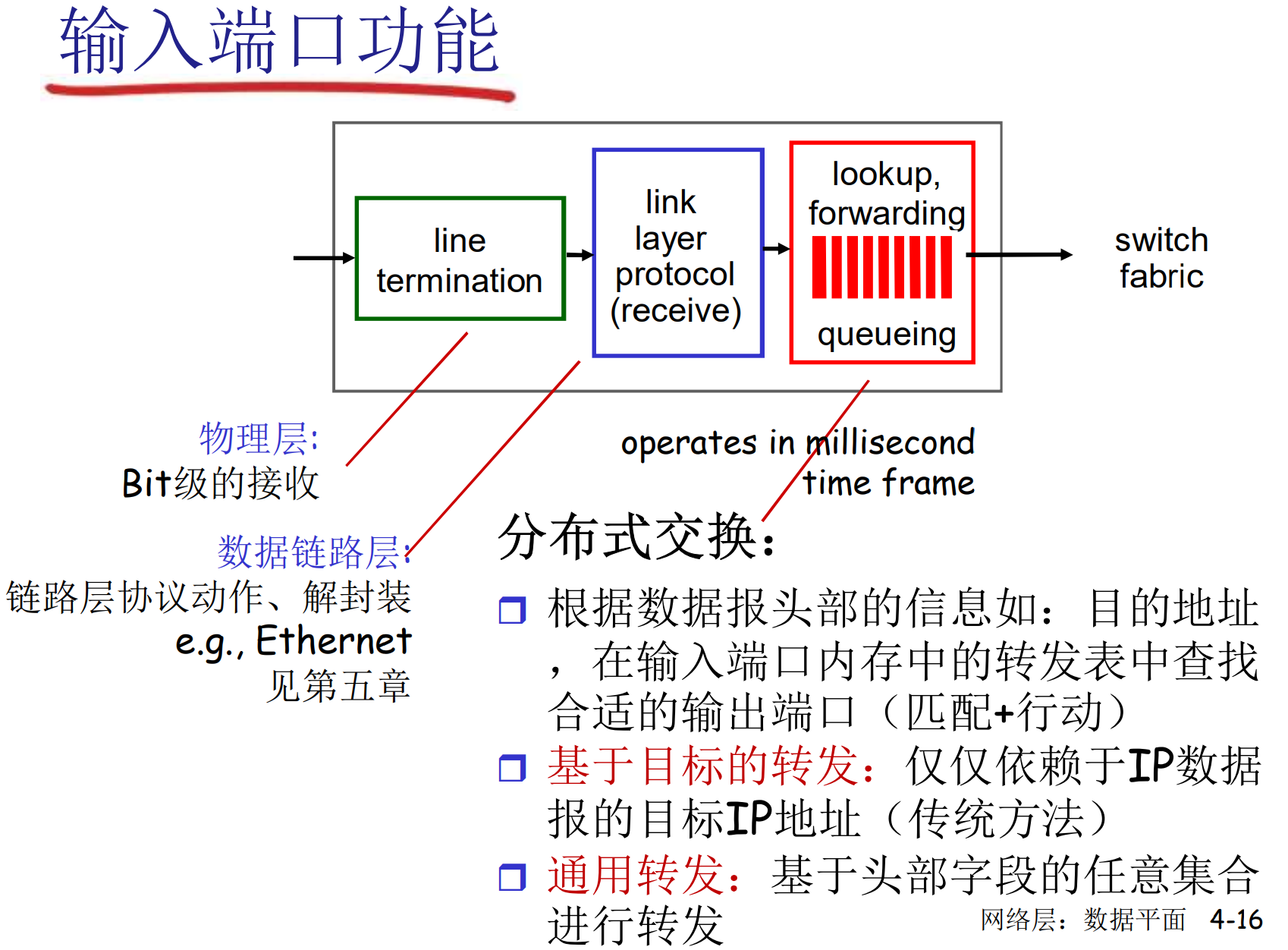
图中的switch fabric是交换设备中用于连接输入端口和输出端口的数据传输结构
端口缓存
路由器的输入, 输出端口都有缓存队列, 用来匹配瞬时输入输出速度的不一致性
头部阻塞(HOL, Head-Of-Line), 排在队伍头的数据报阻塞, 妨碍了后面数据报的前进
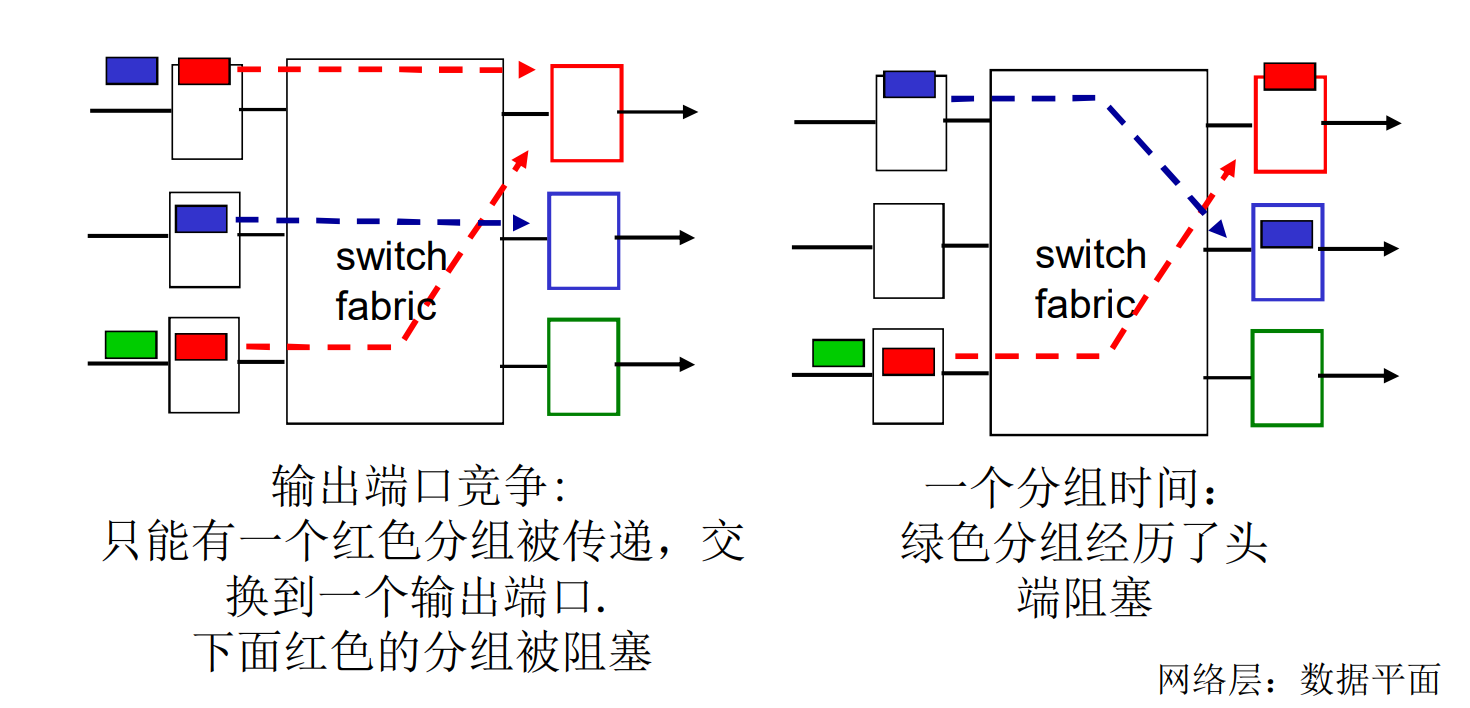
交换结构: Fabric
将分组从输入缓冲区传输到合适的输出端口, 这个局部机构的交换速率应该 >= n倍端口工作速率, Fabric一般不成为瓶颈
Fabric的主要工作方式有3种:
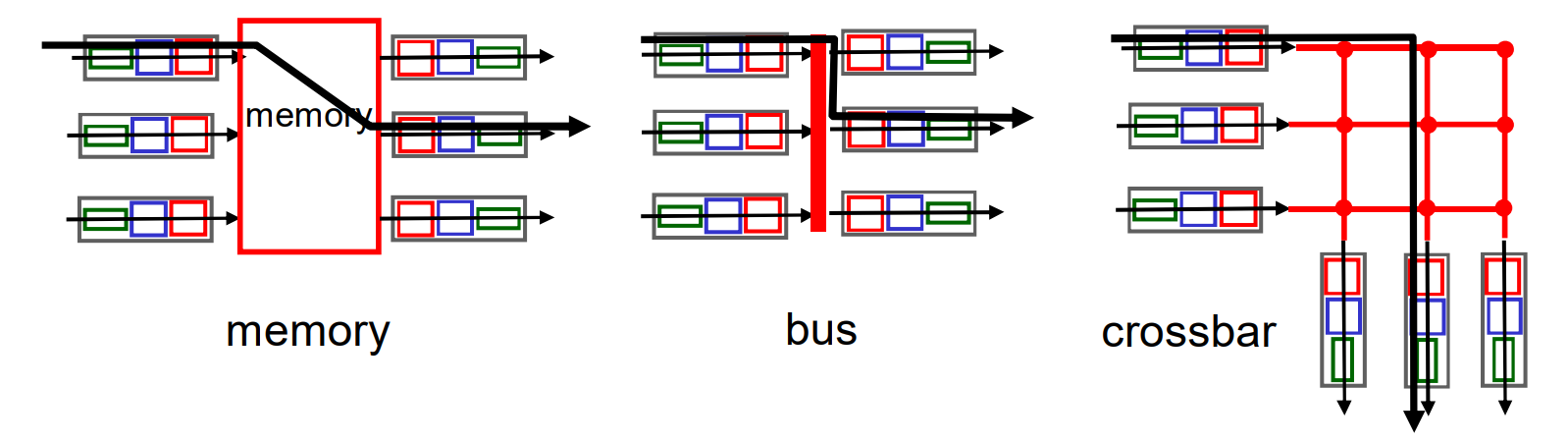
Fabric: 通过内存交换(memory)
第一代路由器
路由器是传统计算机, 通用CPU的直接控制, 在软件层面实现路由, 在硬件上实际上走了系统总线(通用计算机的总线)
- 分组拷贝到系统内存
- CPU从分组头部提取目标地址, 查路由表
- CPU定位目标端口, 拷贝输出
- 转发速率被内存带宽限制(数据报通过系统总线两次)
Fabric: 通过总线交换(bus)
- 数据报通过共享总线, 总线资源存在竞争(接口之间)
- 这里的总线专用于数据报, 是硬件层面开发的通道
这种路由器对于接入或企业级需求速度已经足够, 但不适合区域或者骨干级网络
Fabric: 通过交叉开关交换(互联网络, crossbar)

输出端口缓存
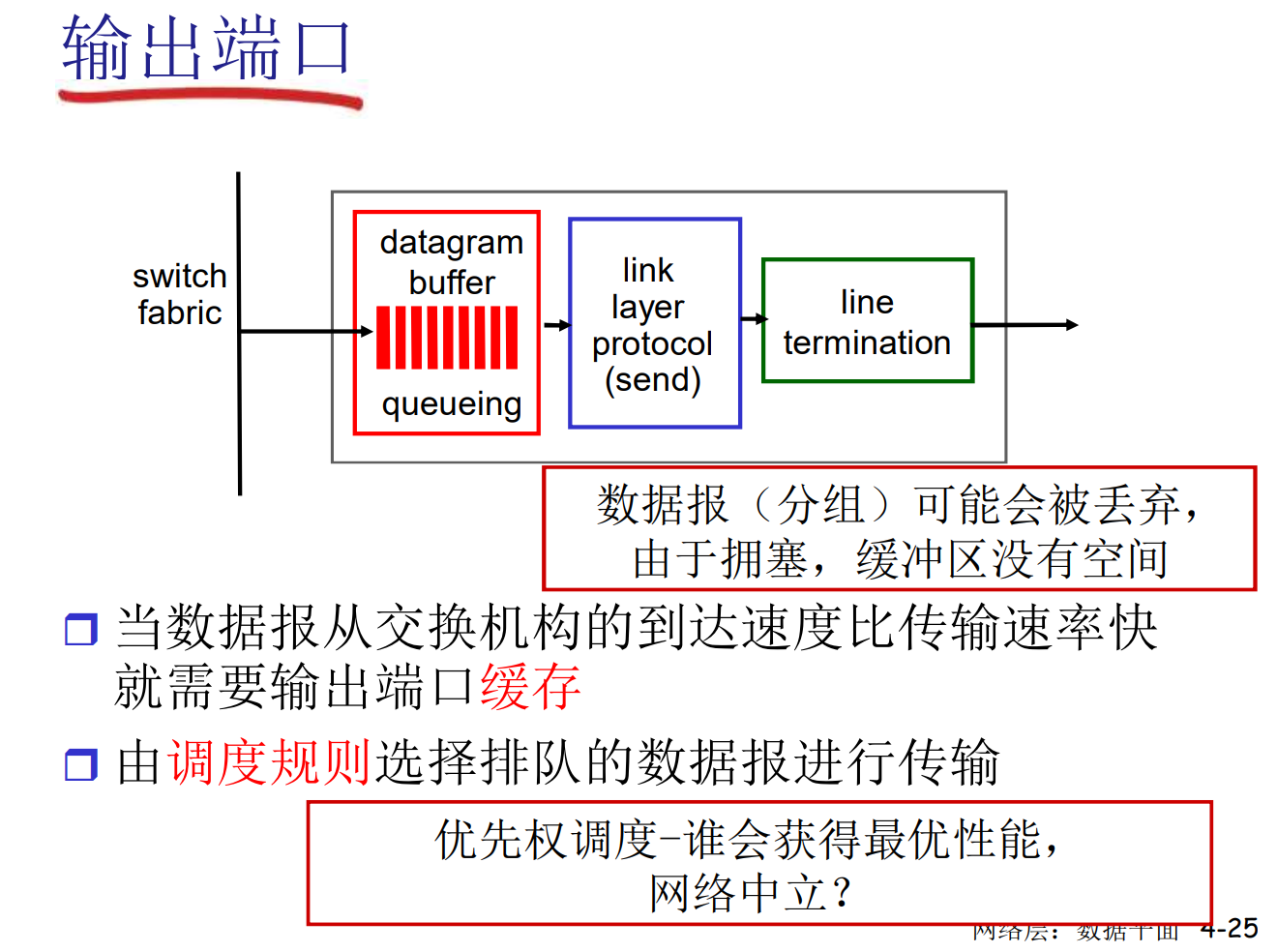
缓存调度策略
还可以细分为处理策略和丢弃策略
- FIFO策略
- 优先级策略
- RR策略(每一类轮转发送)
- …
4.3 IP协议
互联网的网络层
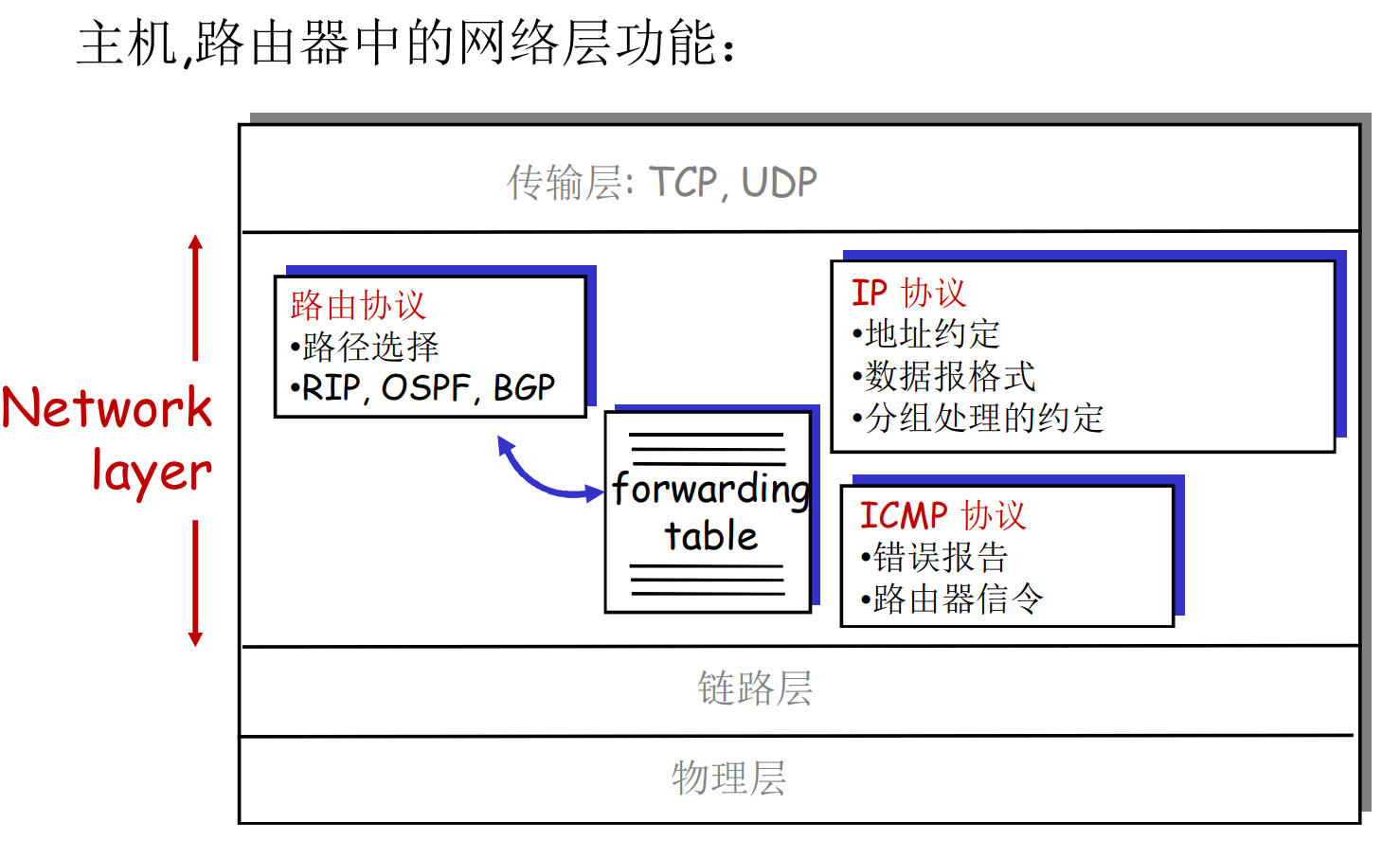
- 路由协议(RIP, OSPF, BGP等)是控制平面的任务
- IP协议是数据平面的
IPv4数据包格式
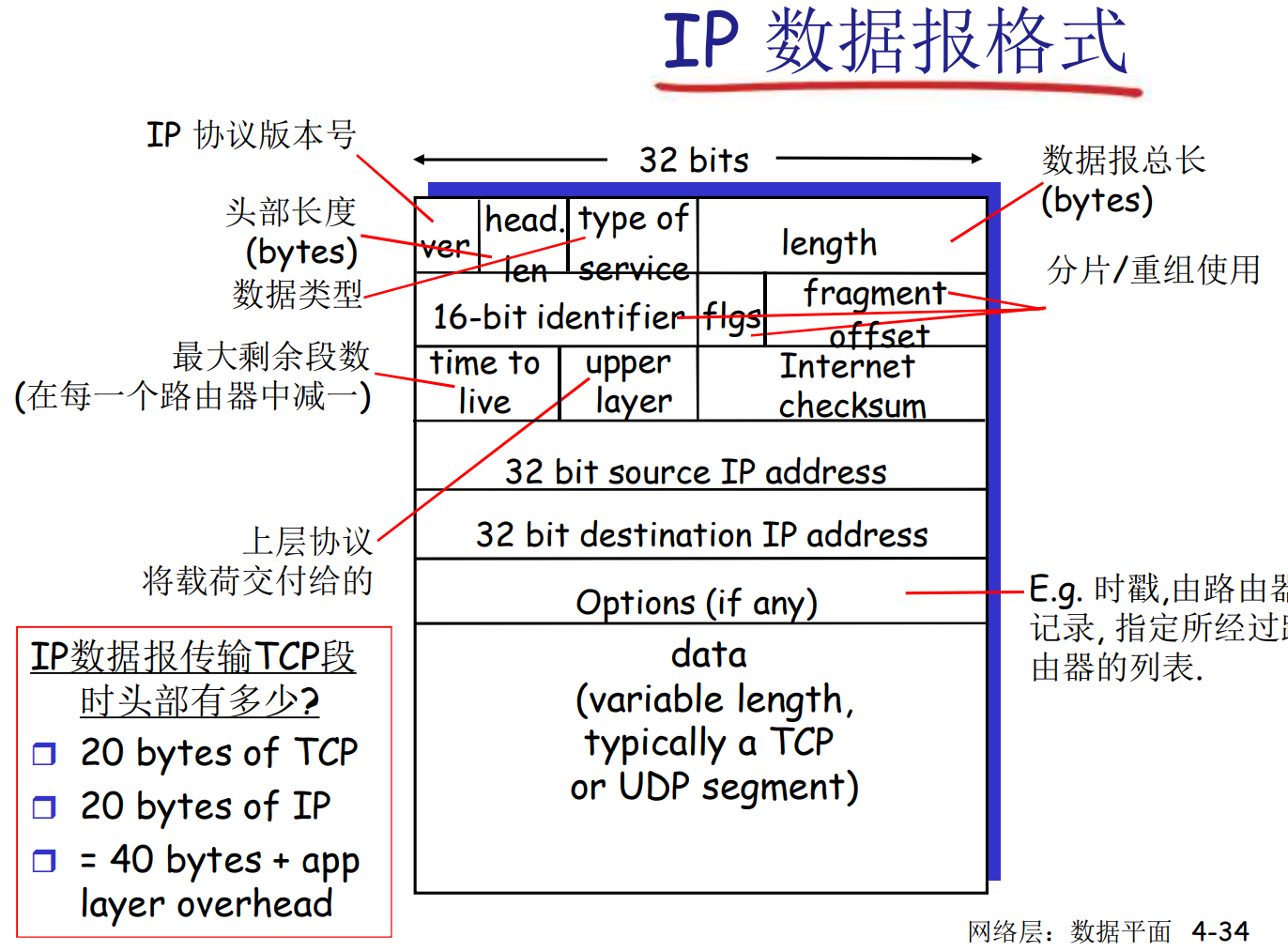
题外话, 尽管IP协议规定了路由器在TTL=0时可以回复一个ICMP信息, 告知超时丢弃, 但是很多路由器, 防火墙规则被设置成了静默
另外, 由于网络拥塞丢弃的报文, 一般不会回复信息
IP分片和重组
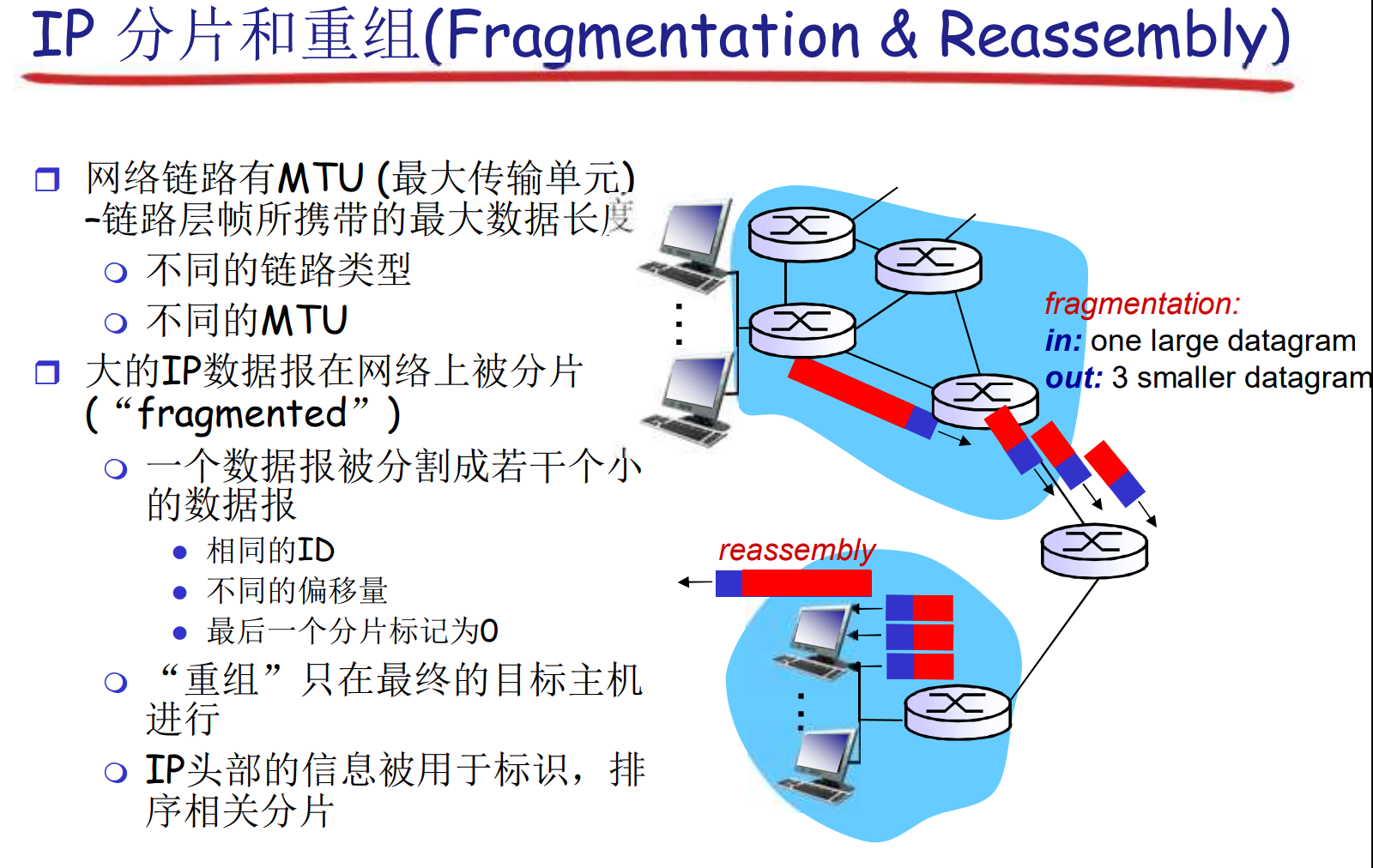

length, ID, fragflag: 标识位: 后面还有没有
非常重要: 计算offset的时候, 以8字节为单位
分片之后, 由目标主机负责重组. 如果分片中有超时, 则不得不丢弃整组
IP编址: 引论
IP地址标识的是接入网络的接口: 主机/路由器和物理链路的连接处
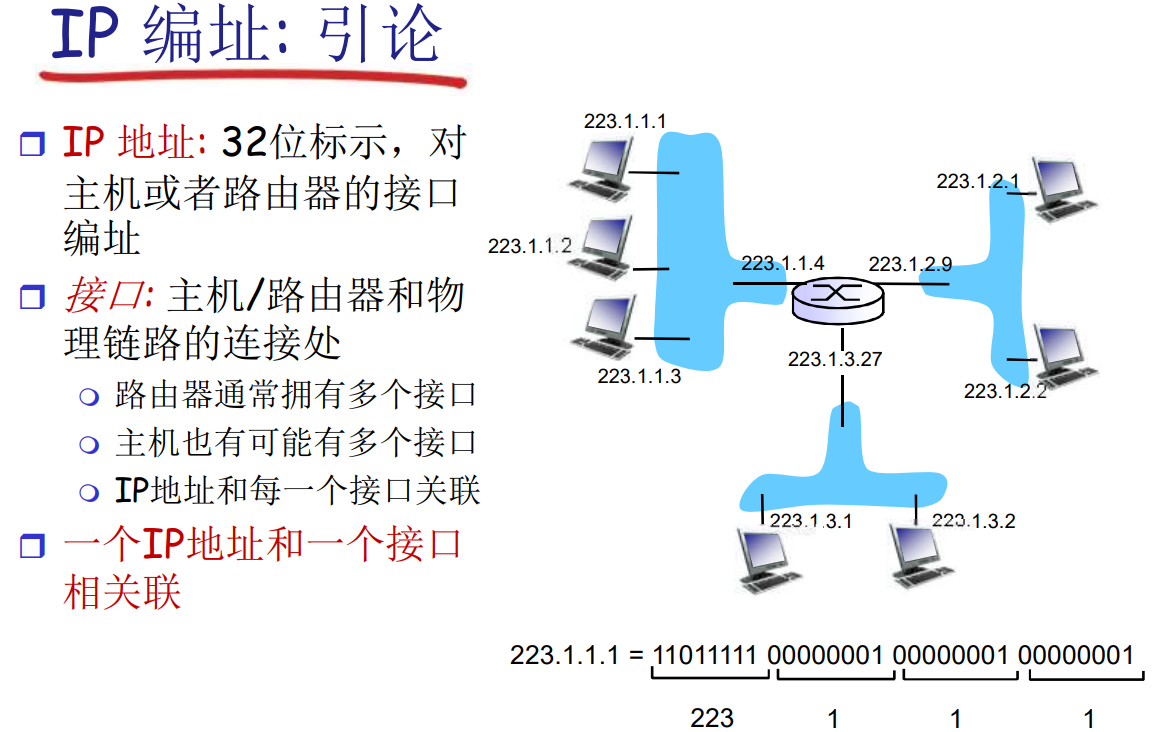
子网(Subnets)
- 子网的IP前缀是一样的
- 子网内通讯不需要路由, 也许会通过交换机
从IP协议的角度来看, 子网内通讯"一跳可达"
要判断一个子网, 只需要断开网络接口, 形成的网络孤岛就是子网
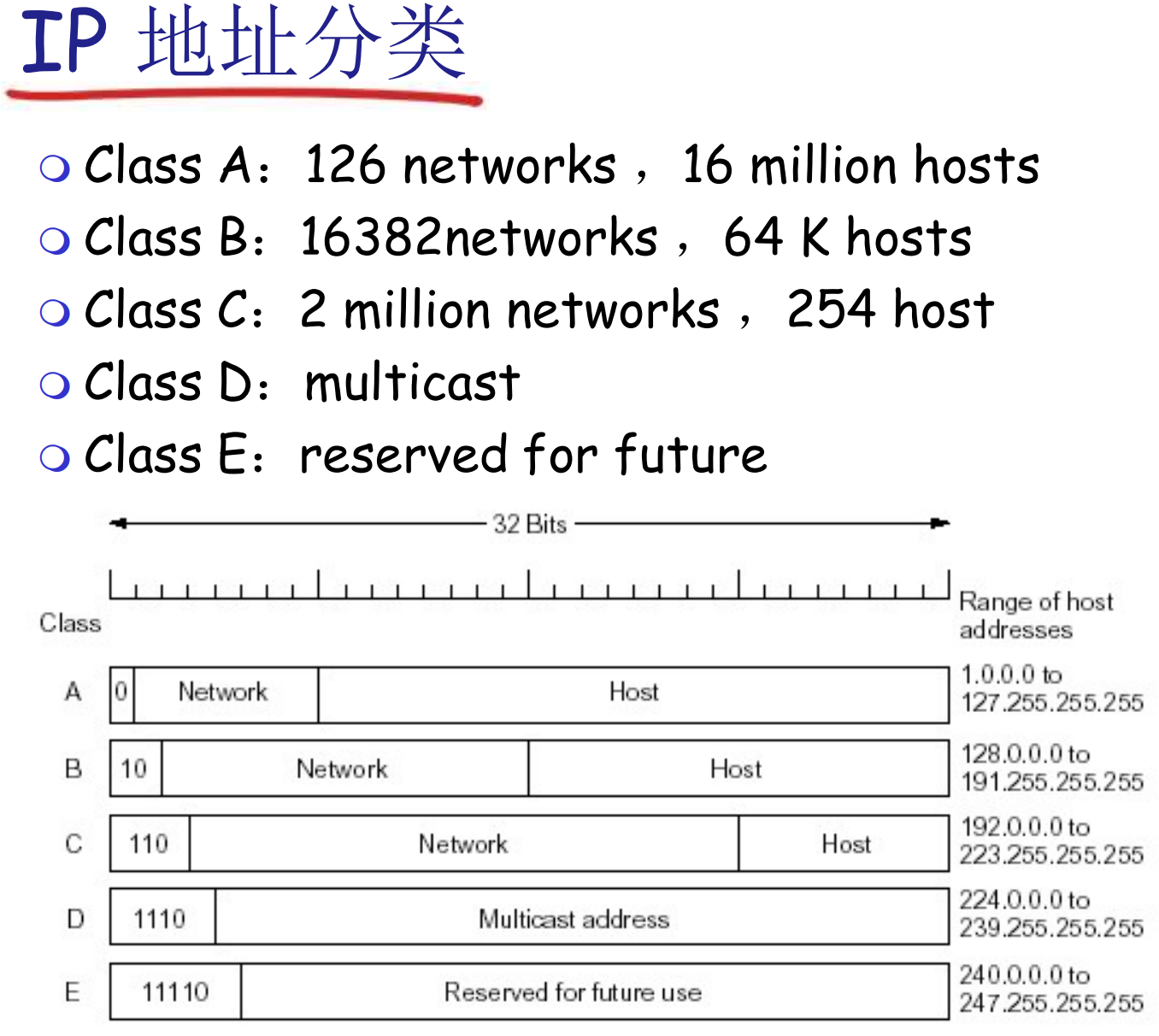
- ABC是单播地址
- D是组播地址, 发给一个地址会通过特定协议发送给组内主机
互联网的路由是以子网为单位的: 无法维护2^32这么多的路由信息
在路由表中, 每一个网络是一个表项
特殊IP地址约定
- 子网部分全0: 本网络
- 主机部分全0: 本主机
- 主机部分全1: 广播全网
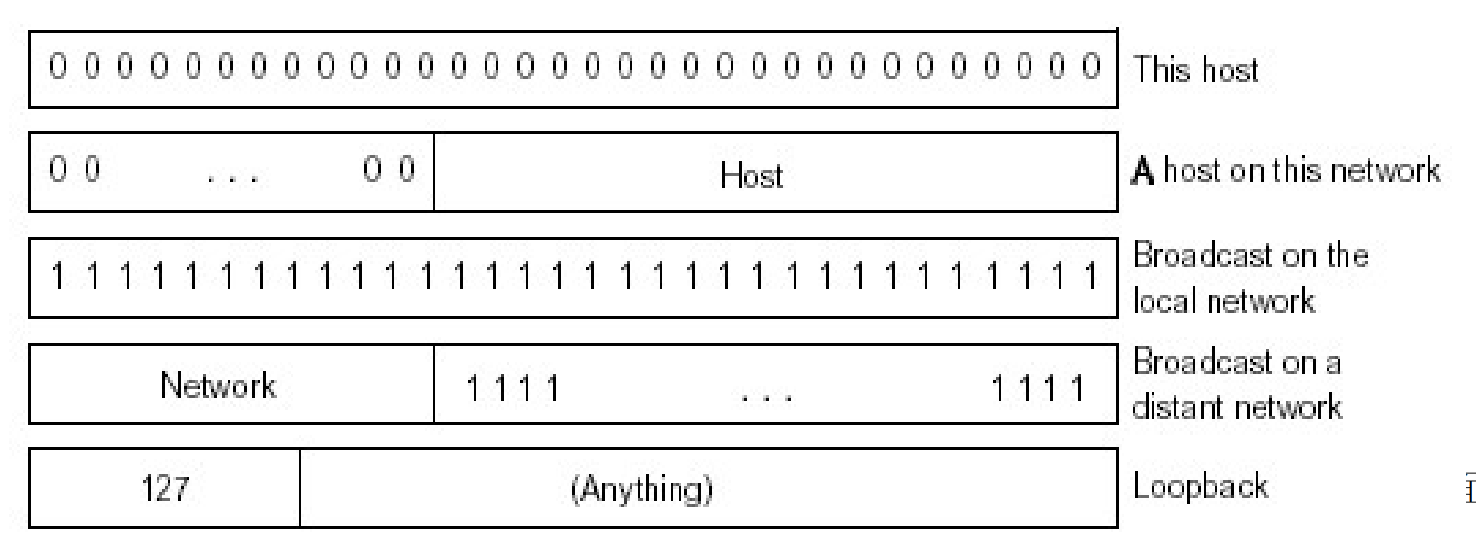
内网专用地址
专用于内网的地址, 永远不会当作公用地址分配
- 公网内不会出现内网地址
- 内网中不会出现公网地址

路由器不对目标地址是内网地址的分组进行转发
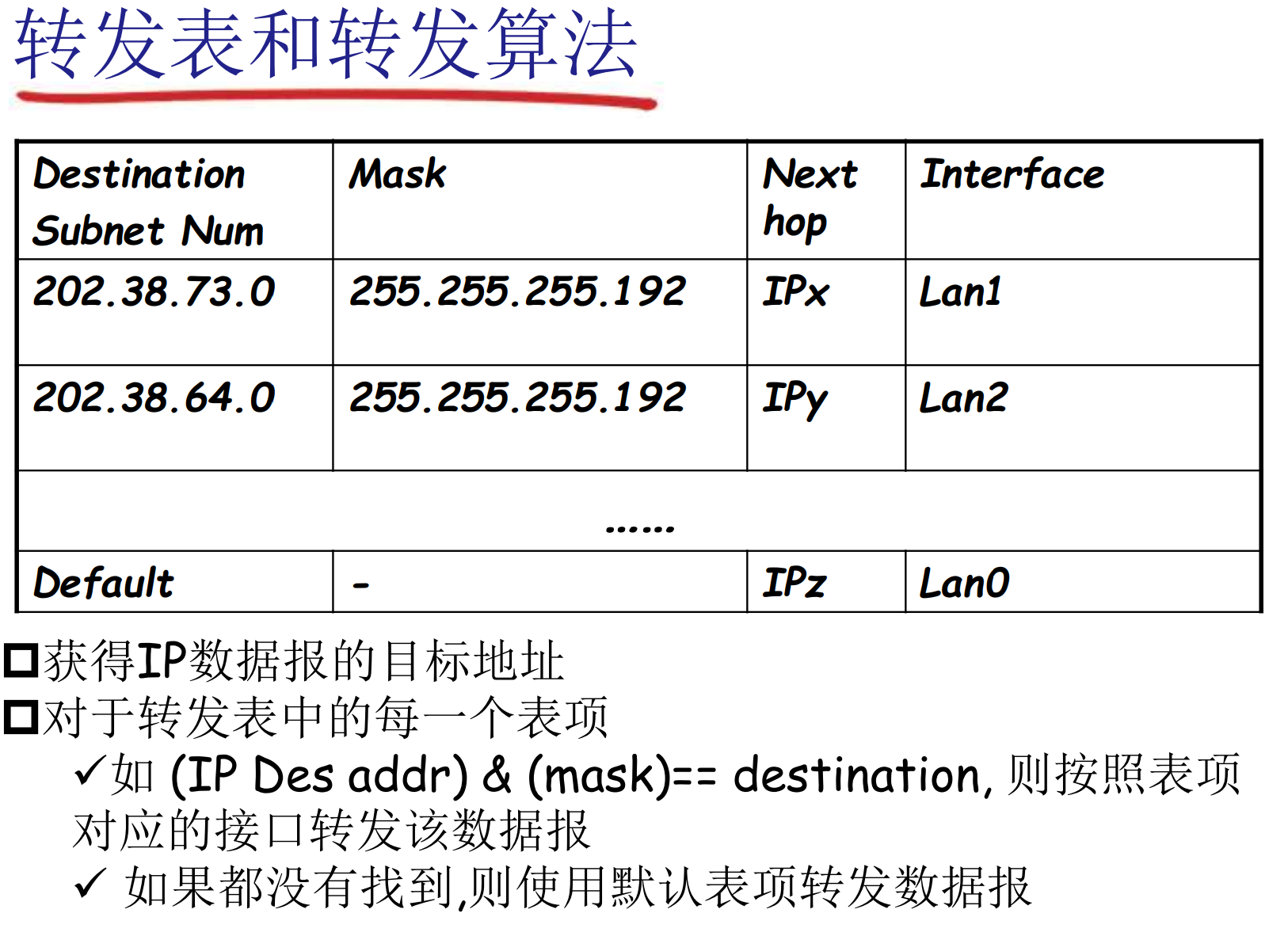
CIDR: 无类域间路由
子网部分可以在任意的位置, 格式a.b.c.d/x, x是地址中子网号的长度

ABC类地址是互联网初期的产物, 随着需求增多显得不够灵活, CIDR技术成为主流
各个子网段的掩码存储在路由器的路由表中, 路由表是通过路由器协议学习到的

- 默认端口一般代表路由器的出口IP(默认网关)
网关: 内网的出口, 位于多个网络之间, 协调网络的数据
获得IP地址
- 网络管理员分配, 本地手动填写
- DHCP技术, 从服务器获取
DHCP: 允许主机在加入网络的时候, 动态的从服务器获得IP地址
- 定时租用
- 到期刷新
DHCP原理:
- 主机上线广播DHCP discover (32位全1)
- DHCP服务器回复DHCP offer
- 主机请求IP, DHCP服务器发送IP与相关信息
- 一段时间后, IP过期, 主机renew
DHCP不仅提供IP地址, 还会提供: 默认网关地址, 默认DNS域名与地址, 子网掩码
作为机构, 可以向ICANN提交手续, 申请IP地址块
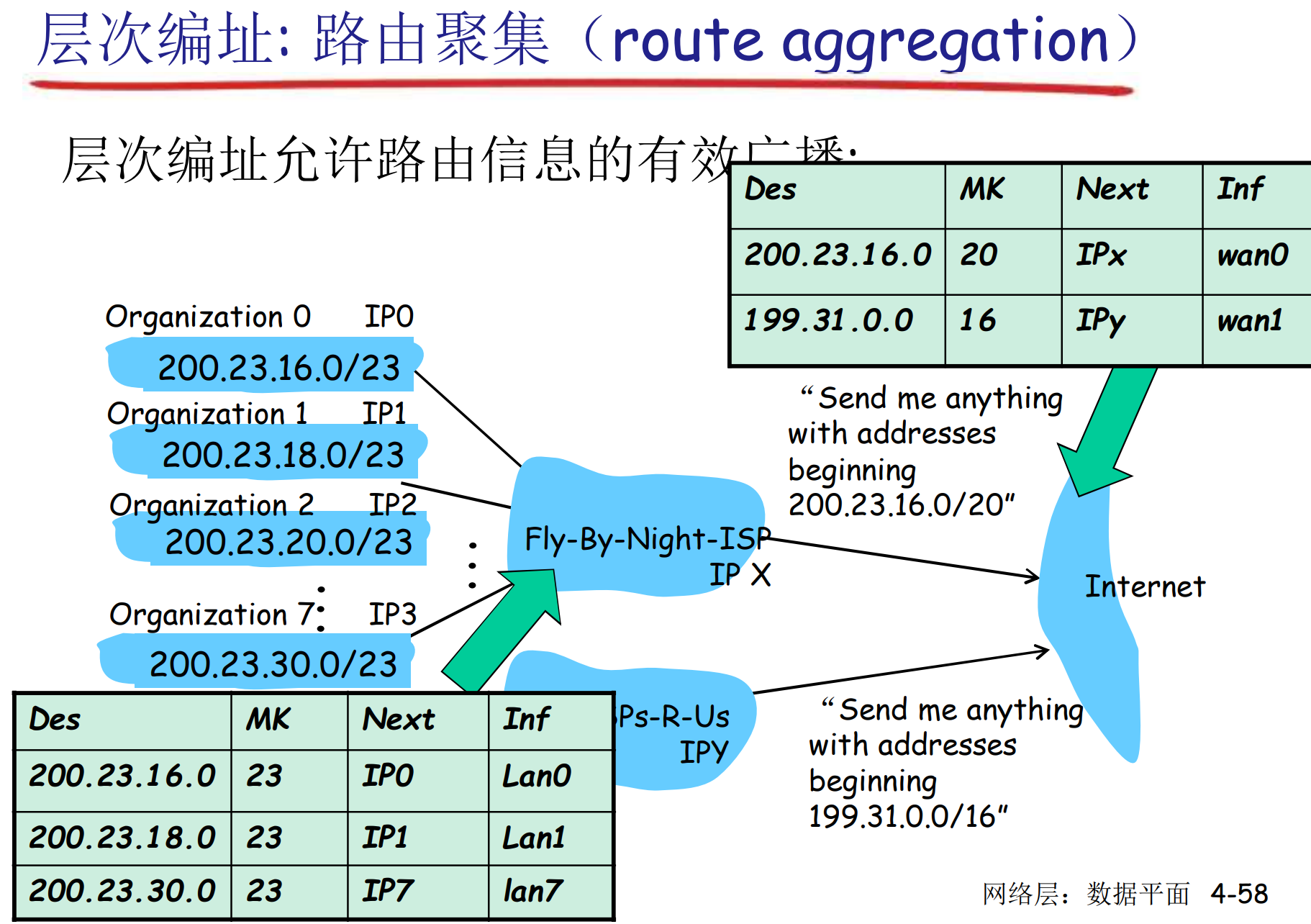
层次编址: 路由聚集
通常用CIDR表示法: 聚集-通告-聚集-通告
当然也会有不能直接聚集的时候, 那只能直接通告
路由聚集技术用来简化路由器中存储的表项, 他不负责产生规则, 只用来化简, 所以是数据平面的功能
层次编址: 特殊路由信息
路由聚集技术允许路由器适当夸大自己的路由范围(有空洞的, 大概集的聚集), 比如某个子网A有8段地址, 一个路由器只负责7段, 他仍可以宣称自己负责整个A的路由, 而缺失的一段的路由信息因为更精确, 遵循最长匹配原则, 仍然会在上级路由中发送给正确的路由器
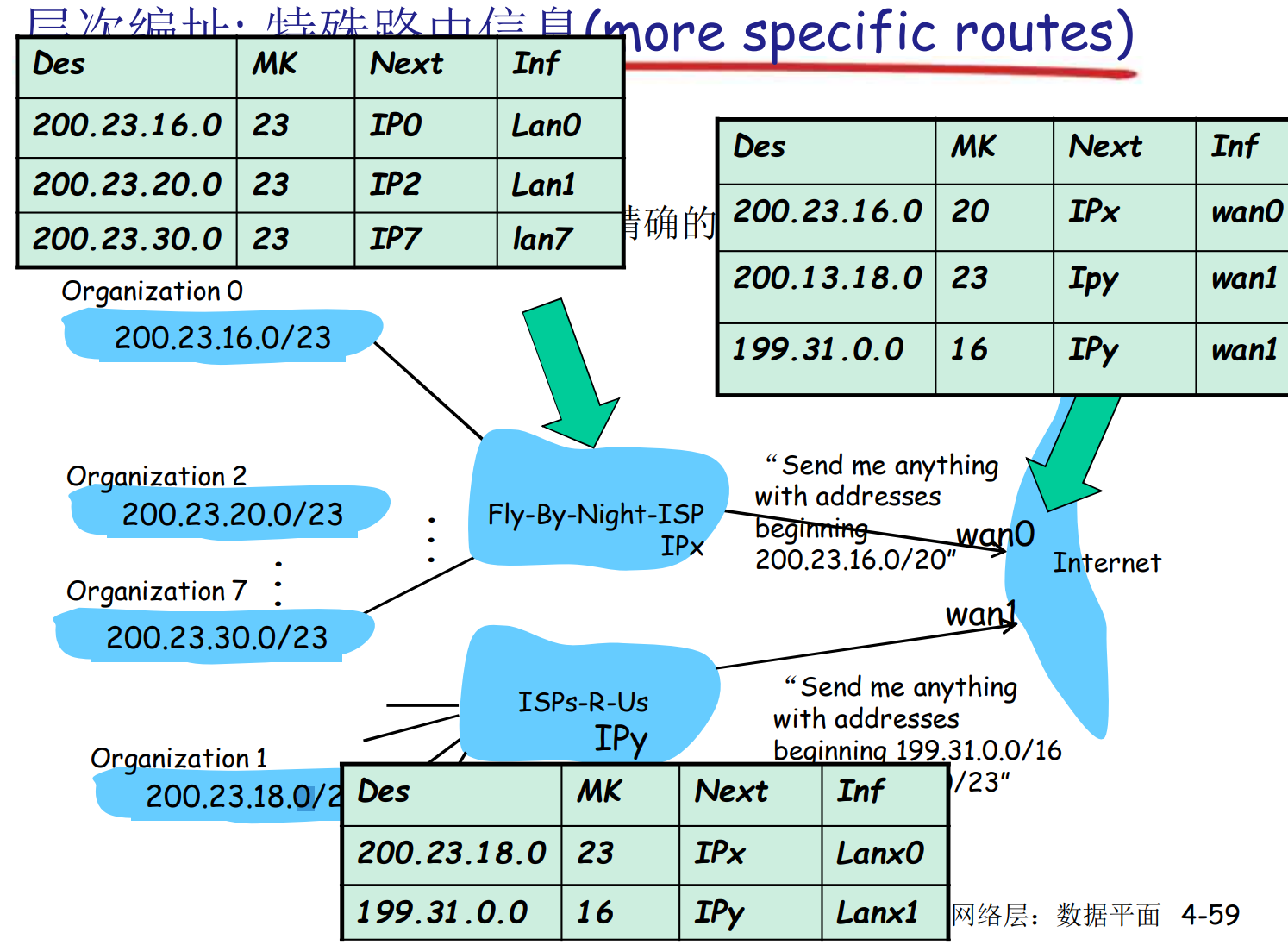
在夸大的过程中, 应该尽可能少夸大, 防止造成路由黑洞, 吸引大量处理不了的信息. 同时, 应该配置丢弃处理不了的数据包, 防止在网络中回环, 造成更多问题
NAT: Network Addr Translation
由于IP地址匮乏, 或者安全考虑, 多个内网设备共享一个出口公网IP
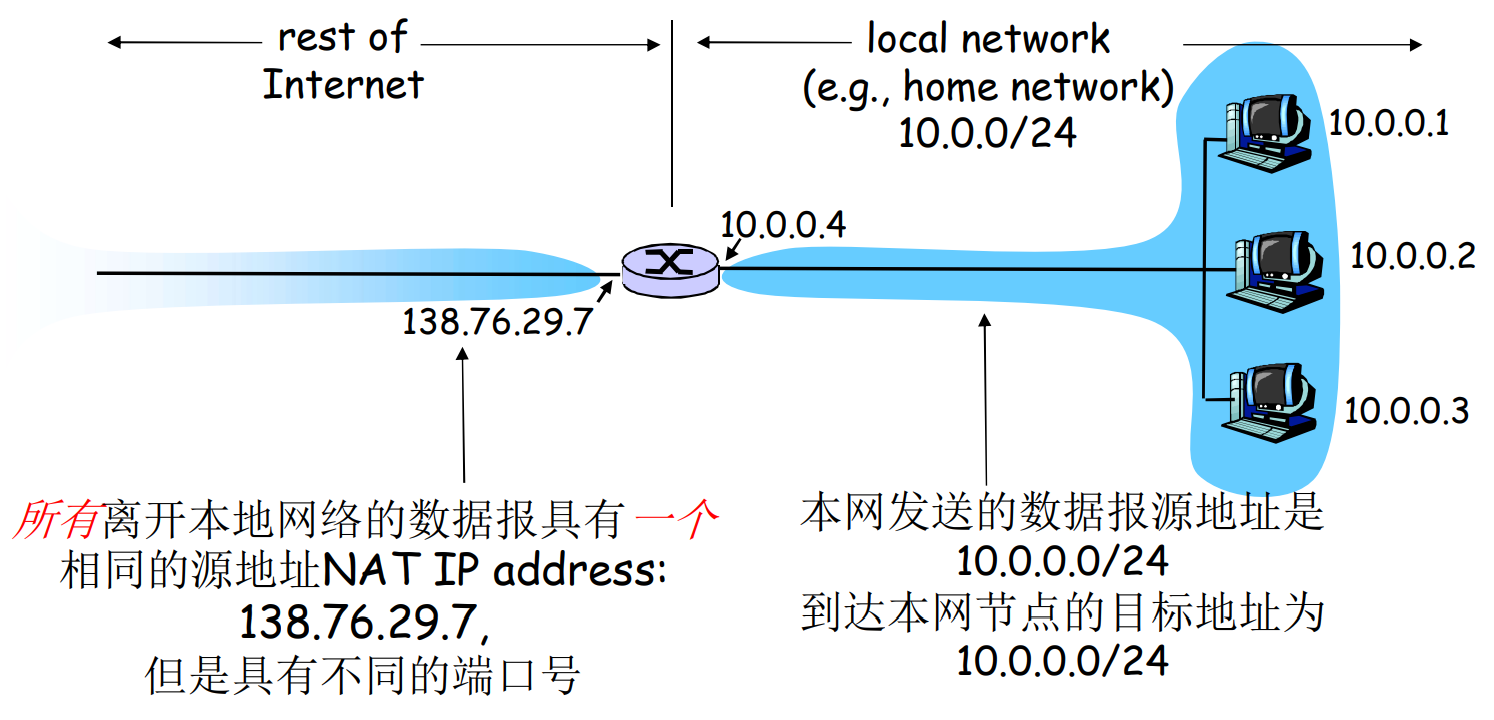
支持NAT的路由器
- 外出数据包: 替换源IP, 源端口号为自己的IP和端口号Port
- 在NAT转换表中, 记录转换信息
- 收到数据包: 检查端口号, 查表转发内网
NAT有一定争议
- 路由器是第三层设备, 但是修改了第四层的信息(端口号)
- 这违反端到端原则: 复杂性应该向网络边缘转移
IPv6
动机
- 32-bit地址空间已经被耗尽
- NAT转发时, 头部的checksum也要变, 加重了负担
IPv6特性
- 40字节头部固定
- 不允许路由器分片
如果分组过大, 路由器直接丢弃, 返回 ICMPv6 too big, 让源主机自行处理
在实际情况中, v6通过路径MTU发现(PTMTU)来确定瓶颈路径的MTU, 避免分片
IPv6 头部

和v4头部相比主要的变化
- checksum被去掉, 现在依赖其他层的检验
- TCP, UDP都有自己的checksum, 许多链路层协议(如CRC)也有自己的checksum
- options允许, 但是在头部之外用next header字段表示
- 新增ICMPv6: 新的报文类型, 多播组管理功能
v4 2 v6 升级
积重难返, 没有flag day了
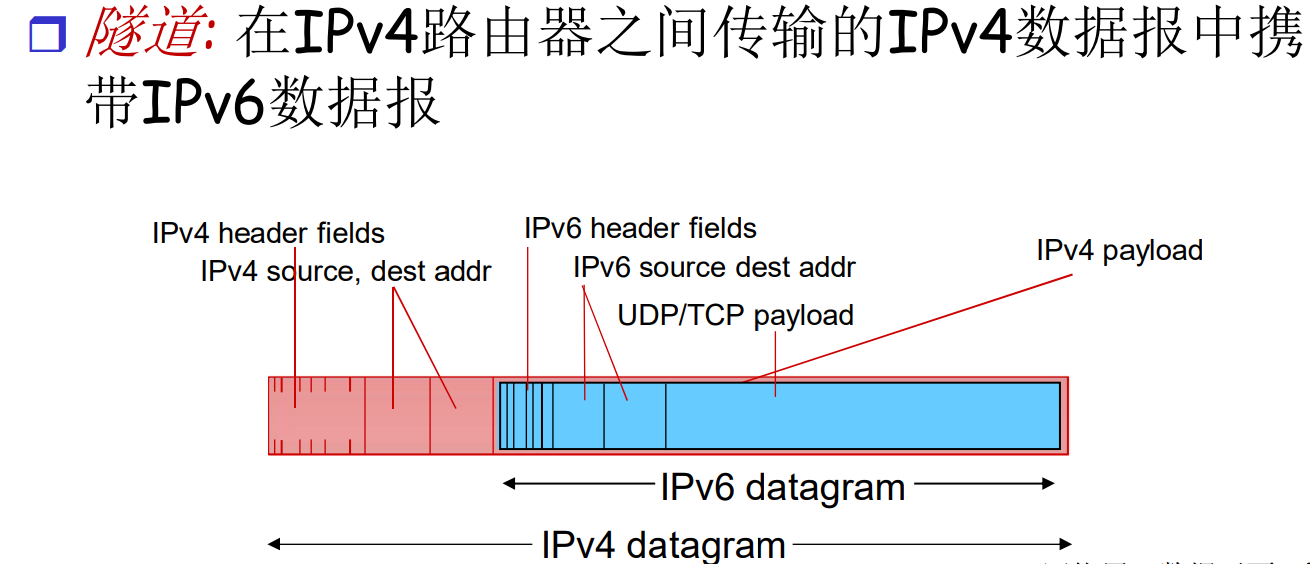
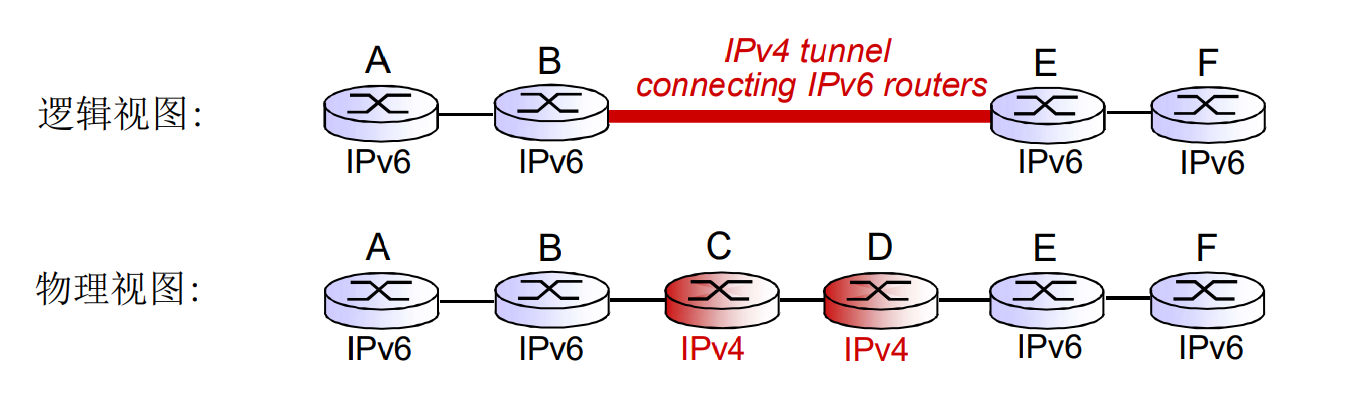
v4 v6混合时, 网络如何运转? 隧道技术: v6的岛屿间, 通过v4隧道连接. 随着v6的部署越来越广, 岛屿会越来越多, 直到统一v6
ISP需要维护双栈协议, 这会增加一部分开销
4.4 通用转发与SDN
数量众多, 功能各异的中间盒
路由器在网络层的功能
- IP转发(数据平面): 对于到来的分组匹配路由表规则决定如何转发
- 路由算法(控制平面): 和其他路由器交互, 计算路由表
其他种类繁多的网络设备(中间盒)
- 交换机, 防火墙, NAT, IDS, 负载均衡服务器, …
- 未来还有更多的部署
要改变上面分布式的设备的工作方式, 几乎不可能
路由器部署量太大, 规则固定, 没法改变
控制平面设备特点
互联网网络设备经常垂直集成
- 路由器, 路由器操作系统, 其他硬件必须整个厂商配套
- 厂商对标准协议(IP, RIP, BGP)等的私有实现
- 一整套产品被绑架
SDN方式, 软件定义网络
2005年之后, 考虑到上面的问题, 开始重新思考网络控制平面的处理方式
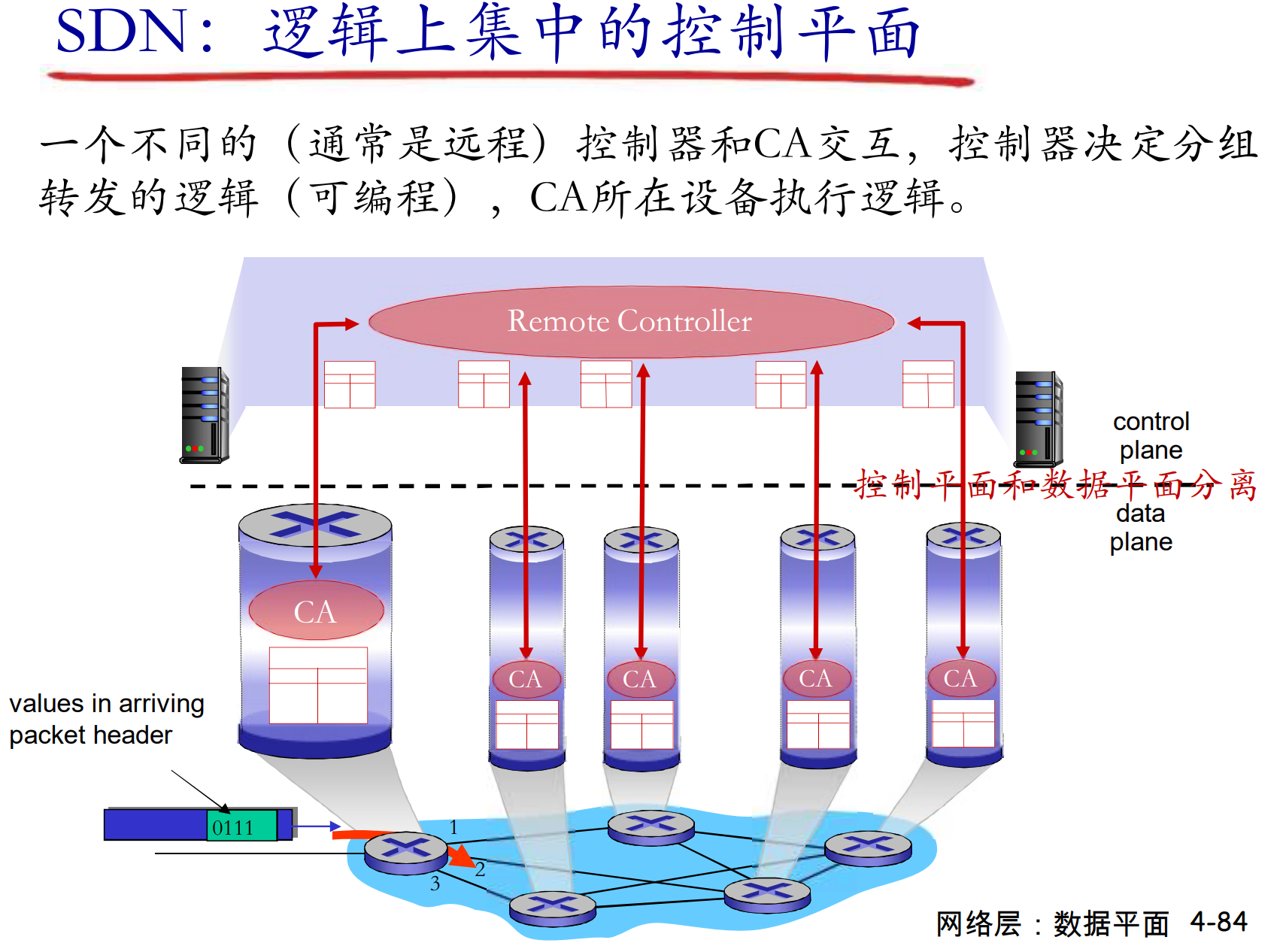
主要为了避免分布式的处理路由规则, 用集中化的服务器处理规则, 服务器用南向接口与路由器通信
只要符合协议, 各个厂商生产的路由器都可以接收流表, 上报状态, 成为可编程网络的一部分
SDN的主要思路
- 网络设备数据平面与控制平面的分离
- 路由器, 交换机等网络设备进一步抽象为: 按照流表进行PDU[帧, 分组]的动作[转发, 丢弃, 泛洪, 阻塞, …]
- 路由, 防火墙, NAT等功能都是网络应用(app), 下载下来就能部署
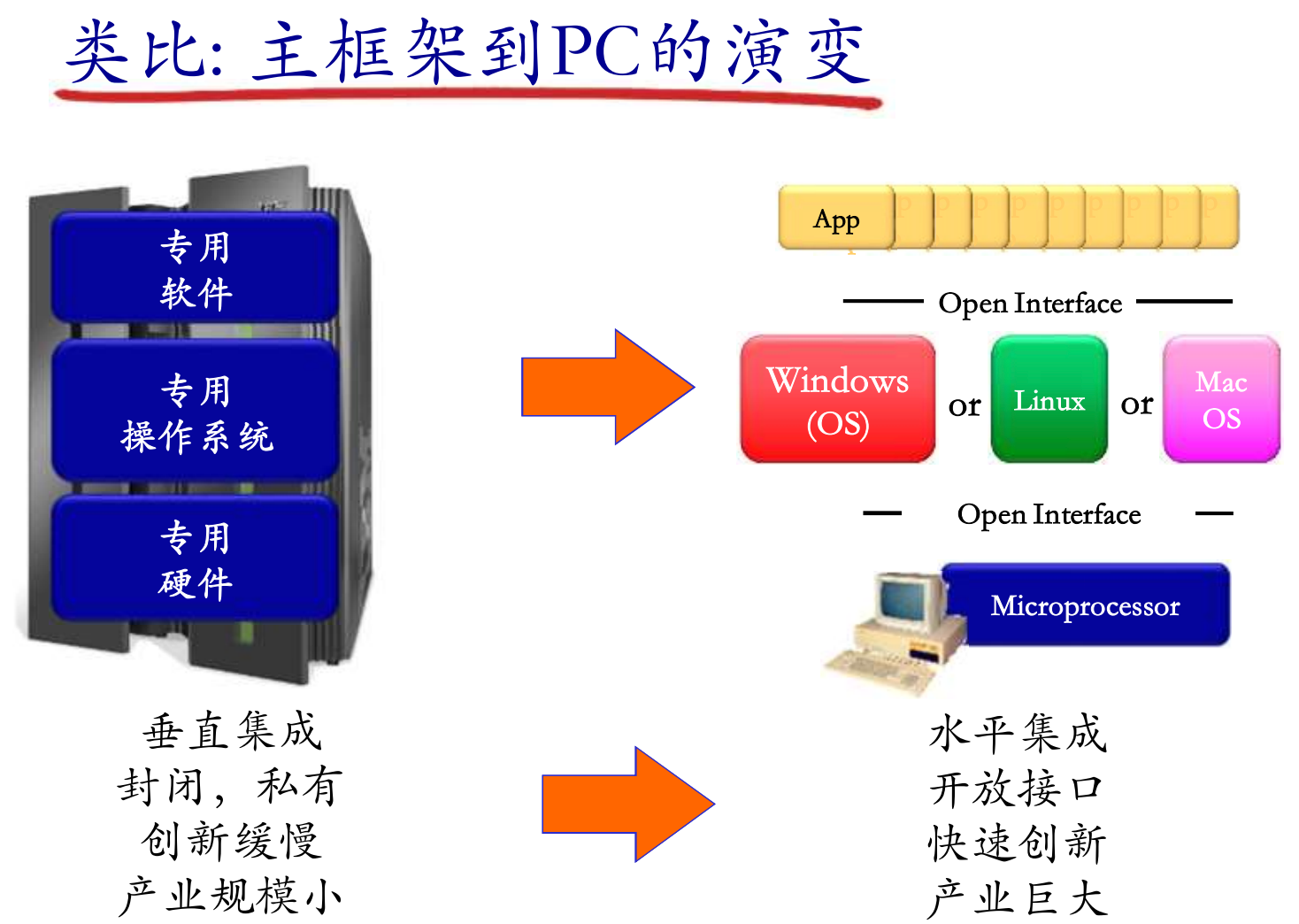
垂直的集成带来了垄断, 水平的集成会带来行业的繁荣

SDN交换机使用流表(Flow Table)来匹配网络流量。流表可以包含多个字段,包括:
- MAC 地址(Layer 2)
- IP 地址(Layer 3)
- 端口号、协议(Layer 4)

Chap5. 网络层: 控制平面
5.1 导论
网络层控制平面主要解决端到端路径的计算问题
- 转发: 数据平面
- 路由: 控制平面
传统路由选择算法, SDN方法
这些方法在互联网上的实现: OSPF, BGP, OpenFlow(SDN), ODL, ONOS, ICMP, …
5.2 路由选择算法
路由选择算法有两类:
- LS: link state
- DV: distance vector
什么是路由? 网络之间的连接非常复杂, 路由就是解决如何从一个主机到另一个主机到路径问题
网络层的路由是子网到子网的路由, 不可能计算主机到主机的路由(数量太大)
路由的定义

图的抽象: 路由是在一个带权图中, 给出源节点和目标节点, 算出符合某种指标的路径
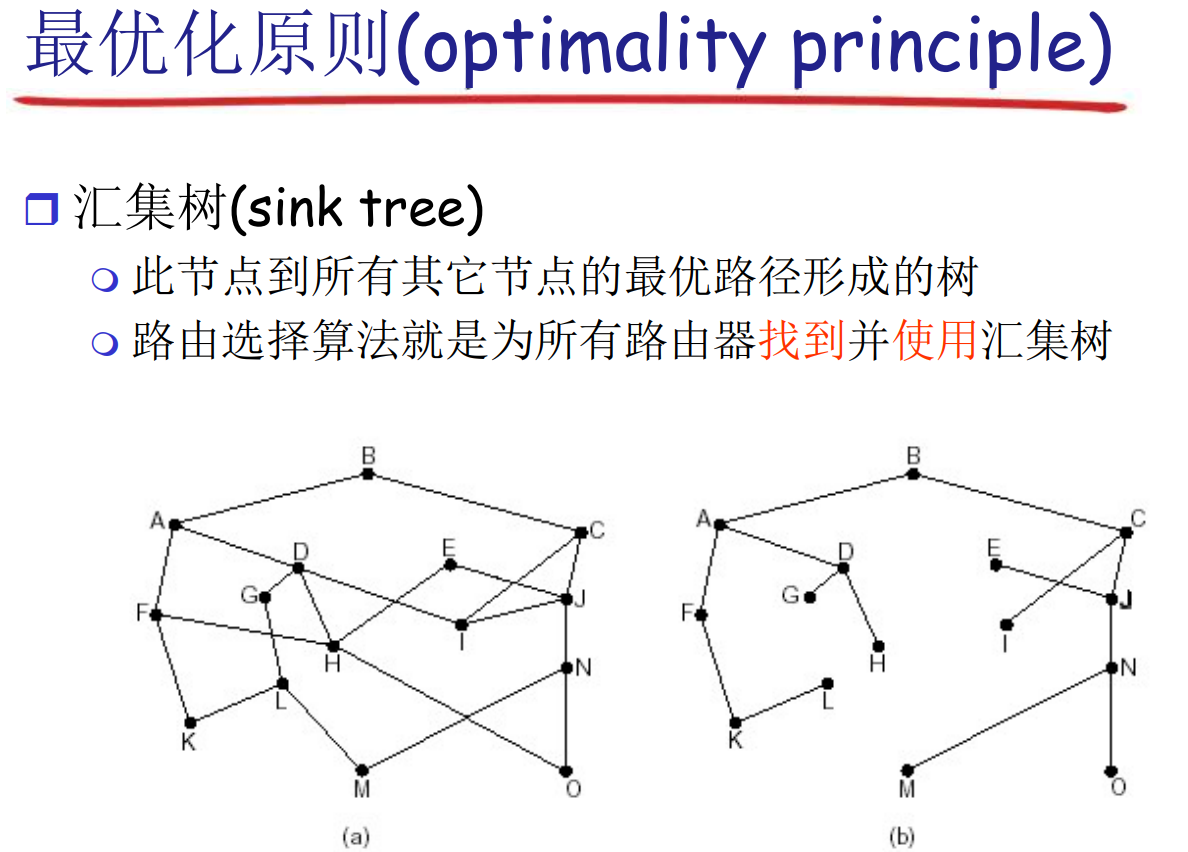
最优路径形成的一定是树, 不可能有环
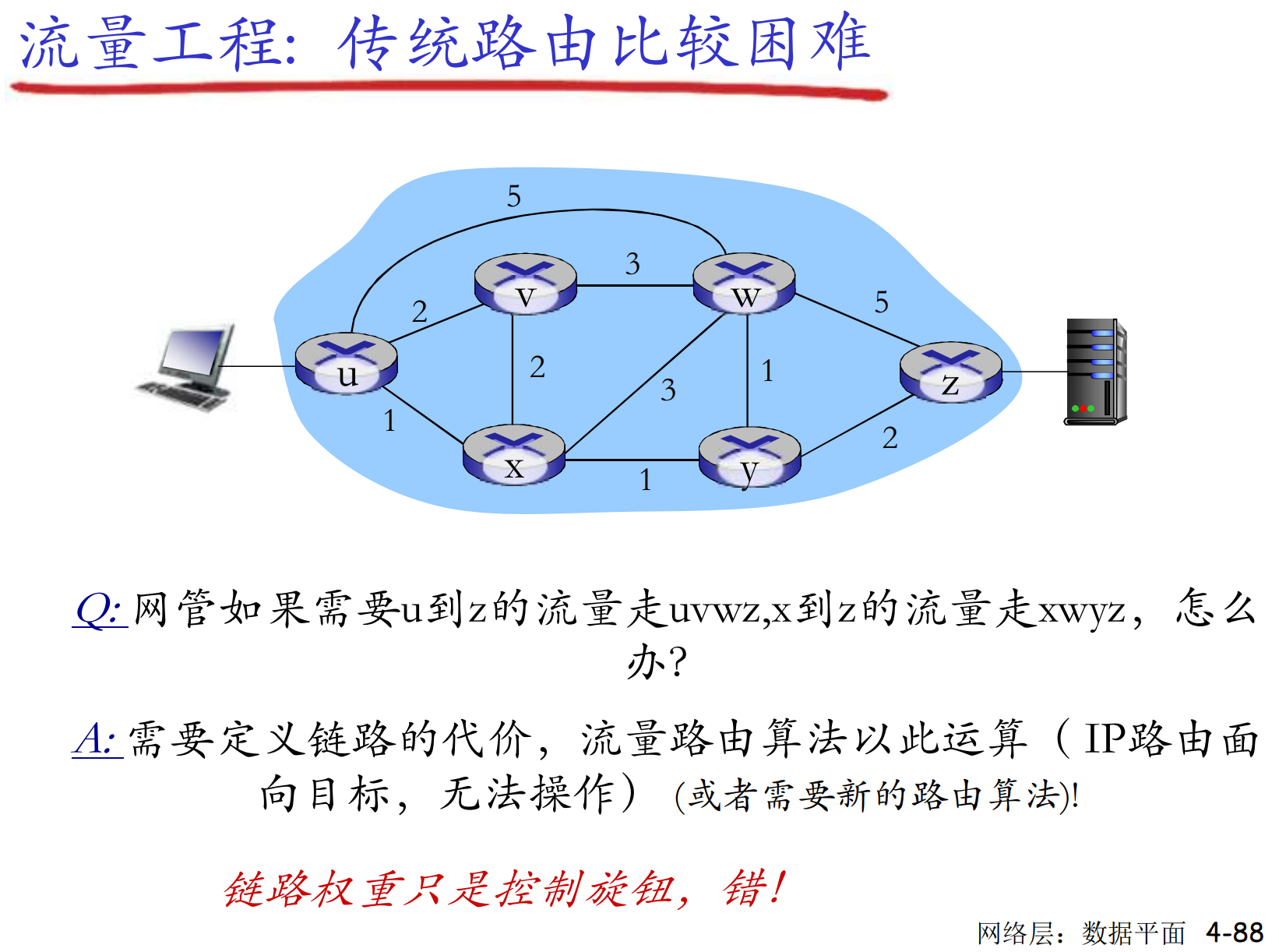
路由的原则
- 正确性: 必须保证路径有效且可达
- 简单性: 路由算法应该简单, 不用浪费大量时间找到最优, 而是花费少量实现找到较优
- 健壮性: 可以适应通信量和拓扑的变化
- 稳定性, 公平性, 最优性
路由算法分类
视角分类
-
全局视角: 路由器拥有完整的图信息(拓扑, 代价), Link State
-
分布式: 路由器只知道与它有物理连接的邻居相关的信息, Distance Vector
变化速度
- 静态算法: 事先计算好的路由表, 几乎不变
- 动态算法(大多数现代算法): 周期性更新, 自适应的
LS: 路由的工作过程
LS路由选择算法中, 路由器要得知整个网络的拓扑
- 路由器通过泛洪交流信息(这部分和算法无关, 属于协议和实现)
- 发现相邻节点, 获知对方网络地址
- 测试相邻节点代价(延迟, 开销)
- 组装LS分组, 描述本地到相邻节点的代价情况
- 局域网泛洪分组, 通知其他节点, 同时接收其他节点的信息
- 使用Dijkstra算法计算本地到其他网络的最优路径(汇集树), 得到路由表
- 按照路由表转发
FS: 泛洪交流细节
为了防止网络风暴, LS泛洪分组会设置TTL和版本号
此外, LS泛红是有确认的泛洪(可靠的泛洪), 如果收不到确认, 会重复发送, 其目的是必须让所有节点收到可靠信息
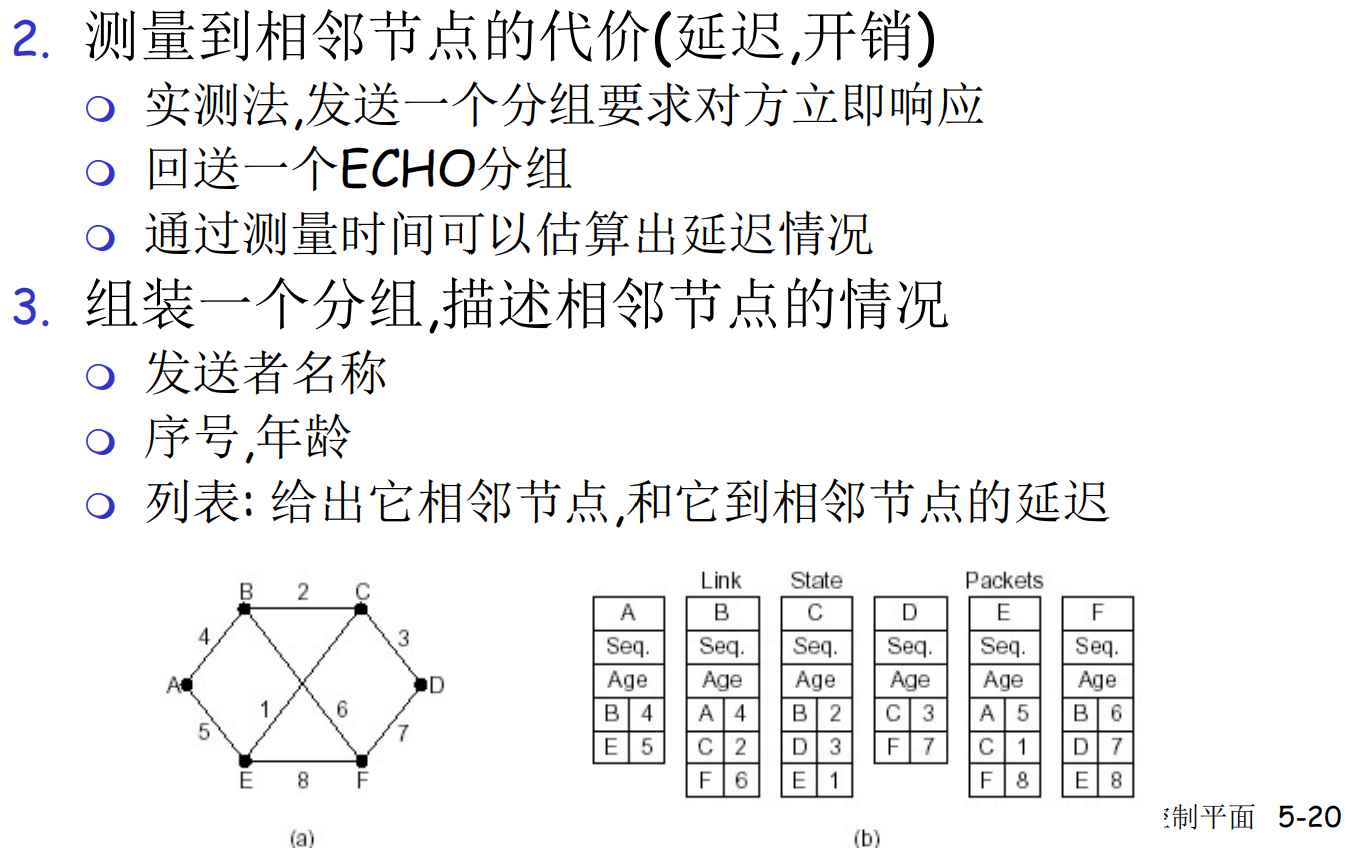


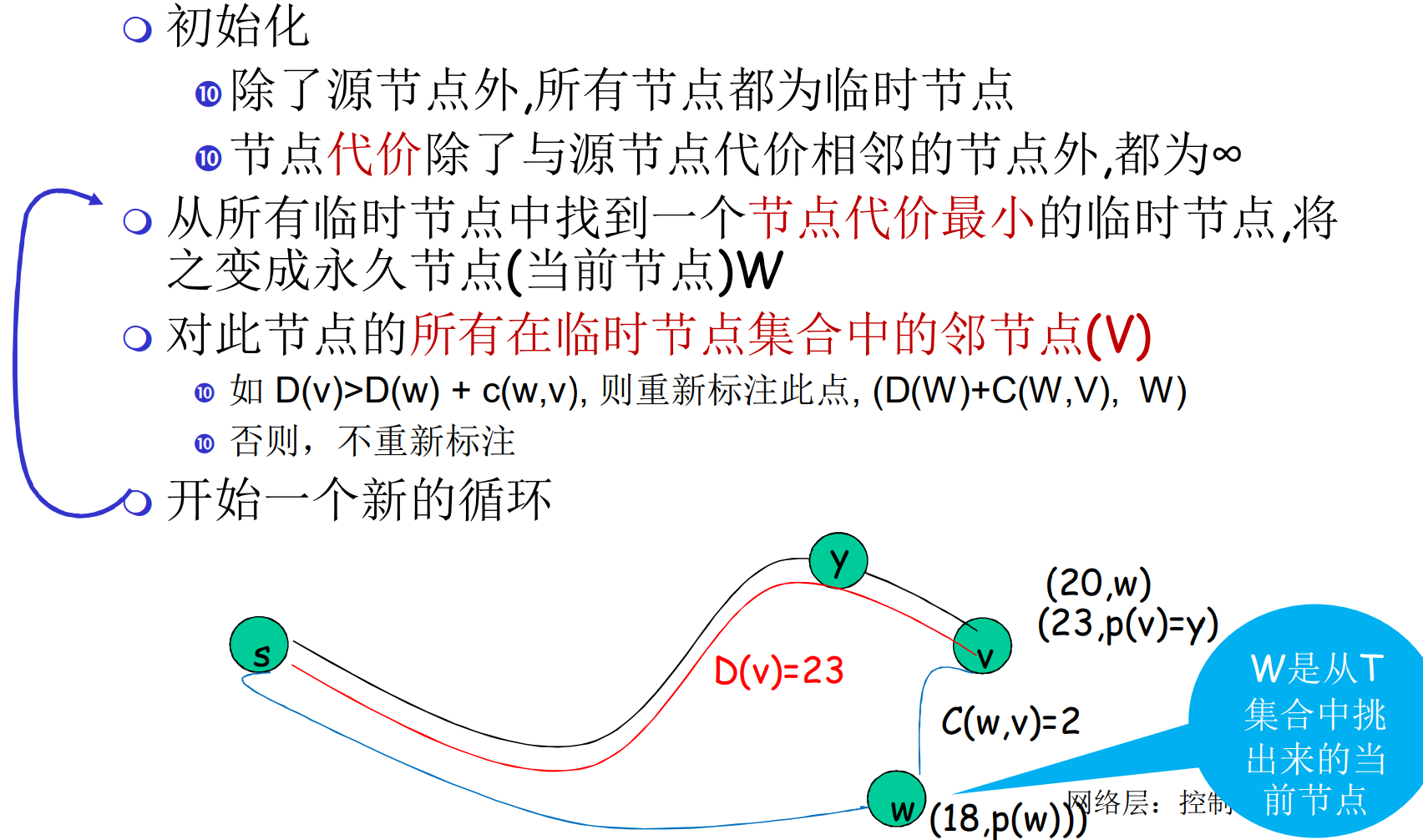
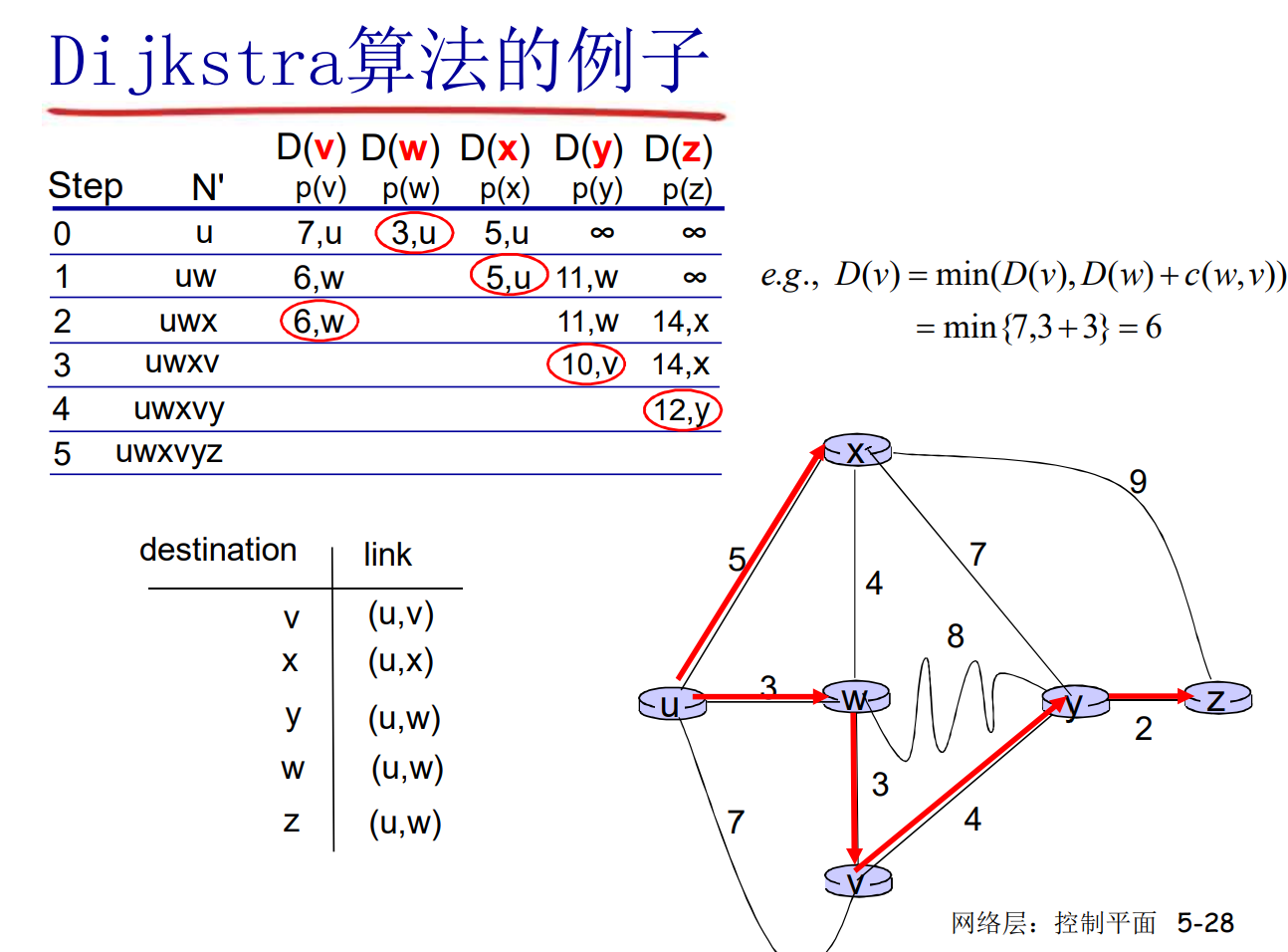
LS: Dijk计算最短路
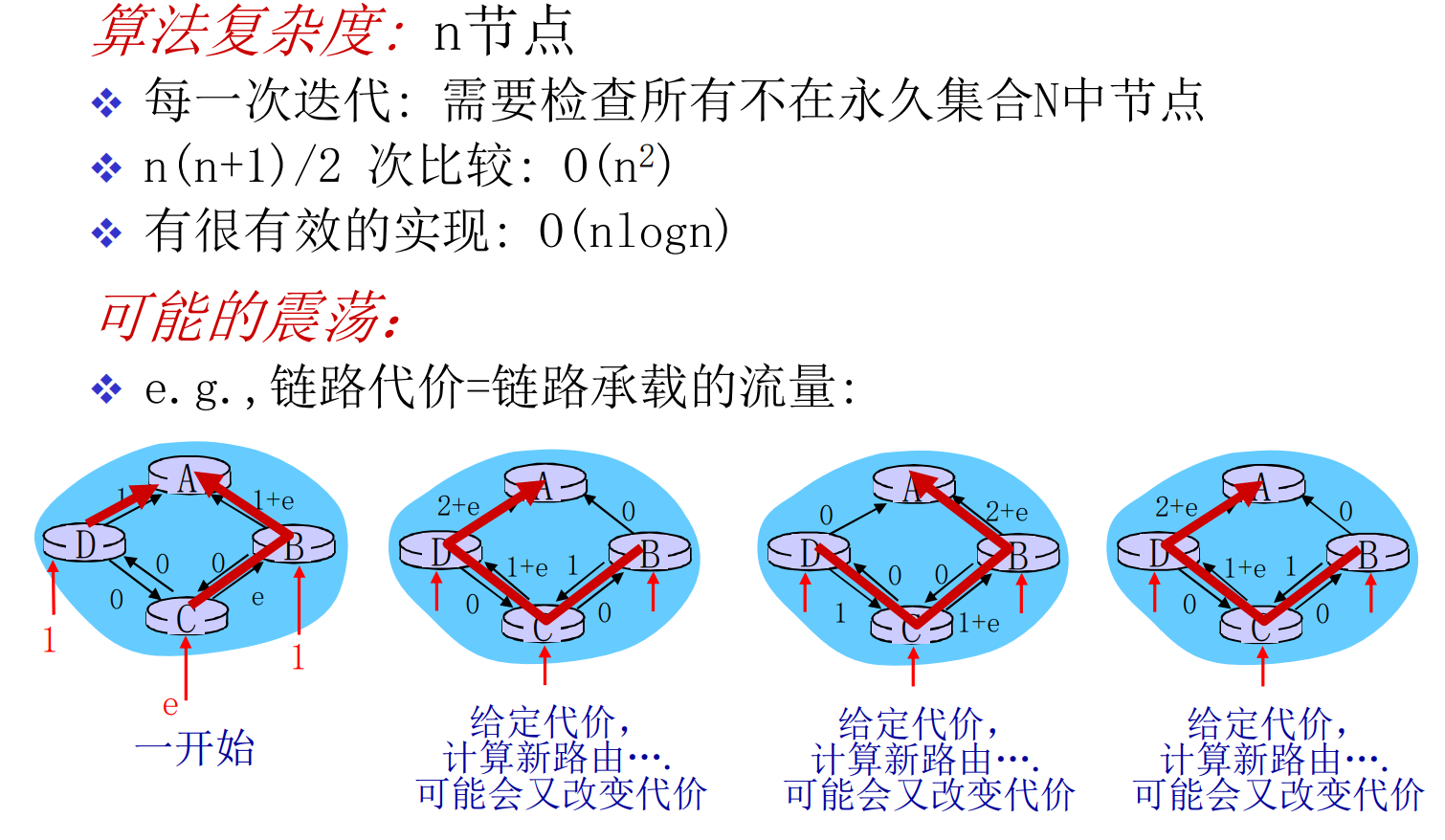
如果你在想, 这是不是只是朴素的Dijk, 答案是正确的, 一点没变, 甚至是N^2的Dijk, 原汁原味


DV算法: 基本思想
复习: DV算法(Distance Vector Routing), 动态路由选择算法之二, 之一是上面说的LS算法(Link State)
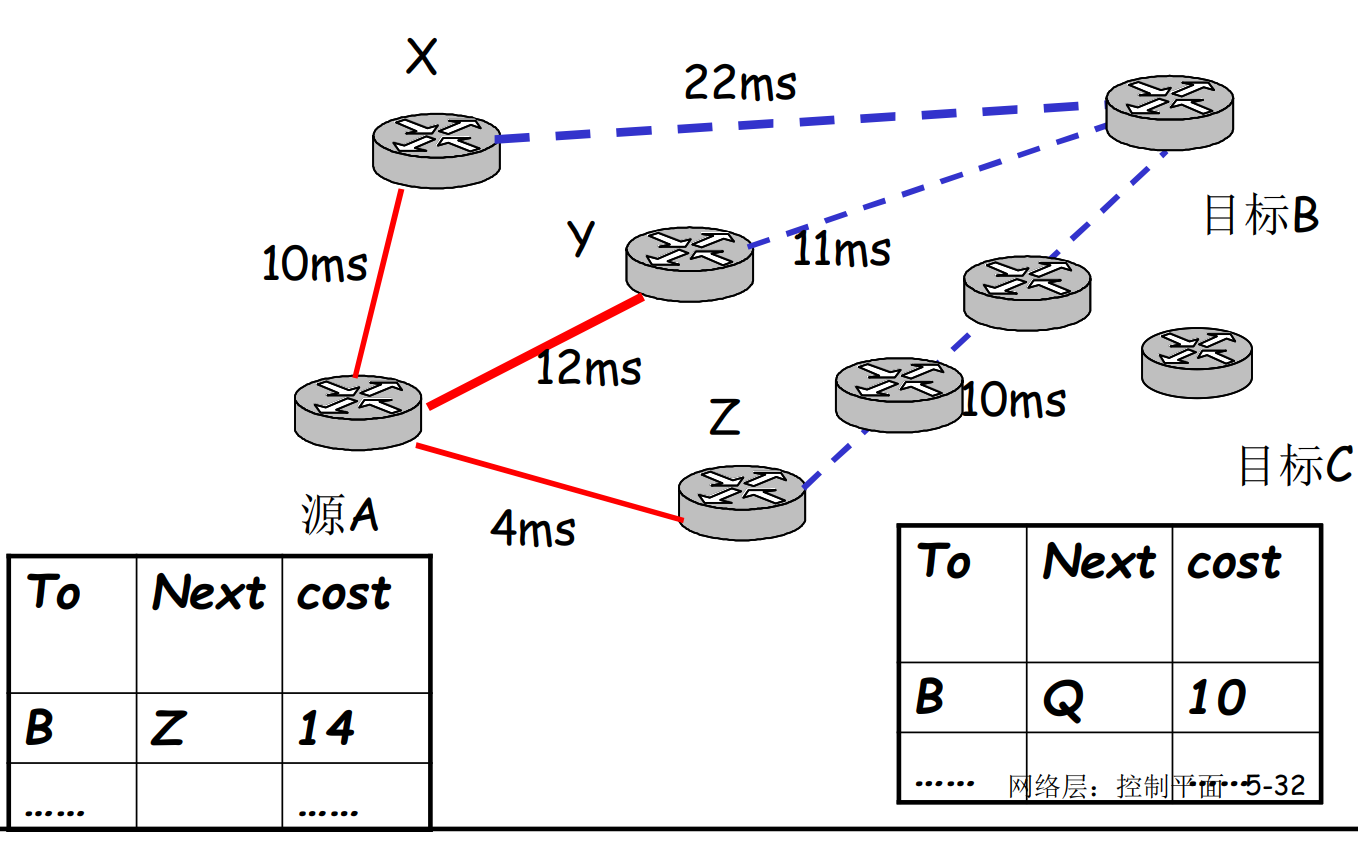
- 各路由器维护一张表, 结构[To, Next, Cost], 以子网为单位
- 各路由器与邻居定时交换路由表
- 根据获得的信息更新路由表
见下图A, 通过XYZ的信息更新自己的路由表, 其中交换的信息被称作距离矢量
DV是异步的, 迭代式的算法, 要通过多轮迭代才能收敛到实际值
- 相邻节点的代价通过实测得知
- 其他节点的代价通过通告得知
触发本地更新路由表的事件有
- 本地链路代价变化(和邻居的连接质量改变)
- 收到了邻居发来的DV

DV的特点: 好消息传得快, 坏消息传得慢
在下图中, AB最开始是断开的, 某个时刻突然联通了, 则B最先得知, c(A)=1, B开始广播

在下图中, AB最开始是连接的的, 某个时刻突然断开了, 则B最先得知B->A不可达, 但是C会声称A可达(虚假的, C要通过B才能达到A)
C虚假的声称会让B以为B->C->A可达, 此时形成了环路(环路的解决应该用TTL)
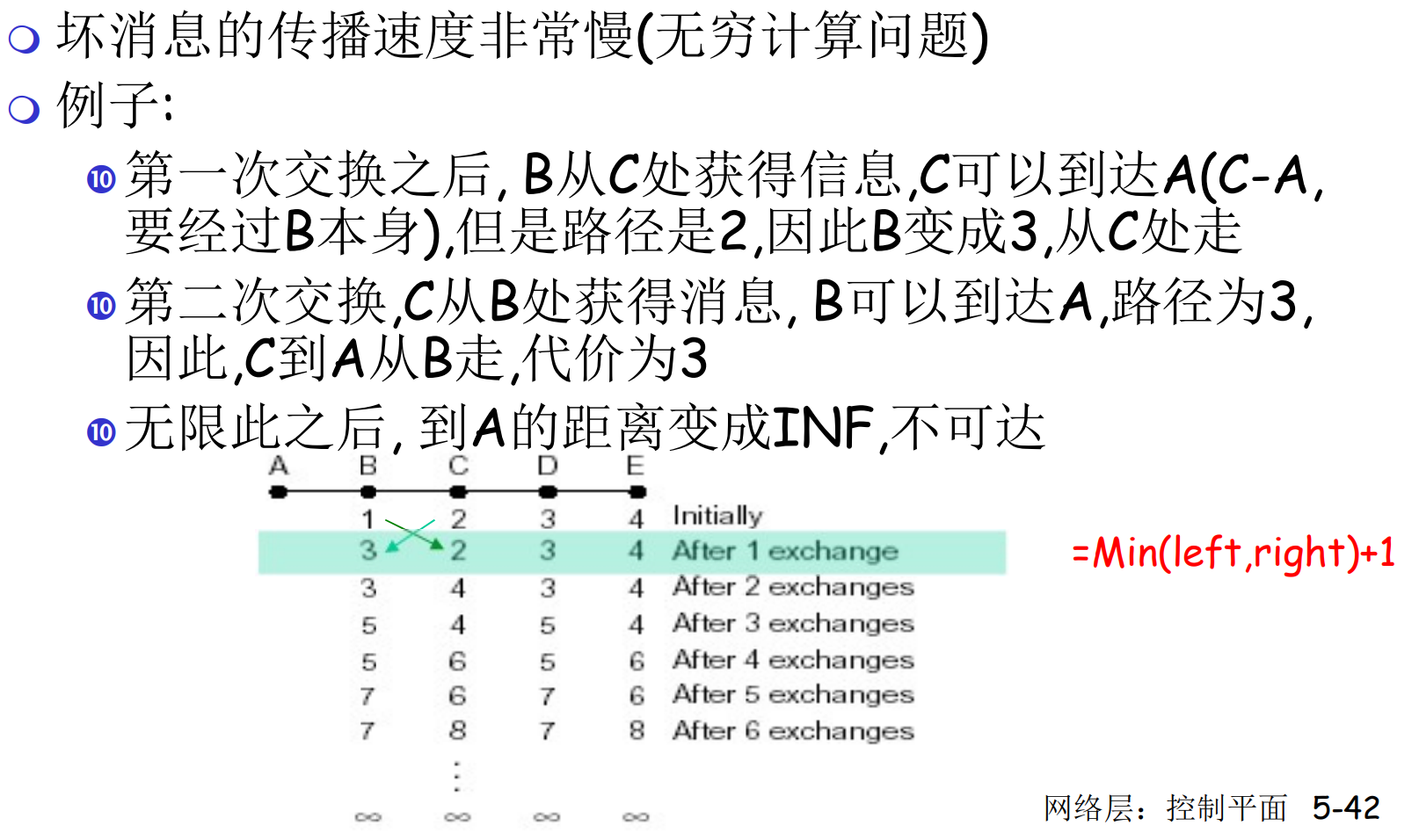
在上图的情况下, 会经过很多次推演, 才能知道A不可达
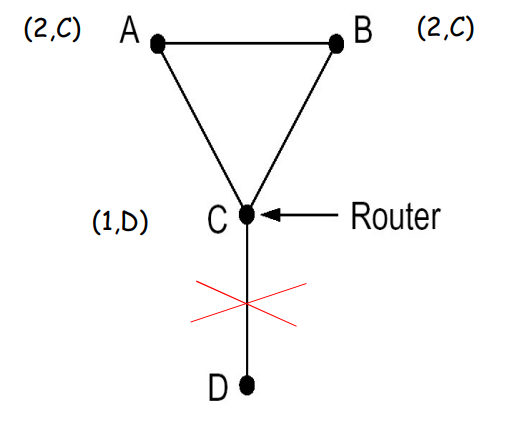
DV: 水平分裂算法
水平分裂算法用来减缓上面的坏消息传播慢与环路问题(注意, 不是解决)
水平分割的基本思想是: 一个路由器不会向它学到某条路由的接口再次通告这条路由

在上图中, 体现为: A和B断联了, C知道, 自身连接A要通过B, 所以B是A的权威信息来源, 则, C交给B关于A的DV是谦虚的(生成自己不可达). 但同时, C在交给D关于A的DV时, 交付真实值, 这是因为D要通过C给A发消息, C相对于D更加权威
C将A的信息分裂成谦虚和不谦虚的两份传播, 这就是水平分裂算法
下图中的例子, D不可达的消息仍然需要很多轮迭代才能被网络认识到
DV算法: 实例
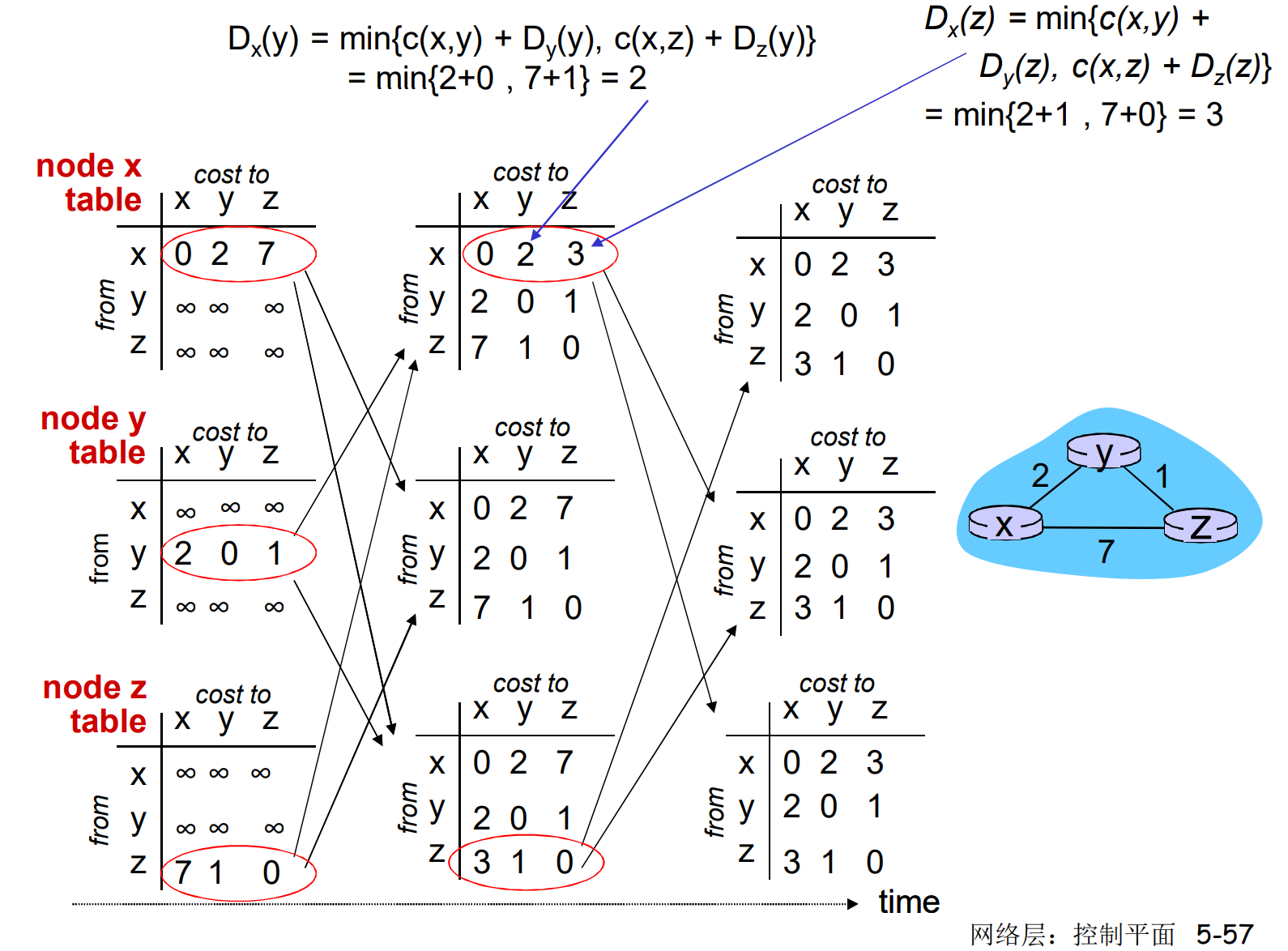
每次迭代都要调用bellman-ford方程
上图中经过3次迭代, 网络收敛到了真实情况
LS vs DV

5.3 自治系统内部的路由选择: RIP & OSPF
也叫内部网关协议, 主要有两种: RIP, OSPF
算法比较抽象, 协议更具体一些
RIP: 基于DV的协议实现
- 采用了跳数作为代价, 最大代价=15, 16表示不可达
- 每30s交换一次DV, 对方请求则立即交换
- 每个通告最多包含25个目标子网(RIP是用于小网络的协议)
下面描述一个RIP实例, 请看D路由器的路由表, 注意代价是hop
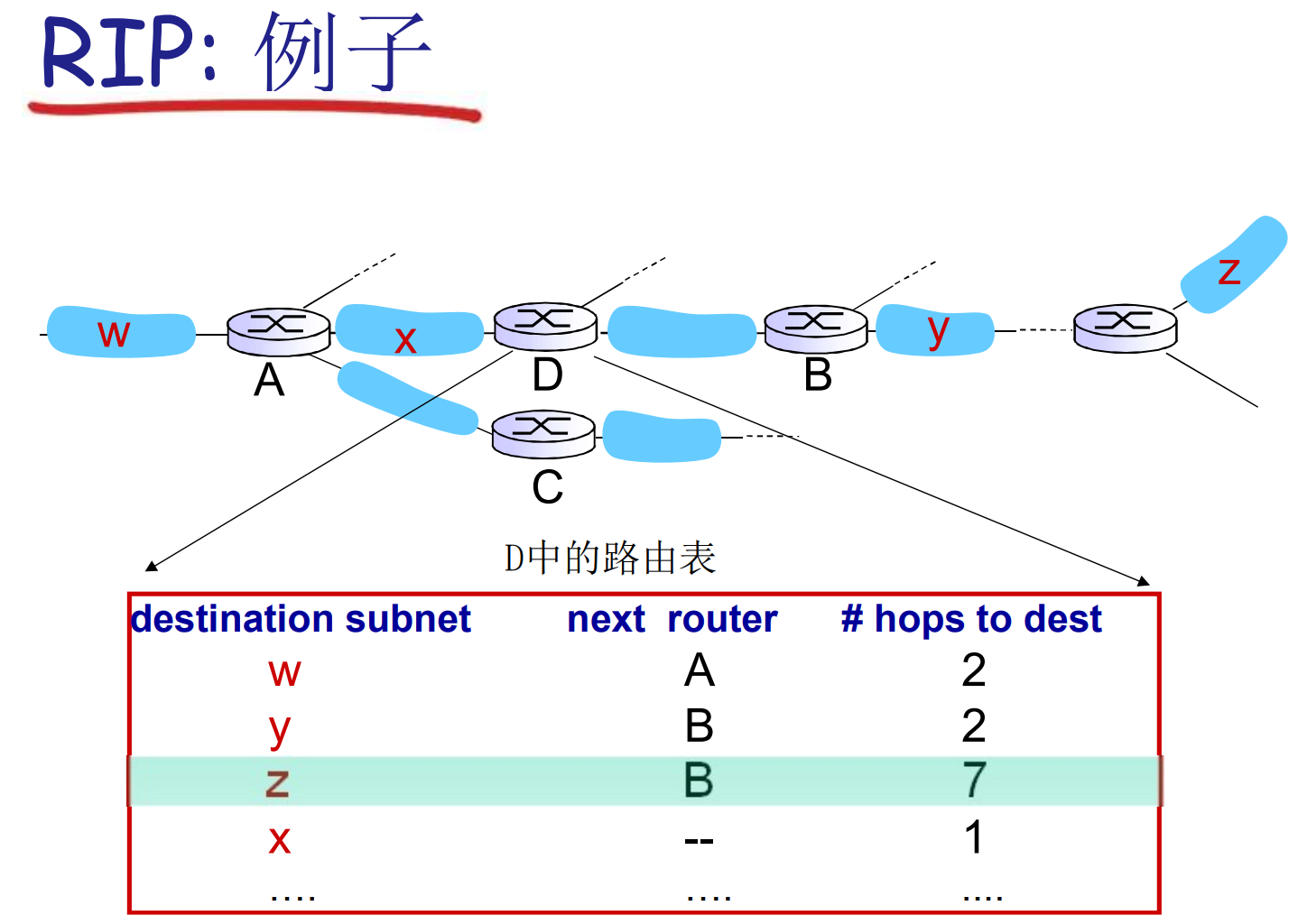
D的路由表在收到A的DV后更新
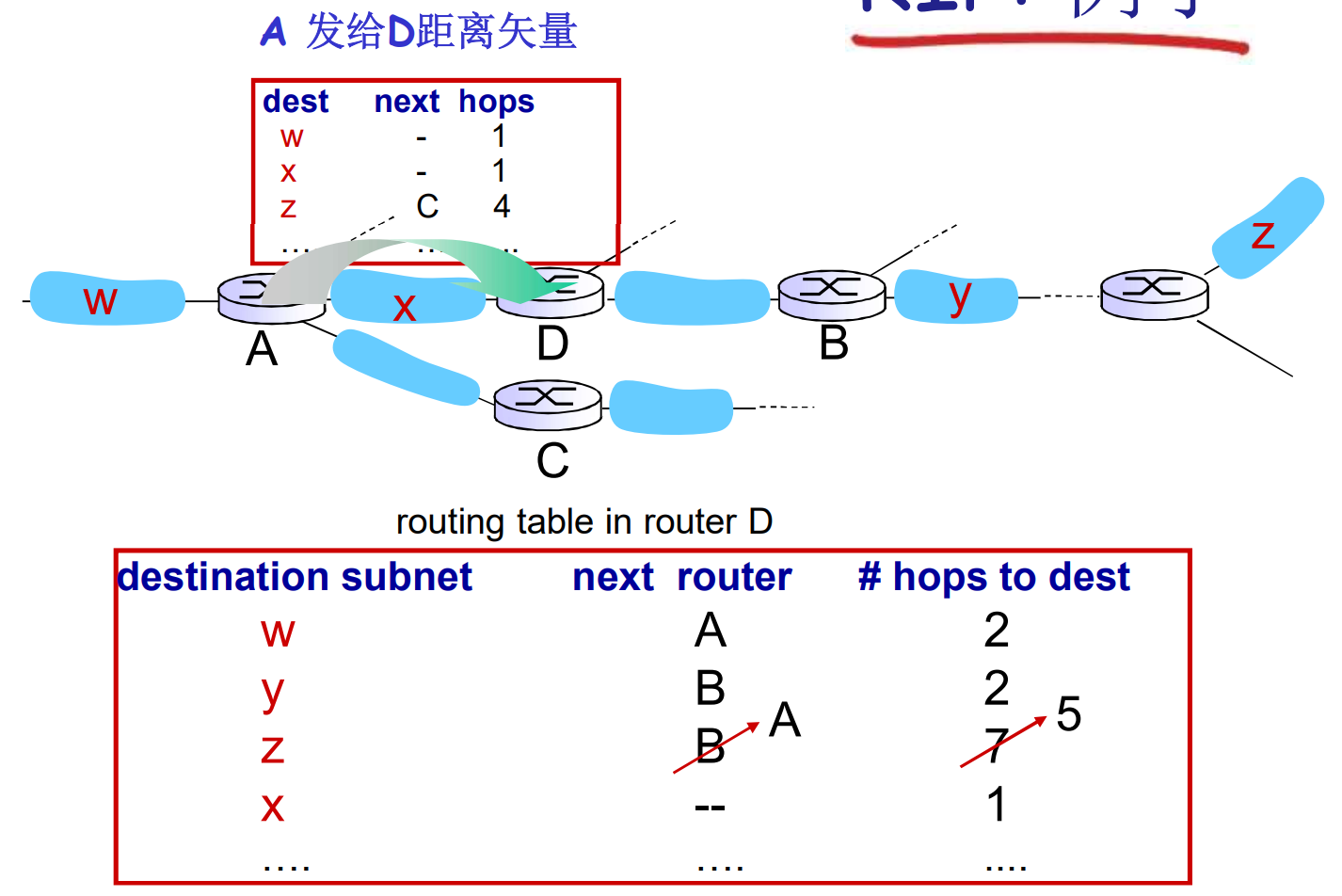

毒性逆转属于水平分类, 上面介绍过
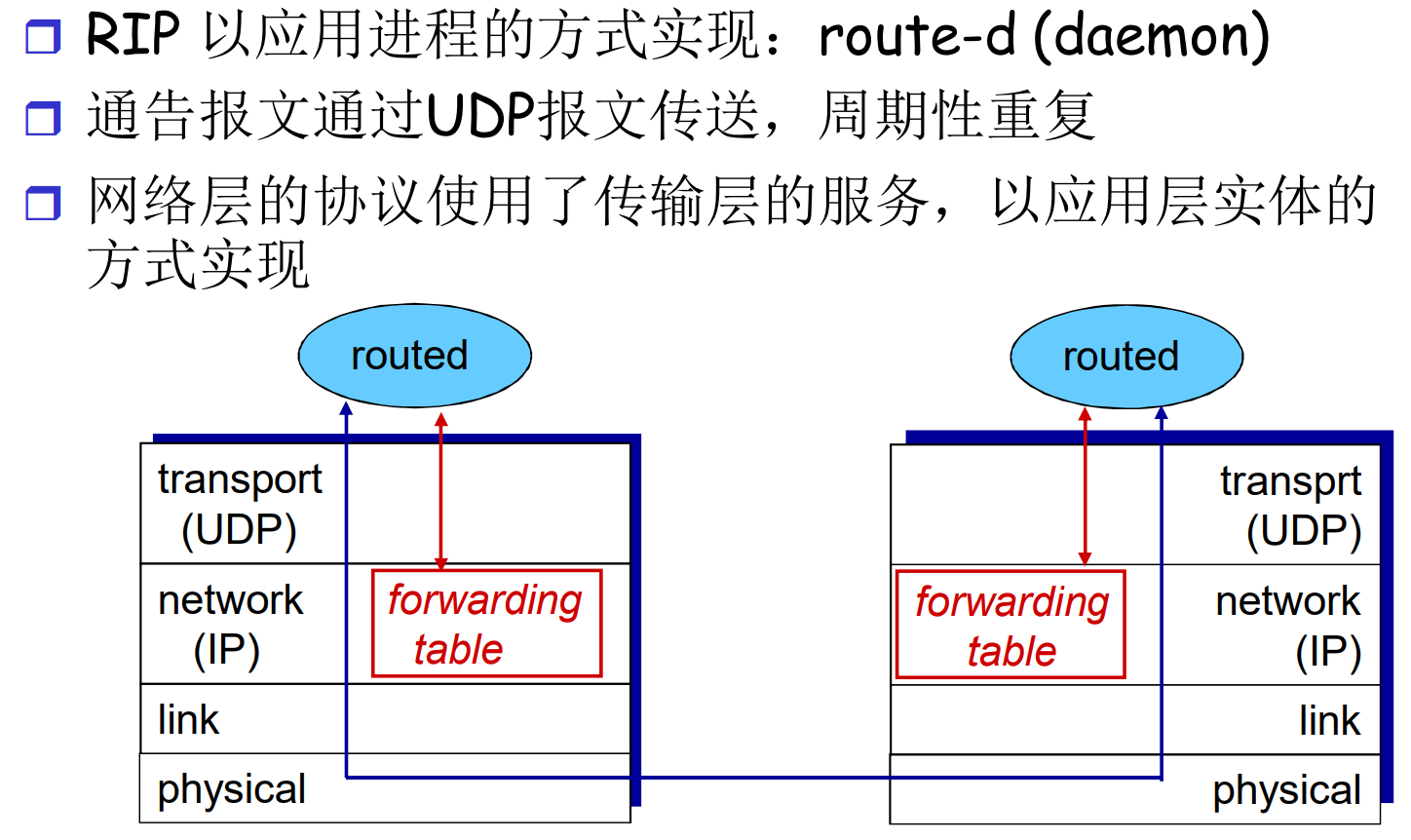
RIP的通讯报文是UDP的, 封装在IP数据报中发送
OSPF: 基于LS的协议实现
- LS算法
- LS泛洪分组在网络中(一个AS内部)分发
- 每个节点维护全局网络信息(拓扑+代价)
- Dijk计算最段路
- OSPF通告携带: [本地IP, 通告版本, 本地到邻居的代价]
- OSPF通告会在AS泛洪
名次解释: AS, Autonomous System, 自治系统, 是OSPF协议中, 逻辑上对于某个共享路由策略的网络的称呼
OSPF的通讯报文是IP数据报, 不使用任何传输层协议
OSPF有很多高级特性, 以下是RIP没有的
- OSPF有安全特性
- OSPF允许两条代价相同的路径, 而RIP不允许
- OSPF允许多重代价(多种指标的最优路径, 跳数? 拥塞程度? )
- Multicast OSPF支持多播协议
- 在大型网络中支持层次的OSPF(区域内泛洪)
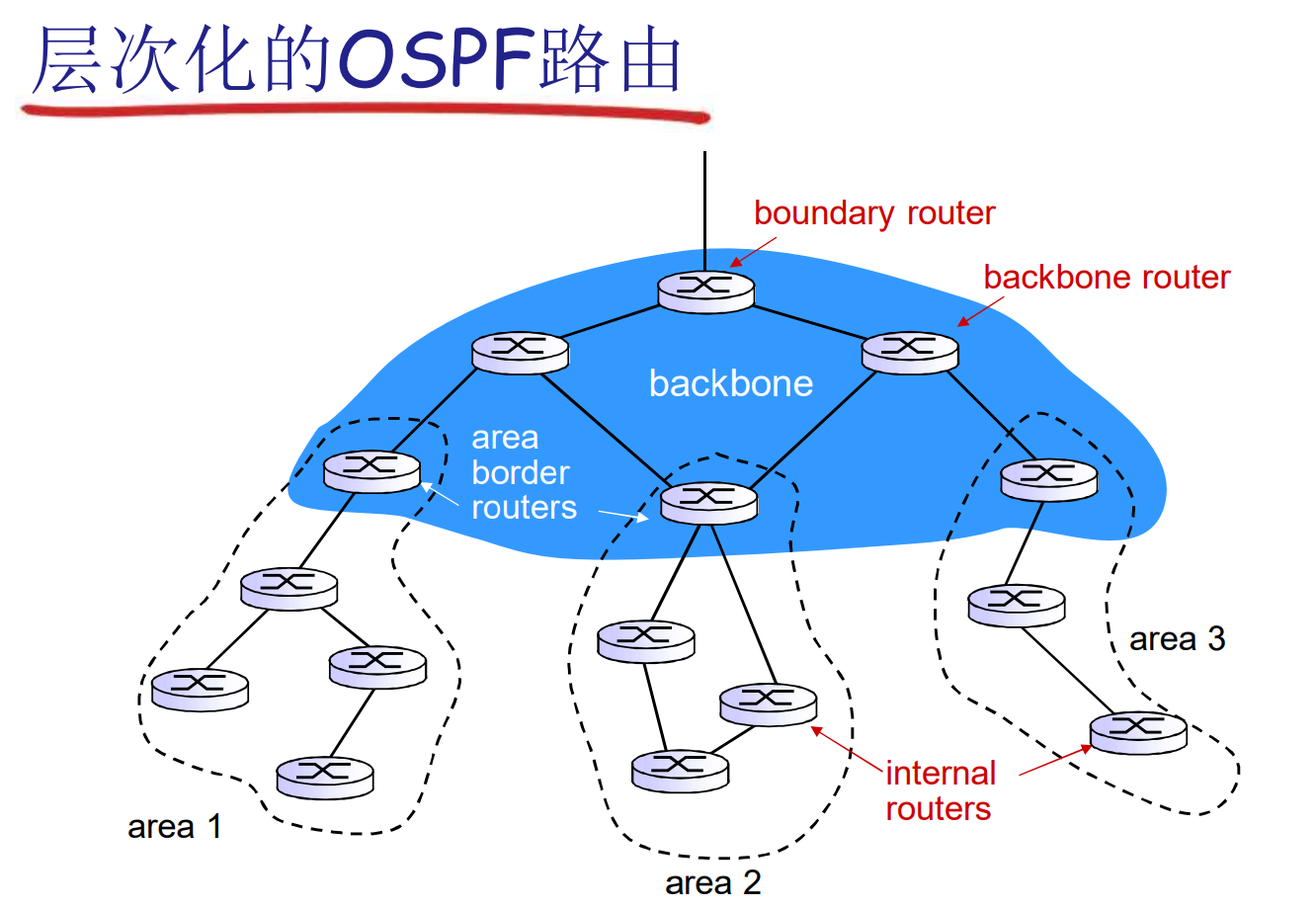
5.4 ISP之间的路由选择: BGP
上面的LS, DV, 都是解决一个平面的路由问题
- 所有路由器地位一样, 通过交流确定路由策略
在互联网的数量级上, 因为节点过于多, 不能采用平面的路由算法
- 各个网络内部也需要隐私性, 自己规定自己的路由算法
层次路由: AS
互联网将网络分成了若干自治区(AS), 每个AS有一个编号, ASN
AS是路由逻辑上的, 除互联网本身外最大的路由尺度单位, 大数量概有10万级别
- AS内部路由自治, 运行同一种路由协议(比如OSPF, RIP, 无所谓)
- AS对外只需宣称一条子网可达信息
- AS之间的路由, 每个AS都是一个点
实际上AS内部也可以继续分层, 运行多种路由协议
知名的AS有Google, FaceBook, 中国电信等, 也有一些比较小型的
对于AS内部, 有丰富的路由协议, 比如RIP, OSPF, 还有一些私有协议, 比如思科路由器
网关路由器, 边界路由器: 连接AS之间的路由器
AS之间的路由: BGP协议
BGP协议是事实上的协议, 不是规定的, 而是自行发展出的
- 将AS粘在一起的浇水
每个AS可以执行
- eBGP: 从相邻的AS获取子网可达信息
- iBGP: 将获得的子网可达信息传给AS内部的所有路由器
路由器通过子网可达信息和策略决定到达子网的路径
- 子网可以主动通告自己的位置
- 基于改进的DV算法, 不仅仅是距离矢量, 还包括详细路径(AS序号列表), 避免了DV算法的路由环路问题
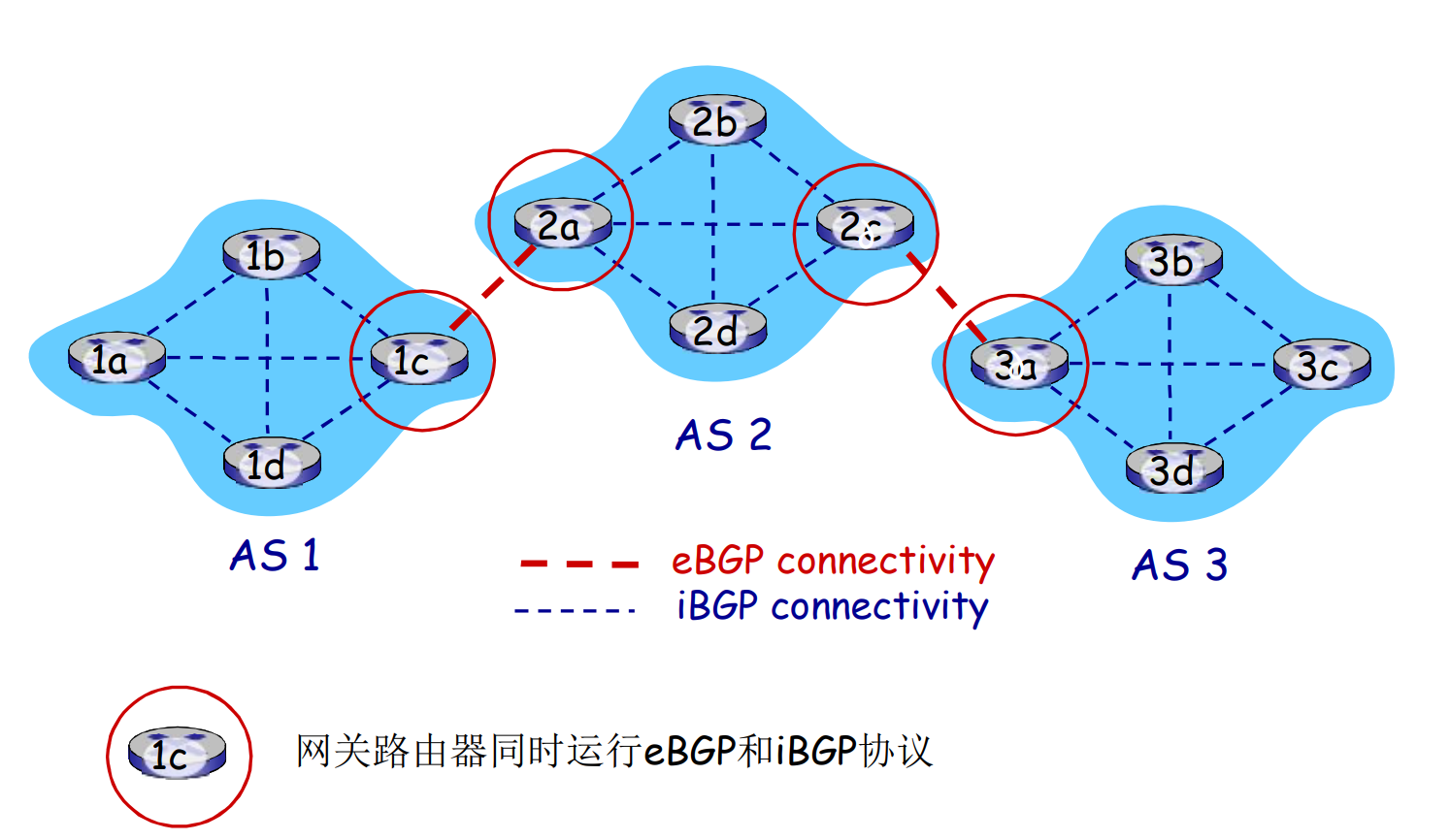
- 1c, 2a, 2c, 3a是网关
- 网关一方面收集AS内的子网可达信息, 另一方面向外通告
BGP基本原理
下文的BGP会话, 包含eBGP和iBGP
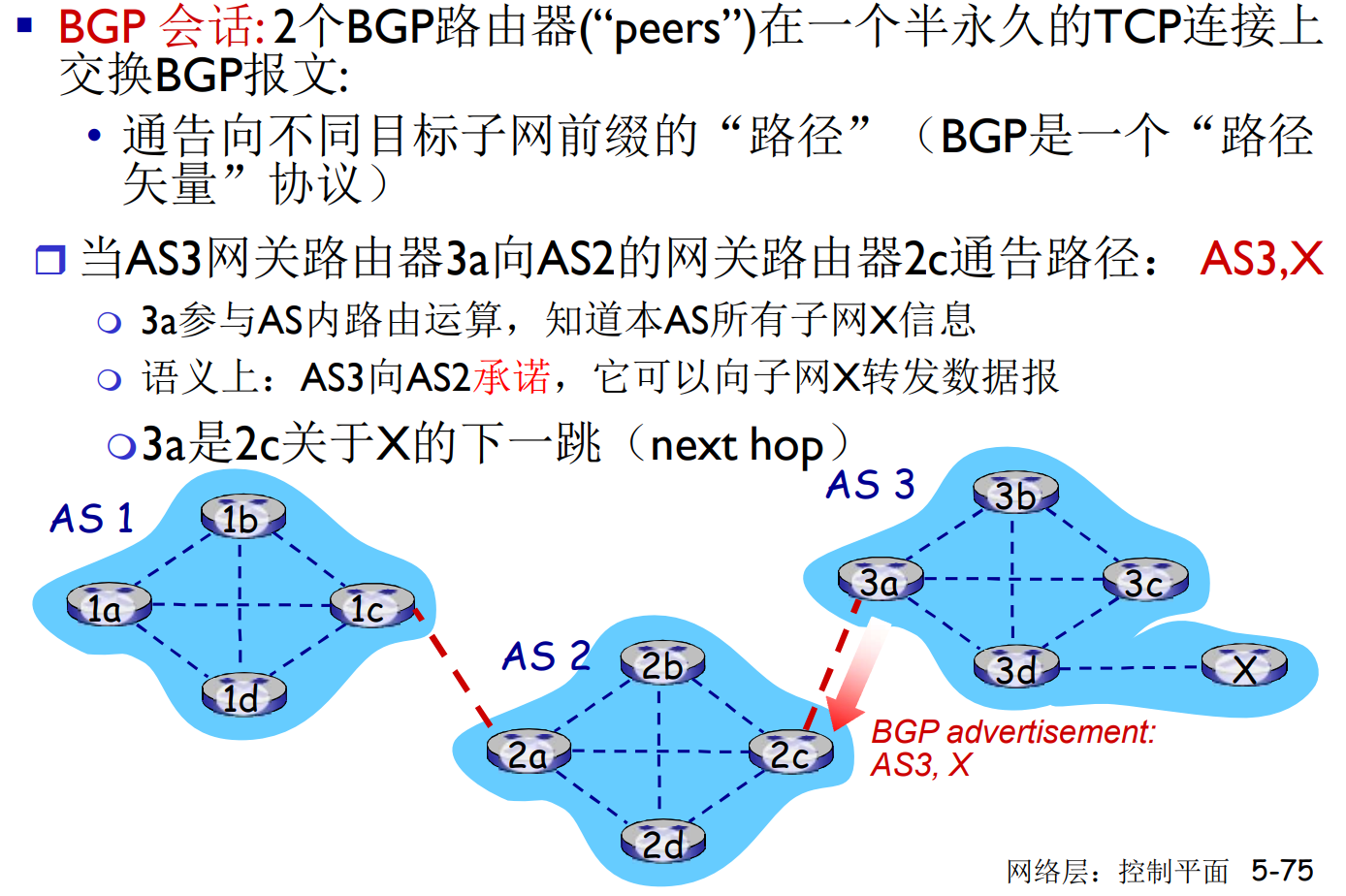
BGP通告(BGP- advertisement): 这些子网的消息你可以转发给我(我可以作为下一跳), 同时包含了途径的AS信息(这是DV没有的), 和下一跳目标
AS内部的路由关注性能, 但是AS之间的路由很强调策略(政治策略, 经济策略, 字面意思的)
- 不想经过某个AS
- 必须经过某个AS
边界路由器会根据策略接受/拒绝eBGP通告, 此外, 还要决定是否要转发
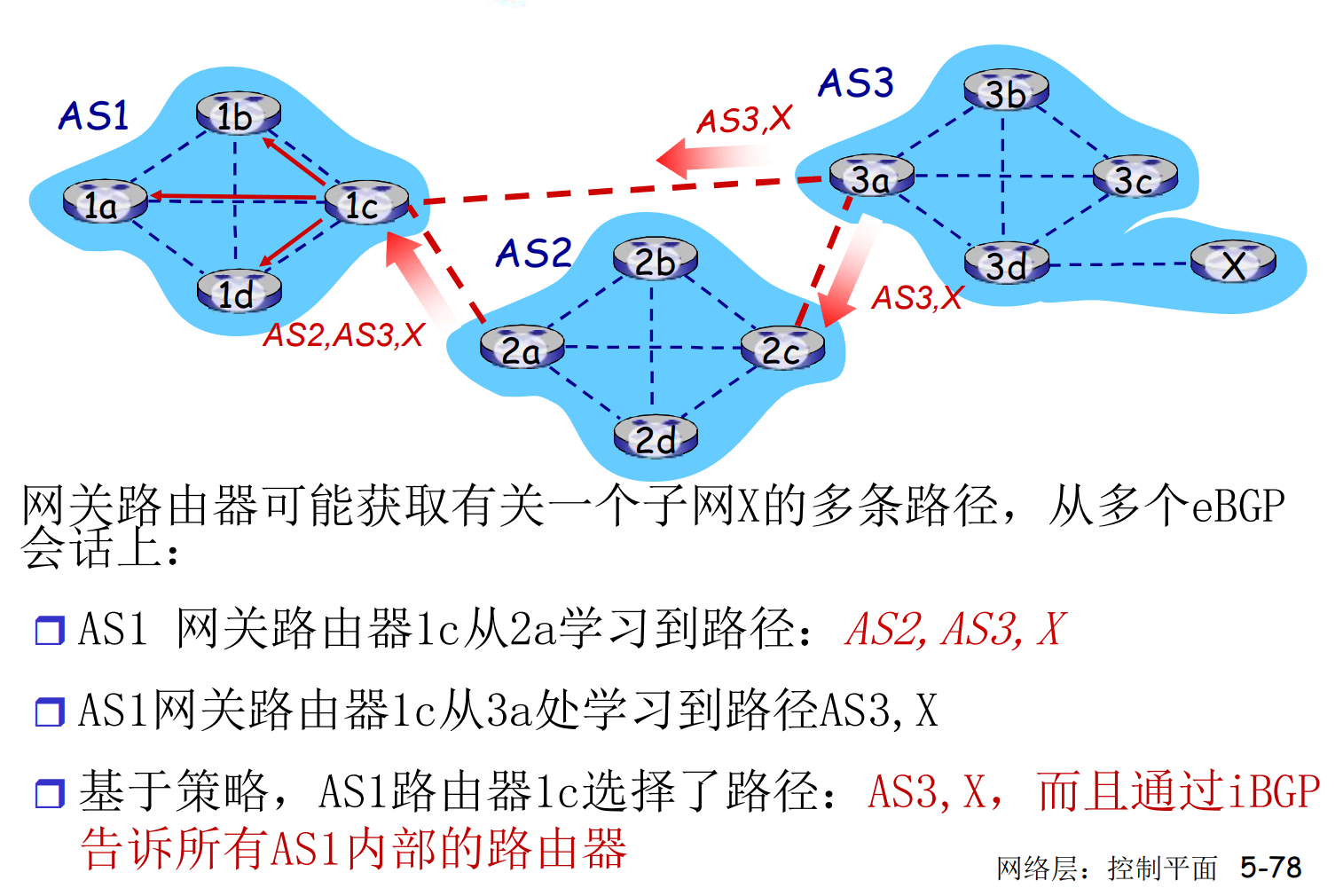
BGP协议通过TCP协议交换报文, 需要维护路由器在线状态
区域内的子网可达信息, 是由iBGP, eBGP共同决定的
BGP: 路径选择
路由器会获得到达一个子网前缀的多个路径, 通过多种内部算法决定选择哪一个
- 内部偏好设置
- 最短AS跳数
- 最近Next-Hop: 热土豆路由, 不操心AS间代价
5.5 SDN控制平面
和前面讲的一样
5.6 ICMP: 互联网控制报文协议
主要是主机, 路由器, 网关的网络控制信息
- 错误报告: 地址不可达, 连接超时, …
- Echo请求和回复: ping
ICMP在网络层, 但是在IP协议的上方
Chap6. 链路层与局域网
为什么叫链路层与局域网(LAN)? 因为广域网(WAN)的链路层比较简单
我们先学习LAN和WAN通用的链路层功能, 再讲解LAN独有的部分
- 广域网一般是点对点的(海底光缆)
- 局域网一般是多点的(Wi-Fi)
和前面的部分一样, 我们先学习原理, 再介绍实践
6.1 引论和服务
规定一些术语:
- 节点(nodes): 主机, 路由器, 交换机, 网桥, 都是节点
- 链路(links): 沿着通信路径,连接相邻节点通信的信道
- 有线链路, 无线链路, 等
- 帧(frame): 链路层的协议数据单元(PDU)
链路层解决的是点到点的功能, 相比之下, 网络层解决的是端到端的功能
链路层: 在相邻两点间, 传输以帧为单位的数据
不同的跳中, IP分组可能封装在不同类型的帧中(链路层协议). 路由器收到帧后, 会提取其中的IP分组, 根据转发目标的MAC协议, 重新封装一个帧
- 第一跳: 以太网
- 第二跳: 帧中继链路
- 第三跳: 802.11
链路层服务
- 成帧: 数据报被封装在帧中, 装上帧头部, 帧尾部
- 接入: 如果采用共享性介质, 接入时分配使用权
- 可靠(部分): 比如802.11要求确认
- 光纤, 双绞线, 这样的可靠介质很少用
- 无线经常用, 出错率太高了
- 流量控制: 发送, 接收方速度匹配
- 错误检测与恢复
- 半双工与全双工
只有部分链路层服务是可靠的, 所以网络层不可靠
链路层在哪里实现: 网卡
每一个主机, 路由器, 交换机的网卡上
-
路由器, 交换机有多张网卡
-
以太网卡, 802.11网卡, …
网卡也叫网络适配器(Network Adapter), 实现了链路层和相应的物理功能, 和主机系统总线连接
网卡是软件, 硬件, 固件的集合体
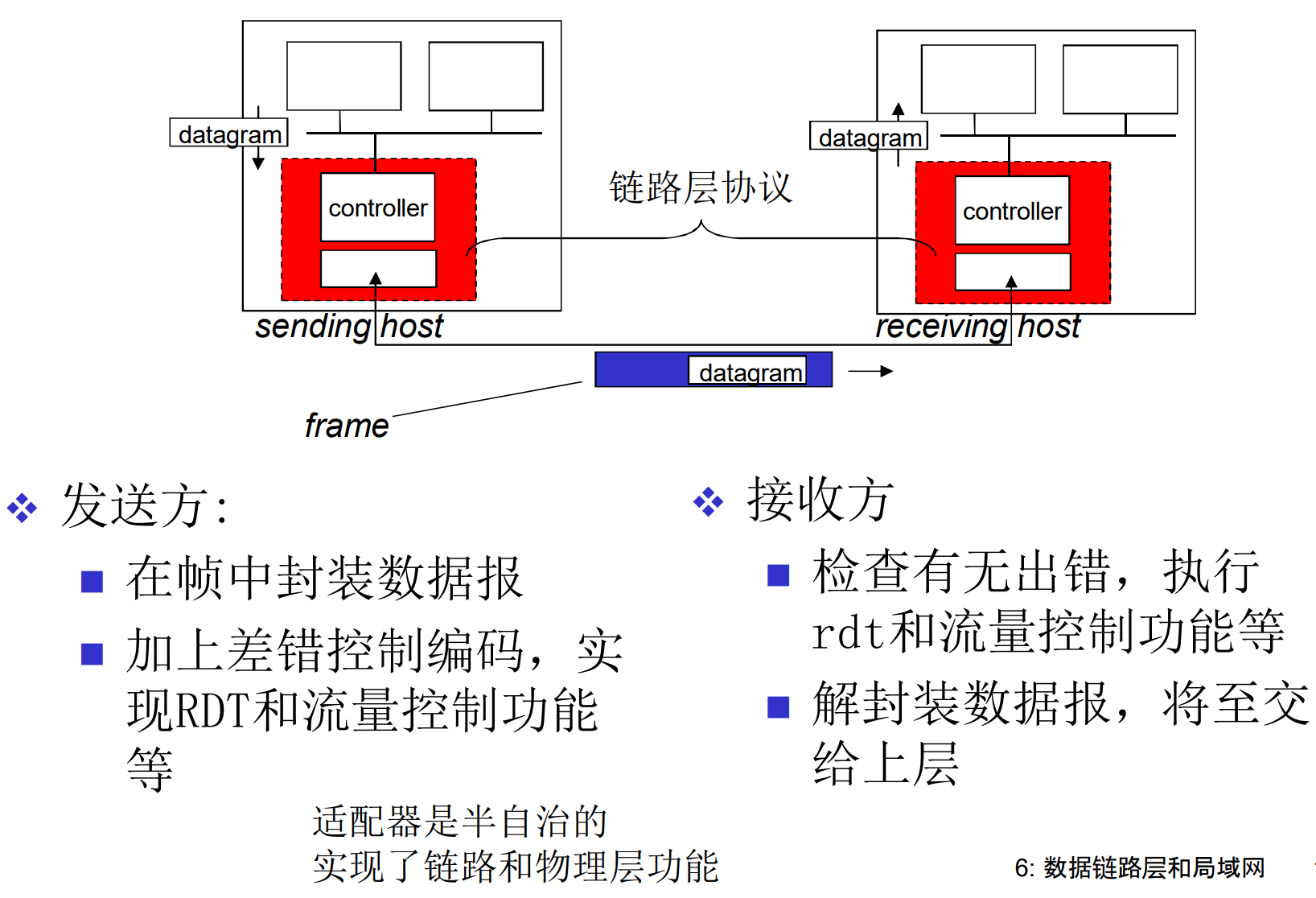
虽然上图区分的发送和接收方, 实际情况中, 一张网卡可以同时收发
6.2 检错与纠错
名词解释:
-
EDC, 差错检测与纠正位(也叫冗余位)
-
D, 数据本身
校验通过也不一定对, 校验不通过一定错
通过校验的错误叫做残存错误, 数据量越大, 残存错误越少
奇偶校验
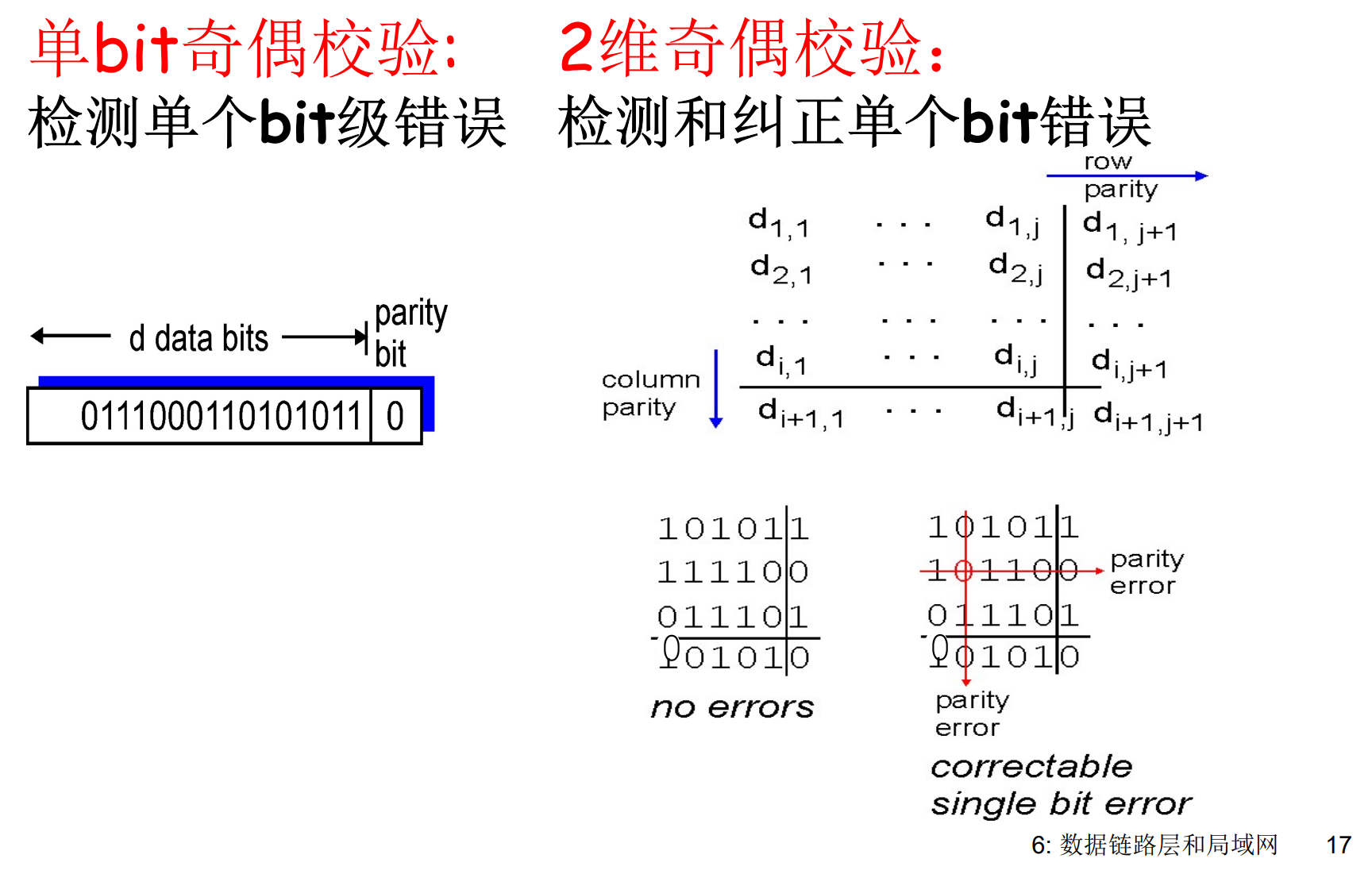
Internet校验和: checksum

CRC: 循环冗余校验码
CRC将D看作二进制数据, 二进制数据可以对应多项式
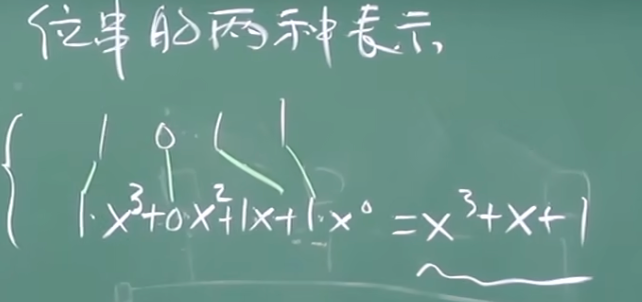
发送方:
- 构造r位的EDC模式R, 令D-R可以整除G
接收方:
- 收到信息, 直接除以G, 检查整除性
其中的G是双方约定的, r+1位的模式
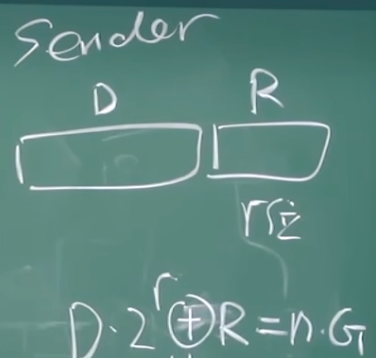
在构造时, 目标是令
$$
D \cdot 2^r \otimes R = n \cdot G
$$
其中
- n是整数, 代表整除
- 左侧代表将D左移r位, 然后补R(EDC)
可以解得
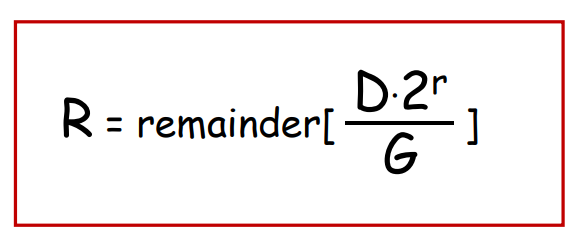
即, 发送方需要将发送的数据D
- 补r个0
- 除G, 取余数R
- 拼接D-R
接收方对收到的数据M只需
- 除G检查整除

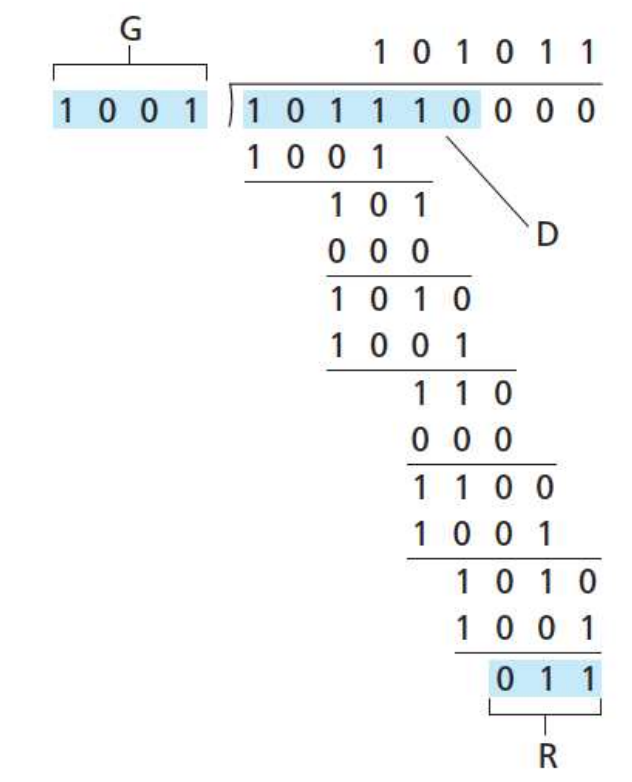
CRC可以检测出所有1bit, 所有2bit, 所有长度<=r的错误
6.3 多路访问协议
点对点
- 拨号上网
多点连接(共享链路或者媒体)
- 早期以太网, HFC上行链路, 802.11无线局域网
早期的以太网中, 每个数据包都是发给整个网络的, 主机通过MAC地址判断是否是发给自己
多点连接的网络也叫广播式的网络, 在这样的网络中, 存在一种冲突: 多个站点同时抢占传输介质, 导致信息重叠失效
需要分布式的算法决定一个节点在何时可以使用这条共享信道, 这就是MAC问题, 介质访问控制问题
由于信道是唯一的, 关于信道的控制信息, 协商过程, 也只能在信道本身上传输
名次解释:
MAC, Media Access Control, 媒体访问控制
MAP, Media Access Protocol, 媒体访问协议
上面是从算法角度说, 下面是实现角度, 差不多是一个意思, 很多地方都能混用
理想的多路访问协议
- 当一个节点要发送, 可以以R的速率发送
- 档M个节点要发送, 则每个平均发送速率位R/M
- 完全分布式的: 不需要一个节点来协调
- 简单
MAC协议: 分类
总的来说有3大类
-
按信道划分
- 按照时间, 频率
-
随机访问
- 随机使用信道, 允许碰撞, 但需要规定碰撞恢复
-
依次轮流
- 完全分布的: 利用令牌
- 不完全分布的: 一个主机轮流问询
信道划分MAC协议: TDMA
时分多路复用, TDMA: Time Division Multiple Access
按照时钟周期, 轮流使用信道, 不使用则浪费时间
信道划分MAC协议: FDMA
频分多路复用, F: Frequency
每个站点有自己的频段, 不使用则浪费频段
码分多路访问: CDMA
码分多路复用, C: Code
-
所有站点同时在整个介质上传输, 通过编码原理区分
-
完全无冲突
-
假定信号同步很好, 并可以线性叠加
随机存取协议: Random Access
当节点有数据需要发送时, 不做协调, 直接发送
协议允许冲突, 并且要规定
- 如何检测冲突
- 如何处理冲突(重传等)
随机MAC协议有:
- 时隙ALOHA, ALOHA
- CSMA/CD, CSMA/CA
现代以太网采用CSMA/CD, 无线局域网802.11采用CSMA/CA
CS:载波侦听 MA: 多路访问 CD: 冲突检测 CA: 冲突避免
时隙ALOHA
将时间分成了一段段等长的时隙(或者叫时槽)
重要假设
- 所有帧等长, 每个时隙发送一帧
- 节点在时隙开始节点发送
- 节点的时钟同步
- 冲突可以被所有站点检测到
当一个节点获得了新的帧, 从下一个时隙的开始发送, 如果冲突了, 可以观测能量幅度来检测冲突. 如果冲突了, 下个时隙以概率p发
如果不巧又碰了, 那就继续等到下个时隙, 以概率p发
没有一个延迟上限, 理论上存在一直发不出去的可能

纯ALOHA(非时隙ALOHA)
非常自由: 有数据帧就直接发
碰撞概率比时隙ALOHA大很多(大一倍)
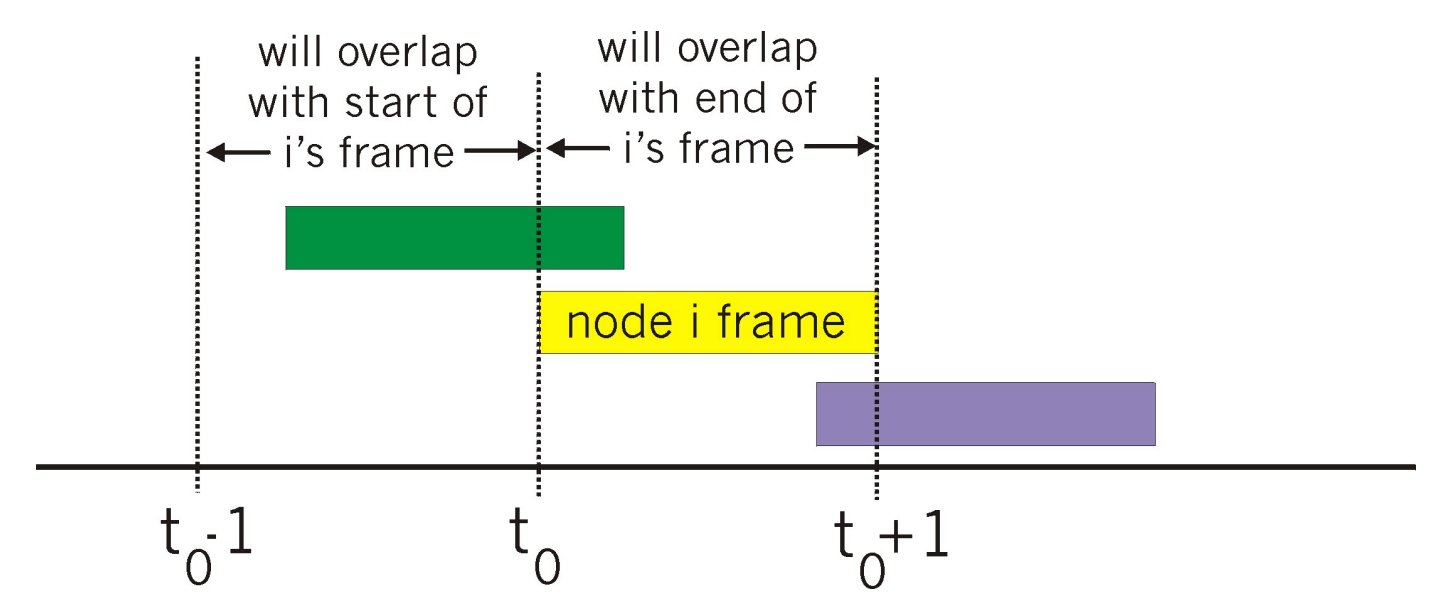
CSMA: 载波侦听, 多路访问
在发送帧之前先侦听信道, 如果忙就推迟自己的发送: 不主动打断别人的传输
冲突仍有可能发生: 侦听有延迟, 也许别人已经开始发送了, 只是没有传播到本地
传播延迟决定了冲突概率: 物理距离越远, 延迟越大越容易冲突
CSMA/CD: 冲突检测
-
如果监测到冲突, 则立即中断通信
-
冲突检测技术在有形介质中容易实现
- 检测信号强度, 比较传输与接收
- 周期的过0点检测
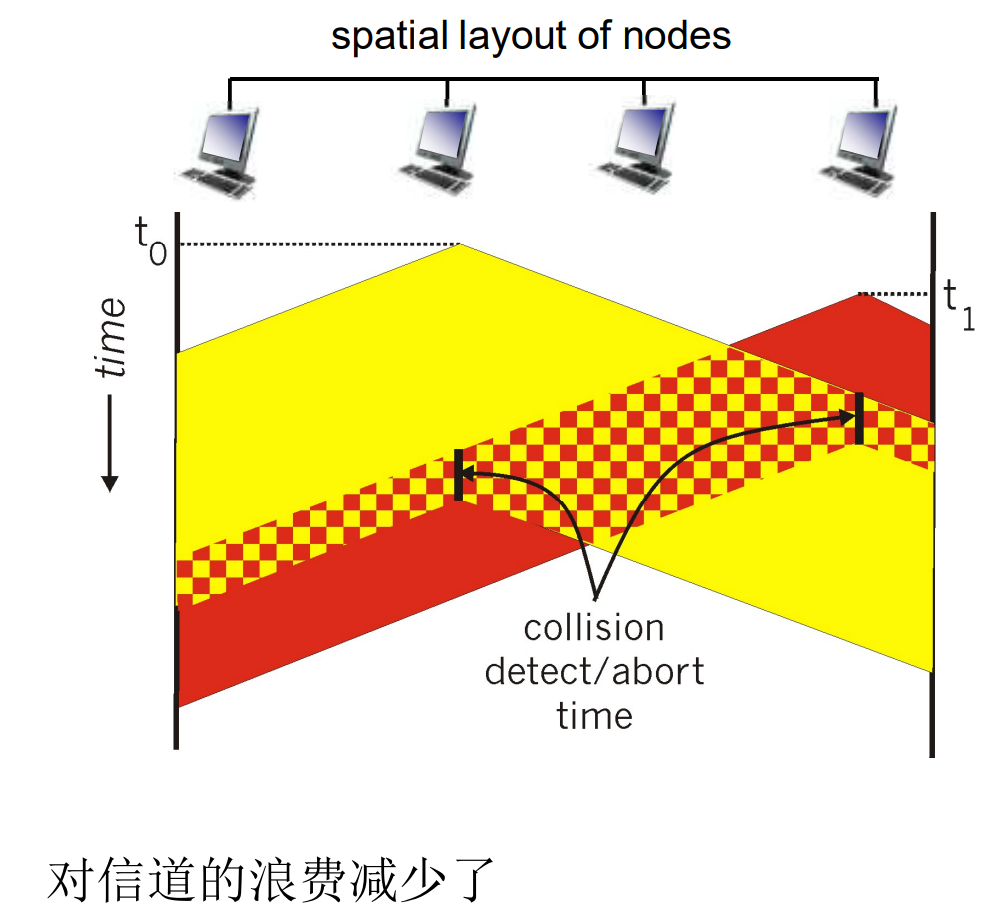
以太网的CSMA/CD除了上述外, 还有以下规则
- 侦测到冲突放弃通信时, 发送JAM信号(强化冲突, 通知所有节点)
- 放弃之后, 进入二进制指数退避状态
CSMA/CD算法主要应用于早期的以太网, 使用集线器(共享传输介质)上网的情景
在现代以太网中, 交换机代替了集线器, 让网络支持端到端的全双工通讯, 这使得CSMA/CD算法几乎退出了历史舞台
CSMA/CD算法被设计解决半双工通讯问题, 现代以太网则是全双工的
更多补充: 虽然网卡的物理地址(MAC地址, Media Access Control Addr.)名字中有MAC, 但是因为交换机的普及, 作用已经和控制访问关系不大了
在早期以太网中, MAC和CSMA/CD协议关系密切, 单在今天, MAC地址更多的是作为网卡标识使用
CSMA/CA: 冲突避免
CSMA/CA主要应用于无线网络通讯中, 这里探讨的是有基础设施的WLAN
名次解释:
WLAN, Wireless Local Area Network, 无线局域网
LAN, (有线)局域网
无线网络中很难做冲突检测: 信号随距离衰减过快
IEEE 802.11: CSMA/CA的实例
- 发之前侦听, 如果信道忙则不发
- 一旦开始发送, 一股脑发送完, 不做冲突检测(没法做)
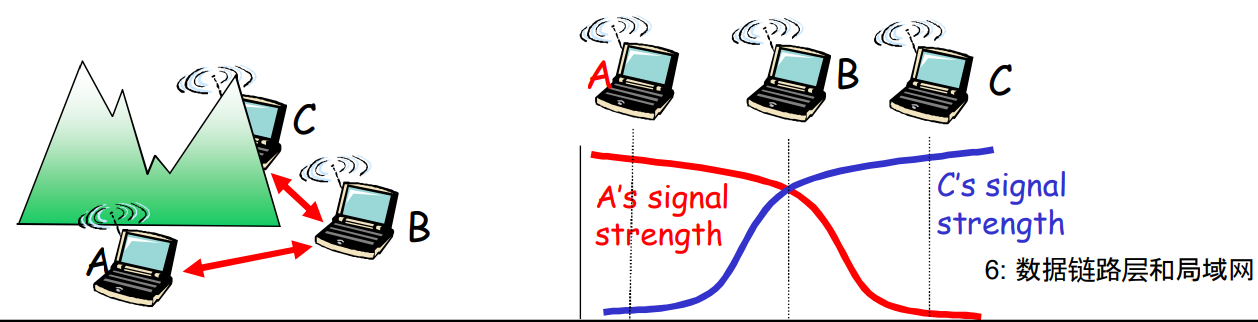
上图中描述这样的情景:
- A2B, C2B
- AC之间信号屏障, 互相无法知道
- AC检测不到冲突, 但实际上B附近严重冲突
这说明在WLAN中, 主观的不冲突不能认为传输成功, 并且进一步论证了WLAN无法做CD
- 而在LAN中, 主观不冲突可以认为是传输成功
802.11发送方
如果有信息要发送, 监听信道
-
如果信道空闲了DIFS时间, 直接发送
-
反之如果信道忙, 则生成一个随机的回退值T, 这个T会在信道空闲的时候递减(信道忙时不变)
-
T=0时(只可能发生在信道空闲), 发送整个帧, 如果收不到ACK, 增加回退值T, 继续等待
802.11接收方
如果帧正确, 且信道空闲SIFS后, 回复ACK, SIFS < DIFS, 体现了ACK的优先级较高
WLAN中因为无法CD, 造成很多问题, 其中最主要的就是发送的报文不确定成功, 因此才需要ACK, 而LAN不需要ACK
注意之前提到的, 链路层协议是部分可靠的(有ACK的), LAN不需要ACK, 但WLAN需要
IEEE 802.11 MAC协议无法完全避免冲突
- 节点被隐藏
- 选择了非常近的回退值
6.4 LANs
MAC地址 & ARP
32bit的IPv4地址
- 网络层地址
- 负责数据报传输到当前子网
- 即前n-1跳: 网络号
- 最后一跳: 主机号
48bit的MAC地址是在一个网络内部标识唯一节点的工具. 网卡不认识IP地址, 只认识MAC地址
ARP协议负责IP地址到MAC地址的转换
- IP地址是分层的, 还涉及路由汇集技术
- MAC地址是平面的, 每个网络内唯一
MAC地址出场固化, 全球唯一
实际上, 很多OS可以暂时覆盖(隐藏)真实MAC地址, 子网内不冲突即可
一个物理接口可以绑定多个IP地址(别名, 多播等), 但是一般只有一个MAC地址
MAC地址是链路层地址, 和IP地址分离有很多好处, 其中之一就是下层不应该关心上层的信息
ARP: Addr. Resolution Protocol
问题: 已知B的IP地址, 如何转换为MAC地址?
- 如果本地的ARP表中有缓存结果, 就直接转换
- 如果没有, 则在本地网络泛洪询问
- 目标主机收到询问后, 回复自己的MAC地址
ARP是即插即用的, 这是因为对应关系很容易变化
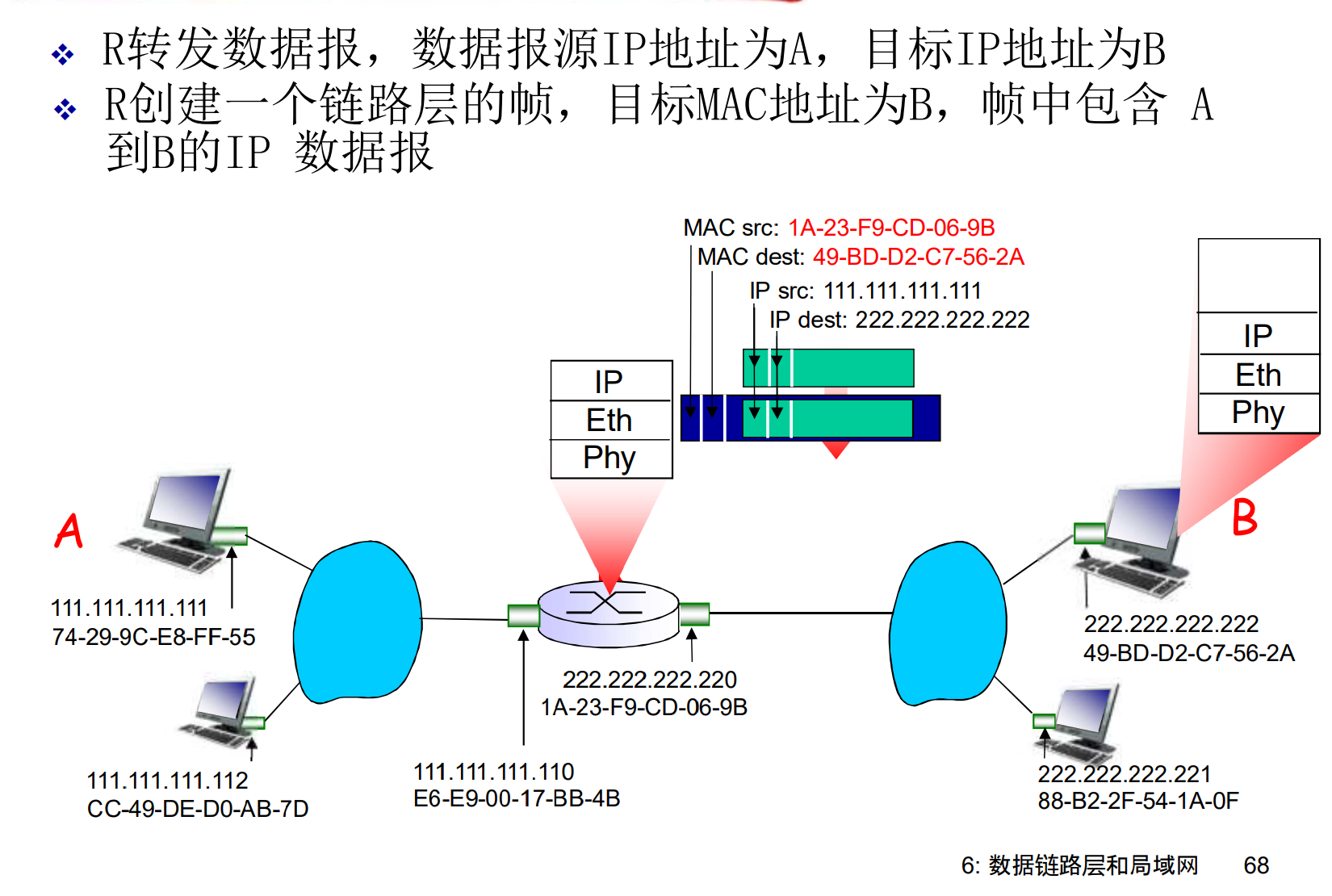
分组全程源IP, 目标IP都不变, 但是每一跳的源MAC, 目标MAC都在变
以太网: 最流行的LAN技术
早期以太网需要用到CSMA/CD协议: 同轴电缆
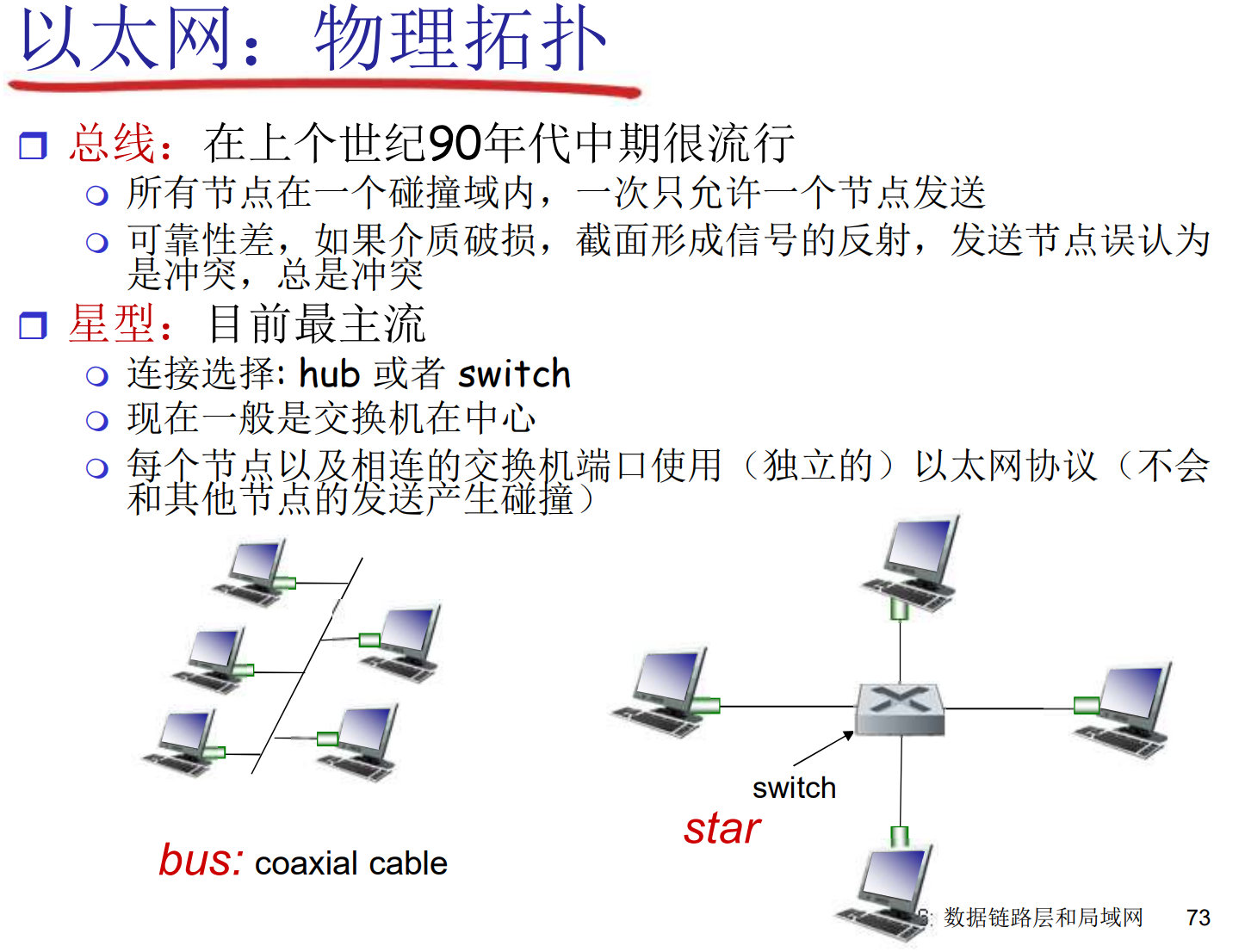
HUB
-
物理层设备, 只提供链接, 链路速率必须一样
-
物理上是星形的, 逻辑上还是总线, 泛洪所有数据
-
收发速率一致, 没有缓存
-
所有节点处在一个碰撞域, 需要CSMA/CD
交换机
-
链路层设备, 根据帧头选择性转
-
自学习的交换表, 无需配置, 可以级联
- 同样会选择性的drop和泛洪
-
有MAC地址, 没有IP地址
-
可以认为在转发的瞬间形成了通路
-
此时不太需要CSMA/CD了(象征性的做, 但是弱化了)
-
生成树算法, 同时间不能成环
以太网提供的是无连接, 不可靠的服务
- LAN的出错率比较低, CRC出错就丢掉
802.3 以太网的标准: 链路层与物理层
以太网的标准很多, 对应不同的物理媒介
- 光纤, 同轴电缆, 双绞线, …
这些标准下统一不变的有
- MAC协议
- 帧结构
- CSMA/CD(尽管已经用不上)
好, 那么好
nice