
吉林大学软件学院 企业级数据库应用开发
考题回忆
吉林大学软件学院企业级数据库应用开发, 总共就复习了1天, 内容不算多, 但是考试出题背刺了
整理了一下知识点, 主要来源是PPT, 实验报告, 历年题
历年题几乎只出实验内容, 22级考的和往年非常不一样, 往年题里必考的连接数据库, 加载驱动没考, db2相关没考, Java也没要求, 全程只出应用题, 自选语言+实现方式, 感觉整个卷子和db2没啥关系, 反而有点贴近课程名了
回忆一下考题
第一大题, 5小题, 15分一道, 共计75分
题干: 给了一个employee表, 结构(No, name, bitrhday, age, salary, bonus, resume, photo)
- 开幕雷击, 问插入大量数据如何每500行提交一次, 但是没让恢复状态, 简单了一点
答案我这个笔记里有, 也有同学用子查询做, 考场上我是先SELECT出来, 然后rs遍历, 用wasNull判断, 再插, 计数器%500提交
- 查表, 把奖金=0的员工绩效设置为不合格
for update & where current of, 年年考
- 插入新员工信息, 从键盘读入
Scanner, setNull()
- 异常处理, 插入数据, 给了违反约束的SQLState, 让处理, 其实就是打印字符串
try-catch, "XXX".equals(e.getSQLState())
- 更新一个员工的photo
BLOB插入, 各种流
第二大题, 共计25分
开放题, 给了个特别幽默的12306 app截图, 圈了几个功能问怎么实现
- 不登录的用户可以看列车表, 但是只有登录用户可以购票, 问怎么实现
我写的只读视图, 不知道他想问啥
- 自行定义表的结构,完成下面问题
- 实现查询, 并且可以勾选复选框筛选, 只看高铁, 只看动车, 只看有票
- 根据耗时, 票价等多个指标排序
- 点击筛选, 出来一个复杂筛选界面
太开放了, 从两个角度说, 一个SQL, 可以多重子查询实现, String拼接SQL语句; 一个GUI, 说了一下可以用java.swing, java.awt.Event, 都是这课学的, 不能白背了, 硬写, 写满, 手写酸了, 休息了十几分钟, 又写了几分钟, 手又开始疼, 没耐心了, 提前交卷
考题总结自洛樱, 引用几个参考资料
今年热乎的
往年的
- https://blog.csdn.net/kqwangxi/article/details/122232917
- https://blog.csdn.net/It_Ray/article/details/135437808
- https://github.com/Xing-hui/db2
- https://github.com/syladmit985350/–
往年考的很八股, 都是拿名词直接问, 不知道今年抽什么风, 考的东西和Java6, db2都没关系, 出得题很开放, 需要理解, 自己分析要用什么方法
往年考点总结是这些
- db2连接+加载启动, 必考
- 关闭连接次序, 常考
- pstmt批处理, 常考
- wasNull, setNull, 必考
- 游标参数, 倒叙, 考过
- FOR UPDATE + WHERE CURRENT OF, 必考
- CLOB/BLOB, 常考
- GUI, 考过, 就问用到哪些库了, 没问具体实现, 估计老师自己也不会实现
- 错误处理, 常考
简要总结
幽默课, XP+db2+Java6, 养蛊, 总拿个别银行还在用这套系统说事, 其实就是遗留问题
成绩50%报告, 50%期末笔试, 说是这么说, 我感觉报告会参考笔试分数
上课有签到, 必须去
内容其实不算多, 我学了1天, 做了前几个实验, 看PPT总结一下, 然后总结历年题, 疯狂默写上面总结考点的代码, 不能说没用, 但还是被考试题吓了一跳
实验做的人想死, 非得折腾那XP虚拟机, macos没有原生支持的Java6, 最后查手册下了个Java8(Java8都很难下了, 太老了).
db2用的驱动老掉牙, GPT表示这个版本早就结束生命周期了, 硬做, 前几个实验不让用外部(宿主机)的IDE, 建议大伙直接把虚拟机桥接出来, 在外面连上数据库, IDE框框写, 测没问题了文件传虚拟机里面, 再装模作样的javac, java
初始化数据库参数与URL
// 数据库连接参数
String host = "10.67.4.163";
String port = "50000";
String dbName = "sample";
String user = agrs[0];
String pswd = args[1];
// JDBC 连接字符串
String url = "jdbc:db2://" + host + ":" + port + "/" + dbName;典型的URL
要连接远端的数据库
jdbc:db2://<host>:<port>/<dbName>要连接本地的数据库, 可以简写为
jdbc:db2:<dbName>加载数据库连接
// 初始化数据库连接
Connection connection = null;
try {
// 加载 DB2 JDBC 驱动程序
Class.forName("com.ibm.db2.jcc.DB2Driver");
// 创建连接
System.out.println("Connecting to the database...");
connection = DriverManager.getConnection(url, user, pswd); // 死记硬背这一行
System.out.println("Connection successful!");
} catch (ClassNotFoundException e) {
System.err.println("DB2 Driver not found. Ensure the DB2 JDBC driver is in the classpath.");
e.printStackTrace();
} catch (SQLException e) {
System.err.println("Failed to connect to the database. Check the connection parameters.");
e.printStackTrace();
}简单查询: Statement与ResultSet
try {
Statement stmt = connection.createStatement();
// ResultSet 卷子里都叫结果集
ResultSet rs = stmt.executeQuery("SELECT * FROM TEMPL");
// 一次查询后, rs位于结果的前一个行, 必须next一次, 才指向数据
while (rs.next()) {
System.out.println("empno = " + rs.getString(1) + "lastname = " + rs.getString(2));
}
} catch (SQLException e) {
e.printStackTrace();
}Statement: 用于向数据库发送 SQL 语句的接口,用于执行静态 SQL 查询(如 SELECT、INSERT、UPDATE 等)。它是最基础的接口,适合执行简单的 SQL 语句
executeQuery(String sql), 执行查询, 返回结果集对象executeUpdate(String sql), 执行更新语句, 返回受影响行数execute(String sql), 任意SQL语句, 返回boolean,true代表查询,false代表更新
ResultSet: 用来存储查询结果的对象,一个指向行的指针, 使你可以逐行读取查询返回的数据。它提供了多种方法来获取列值,并支持通过列名或列索引访问数据
next(), 移动到下一行,返回true如果存在下一行, 否则返回false, 这是用来判断数据位置的核心方法getInt(String columnLabel), 获取某一列的整数值getString(String columnLabel), 获取某一列的字符串值getDate(String columnLabel), 获取某一列的日期值close()关闭ResultSet,释放资源
关闭连接的次序
rs.close(); // 关闭 ResultSet
stmt.close(); // 关闭 Statement
connection.close(); // 关闭 ConnectionResultSet依赖于Statement, 而Connection是核心部件, 应该以上面的次序关闭连接, 否则可能会出现长时间占用资源
注意: 关闭连接并不代表修改已经提交了
PreparedSatement
JDBC 中用于执行 预编译 SQL 语句 的接口,继承自 Statement。它是 Statement 的增强版本,专门用于处理动态参数化的 SQL 查询。
pstmt特性: 预编译效率更高, 支持动态参数, 防止SQL注入
pstmt查询数据
String sql = "SELECT * FROM employees WHERE department_id = ? AND salary > ?";
// 注意下面这里, pstmt和stmt不太一样, 创建时候就填入sql语句了(预编译的)
PreparedStatement pstmt = connection.prepareStatement(sql);
// 设置参数
pstmt.setInt(1, 10); // 第一个参数:department_id = 10
pstmt.setDouble(2, 5000.0); // 第二个参数:salary > 5000.0
// 执行查询
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
System.out.println("ID: " + rs.getInt("id"));
System.out.println("Name: " + rs.getString("name"));
}pstmt插入数据
// 创建 PreparedStatement
String sql = "INSERT INTO employees (name, department_id, salary) VALUES (?, ?, ?)";
PreparedStatement pstmt = connection.prepareStatement(sql);
// 设置参数
pstmt.setString(1, "Alice"); // 第一个参数:name = 'Alice'
pstmt.setInt(2, 5); // 第二个参数:department_id = 5
pstmt.setDouble(3, 7000.0); // 第三个参数:salary = 7000.0
// 执行更新
int rowsInserted = pstmt.executeUpdate();
System.out.println("Rows inserted: " + rowsInserted);pstmt批量操作: Batch
// pstmt非常适合批量操作
String sql = "INSERT INTO employees (name, department_id, salary) VALUES (?, ?, ?)";
PreparedStatement pstmt = connection.prepareStatement(sql);
// 添加多条记录
pstmt.setString(1, "Alice");
pstmt.setInt(2, 1);
pstmt.setDouble(3, 5000.0);
pstmt.addBatch(); // 加入批处理
pstmt.setString(1, "Bob");
pstmt.setInt(2, 2);
pstmt.setDouble(3, 6000.0);
pstmt.addBatch(); // 加入批处理
// 执行批量操作
int[] results = pstmt.executeBatch();
System.out.println("Rows affected: " + Arrays.toString(results));通过子查询插入
// 定义插入语句的 SQL
String sqlInsert = "INSERT INTO TEMPL (EMPNO, FIRSTNAME, MIDNAME, LASTNAME) ";
// 定义子查询语句的 SQL
String selectQuery = "SELECT EMPNO, FIRSTNME, MIDNAME, LASTNAME FROM JLU.EMPLOYEE WHERE ? = ?";
// 合并插入语句和子查询语句
String findInsert = "INSERT INTO TEMPL (EMPNO, FIRSTNME, LASTNAME, EDLEVEL) " +
"SELECT EMPNO, FIRSTNME, LASTNAME, EDLEVEL FROM EMPLOYEE " +
"WHERE EMPNO = ? AND FIRSTNME = ? AND LASTNAME = ? AND EDLEVEL = ?";
// 准备 SQL 语句
PreparedStatement pstmt = connection.prepareStatement(findInsert);
// 设置占位符的值
pstmt.setString(1, "123"); // 替换 EMPNO 的占位符
pstmt.setString(2, "John"); // 替换 FIRSTNME 的占位符
pstmt.setString(3, "Doe"); // 替换 LASTNAME 的占位符
pstmt.setInt(4, 5); // 替换 EDLEVEL 的占位符
// 执行插入操作
int rowsAffected = pstmt.executeUpdate();
System.out.println("Rows inserted: " + rowsAffected);主变量与列变量
- 主变量: C/Java等程序中定义, 用以从数据库中读取数据的变量
- 列变量: 数据库实体的列, 存放在磁盘中
下面的SQL语句中, EMP_ID, EMP_NAME, EMP_SALARY 都是列变量
CREATE TABLE EMPLOYEE (
EMP_ID INTEGER,
EMP_NAME VARCHAR(50),
EMP_SALARY DECIMAL(10, 2)
);下面是DCLGE工具为该表生成的类, 类内封装了主变量
// DCLGEN Output for Table: EMPLOYEE
public class Employee {
public int empId; // 对应 EMP_ID
public String empName; // 对应 EMP_NAME
public java.math.BigDecimal empSalary; // 对应 EMP_SALARY
// 构造函数
public Employee() {}
// 可选:提供 getter 和 setter 方法
public int getEmpId() {
return empId;
}
public void setEmpId(int empId) {
this.empId = empId;
}
...
}DCLGE工具用以自动化的为一个数据库的表生成对应主机变量的声明, 以下是为上面Employee表生成的命令
db2dclgn -D sample -T EMPLOYEE -L Java -F Employee.java
关于NULL的讨论
wasNull()
每种JDBC变量在数据库为NULL时都有一个默认的返回值, 因此直接将get到的主机变量与NULL做比较是不可靠的
考虑下面的代码
String mgrno = rs.getString(1);
if (mogrno == null) {
... // 作出一些处理
}这种做法是不可靠的, 比如getInt(), getShort()会在NULL时返回0, 此时无法得知该数据是NULL还是0
我们应该用wasNull()来检查上一次getXXX的结果是不是NULL
// 遍历结果集
while (resultSet.next()) {
// 获取 name 列的值
String name = resultSet.getString("name");
// 检测 name 是否为 NULL
if (resultSet.wasNull()) {
System.out.println("name 列值为 NULL");
} else {
System.out.println("name: " + name);
}
// 获取 age 列的值
int age = resultSet.getInt("age");
// 检测 age 是否为 NULL
if (resultSet.wasNull()) {
System.out.println("age 列值为 NULL");
} else {
System.out.println("age: " + age);
}
System.out.println("------------------------------");
}setNull()
考虑这样的代码
PreparedStatement stmt = null;
// 要将编号为000110的员工电话号码设置为空
sql = "UPDATE TEMPL SET PHONENO = ? " + "WHERE EMPNO = '000110' ";
stmt = con.prepareStatement(sql);
if (...) {
stmt.setString(1, null); // 这样做不好!
} else {
...
}
updateCount = stmt.executeUpdate();JDBC 无法确定参数的 SQL 数据类型
上面的做法可能会导致数据库抛出错误,或者无法正确地将参数标记为 SQL 的 NULL 值。例如,数据库可能会尝试将 null 解析为 VARCHAR 类型,但如果数据库字段是其他类型(如 INTEGER 或 DATE),就会导致类型不匹配错误
在需要设置NULL时候, 我们应该用JDBC提供的setNull()方法
if (some condition) {
stmt.setNull(1, java.sql.Types.VARCHAR); // 明确指定为 SQL NULL,并明确类型为 VARCHAR (这一列的类型)
} else {
stmt.setString(1, newphone); // 正常设置字符串值
}
updateCount = stmt.executeUpdate();SQLCA
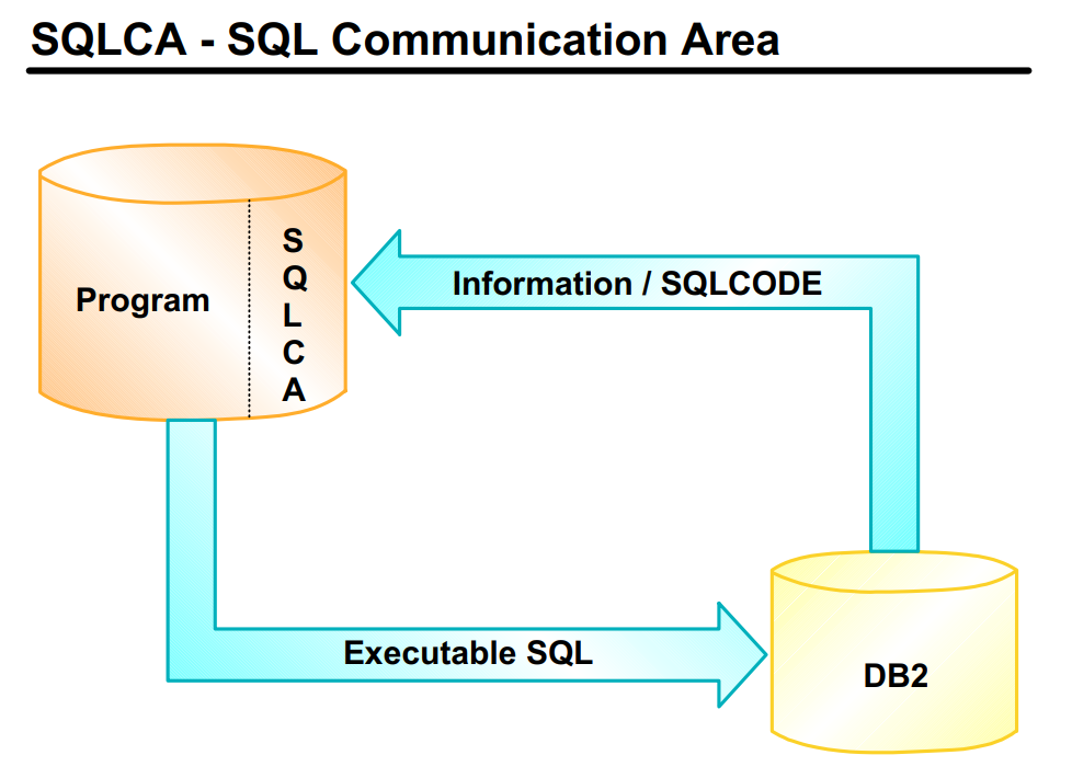
SQLCA(SQL Communication Area)是 SQL 应用程序中的一个数据结构,用于存储 SQL 操作执行后的状态信息。它是数据库系统为了帮助程序处理 SQL 语句执行结果而设计的一个标准化结构
SQLCA的核心信息有: SQLCODE, SQLSTATE, SQLERRM, SQLWARN
// SQLExpection通常是致命的
SQLException.getSQLState();
SQLException.getErrorCode();
SQLException.getMessage();
// SQLWARN是非致命的
DriverManager.getConnection.getWarn(); SQLCA 提供的信息包括:
- SQL 操作是否成功, 影响的行数, 错误代码和错误信息(如果有), 警告状态
Java中没有直接的SQLCA数据结构, 但是可以通过JDBC的sqlcode和sqlerrm实现类似的效果
try {
// 1. 建立连接
conn = DriverManager.getConnection(jdbcUrl, username, password);
// 2. 执行查询
String sql = "SELECT * FROM employees";
pstmt = conn.prepareStatement(sql);
rs = pstmt.executeQuery();
// 3. 处理查询结果
while (rs.next()) {
System.out.println("员工ID: " + rs.getInt("id") + ", 姓名: " + rs.getString("name"));
}
// 4. 检查 SQL 警告
SQLWarning warning = conn.getWarnings();
while (warning != null) {
System.out.println("SQL 警告: " + warning.getMessage());
warning = warning.getNextWarning();
}
} catch (SQLException e) {
// 处理 SQL 错误,类似 SQLCA 中的 sqlcode 和 sqlerrm
System.err.println("SQL 错误代码: " + e.getErrorCode());
System.err.println("SQL 状态: " + e.getSQLState());
System.err.println("错误消息: " + e.getMessage());
// 上面这些get方法, 都返回String, 如果想比较, 则
// if (e.getSQLState().equals("42818")) {...}
} finally {
// 5. 关闭资源
try {
if (rs != null) rs.close();
if (pstmt != null) pstmt.close();
if (conn != null) conn.close();
} catch (SQLException e) {
System.err.println("关闭资源时出错: " + e.getMessage());
}
}如果上面的代码出错了, 可能会输出形似这样的信息
SQL 错误代码: 1045
SQL 状态: 28000
错误消息: Access denied for user 'root'@'localhost' (using password: YES)SQLSTATE 和 SQLCODE 的差异
| 特性 | SQLSTATE |
SQLCODE |
|---|---|---|
| 长度/格式 | 5 个字符的字符串代码(如 23000) |
一个整数(如 -104 或 +100) |
| 标准化 | 跨数据库系统标准化,符合 SQL 标准 | 数据库系统专有,可能因系统而异 |
| 用途 | 更适合跨平台的错误处理和兼容性 | 更适合特定数据库系统内部的错误调试 |
| 错误类型 | 提供通用的错误分类和子分类 | 提供更具体的错误编号 |
| 常见范围 | 00000(成功),01000(警告), 02000(未找到数据)等 |
0(成功),+100(未找到数据),负数表示错误 |
SQLSTATE 和 SQLCODE的关系
- 映射关系:
- 每个
SQLSTATE通常对应一个或多个SQLCODE值 - 例如:
SQLSTATE为02000(未找到数据),对应的SQLCODE为+100SQLSTATE为23000(违反完整性约束),可能对应多个SQLCODE,如-803(主键冲突)或-104(约束错误)
- 但
SQLCODE是数据库系统特定的,某些数据库可能定义了额外的SQLCODE值,而这些值没有对应的SQLSTATE
- 每个
- 优先级:
- 如果需要跨数据库平台的错误处理,推荐使用
SQLSTATE - 如果只针对单一数据库系统,
SQLCODE通常提供更详细的信息
- 如果需要跨数据库平台的错误处理,推荐使用
JDBC只支持动态SQL,要求执行程序的User必须拥有执行这条语句的权限
游标的两个参数
在前面的实验中, 都使用了默认的游标, 这种游标只能向前滚动, 叫做TYPE_FORWARD_ONLY结果集
除此之外, 还有还有 TYPE_SCROLL_INSENSITIVE 和 TYPE_SCROLL_SENSITIVE 结果集, 这两种结果集的游标都可以前后滚动, 区别是敏感结果集会立即反应数据的更改情况, 而不敏感结果集需要手动刷新
游标属性应该这样设置:
ResultSet rs = null;
PreparedStatement pstmt = con.prepareStatement(
"SELECT EMPNO, LASTNAME " +
" FROM TEMPL " +
" WHERE WORKDEPT = ? ",
ResultSet.TYPE_FORWARD_ONLY, // 只能向前
ResultSet.CONCUR_READ_ONLY // 只有读操作可以并发
);
pstmt.setString(1, argv[0]);
while (prs.next()) {
System.out.println("empno " + prs.getString(1) +
" lastname " + prs.getString(2));
}除了
CONCUR_READ_ONLY并发类型(表示查询仅为只读模式 FETCH ONLY)之外,JDBC 2.0 还支持CONCUR_UPDATABLE并发类型,该类型允许对查询进行 FOR UPDATE 操作。然而,DB2 的 JDBC 2.0 驱动程序不支持
CONCUR_UPDATABLE参数。假如你正在开发一个基于 DB2 数据库的 Java 应用程序,并需要修改查询结果集中的数据,那么你需要找到替代方法(例如直接执行
UPDATE语句, 或者使用定位更新技术),因为CONCUR_UPDATABLE无法使用。
下面是一个使用高级游标的例子
// 定义一个可滚动的结果集对象
ResultSet scrollrs = null;
sql = "SELECT"
+ " EMP.FIRSTNAME," // 员工的名字
+ " EMP.LASTNAME" // 员工的姓氏
+ " FROM"
+ " EMP" // 从 EMP 表中查询
+ " WHERE"
+ " ("
+ " EMP.WORKDEPT = ?" // 条件:员工的工作部门
+ " )";
// 准备 SQL 语句
stmt = con.prepareStatement(sql,
scrollrs.TYPE_SCROLL_INSENSITIVE,
scrollrs.CONCUR_READ_ONLY);
// 设置查询条件的参数,使用占位符 (?) 填充部门编号 (dno)
stmt.setString(1, dno);
// 执行查询并将结果赋值给 scrollrs(可滚动的结果集)
scrollrs = stmt.executeQuery();
// 将光标移动到结果集的最后一行之后,准备进行逆序遍历
scrollrs.afterLast();
// 使用 while 循环从结果集的最后一行逐行向上遍历
while (scrollrs.previous()) {
// 获取当前行的第一列值(员工的名字)
firstname = scrollrs.getString(1);
// 获取当前行的第二列值(员工的姓氏)
lastname = scrollrs.getString(2);
}物化: 将结果集暂存到磁盘上
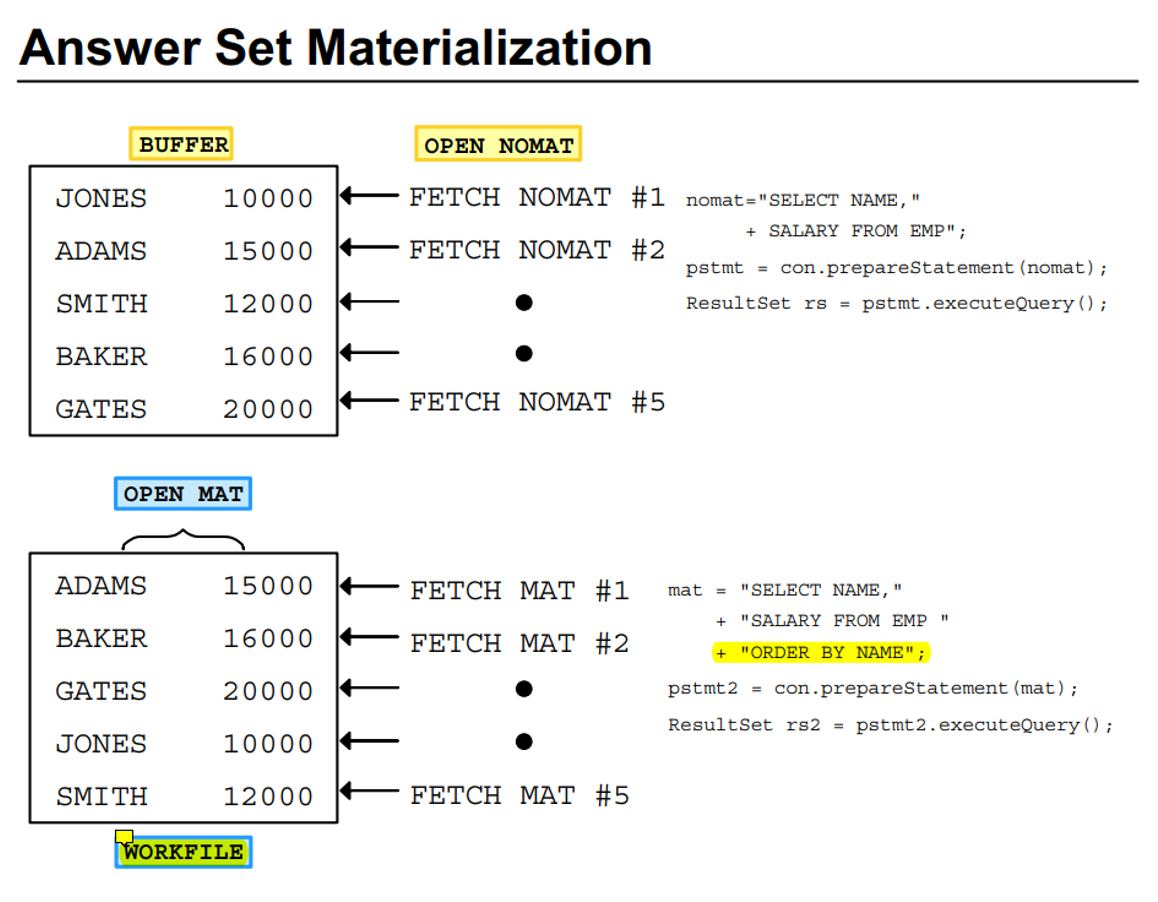
OPEN NOMAT: 非物化, 不排序, 查询结果存储在内存中, 适用于小数据
OPEN MAT: 物化, 不排序, 结果暂存到文件中, 适用于大数据
这看上去有点奇怪, 排序和存硬盘还能挂钩, 我想乱序存硬盘不行吗?
在代码上, 区别只在ORDER BY上
无 ORDER BY(非物化):
- 结果集直接从表中获取,不需要额外处理。数据库引擎只需逐行提取数据并传递给 JDBC。
- 不涉及临时文件,查询性能更高。
有 ORDER BY(物化):
- 数据库需要先将所有查询结果提取出来,并根据
ORDER BY的规则进行排序。 - 排序通常需要将结果存储在临时工作文件(
WORKFILE)中,之后再将排序后的结果返回。 - 这种场景下,数据库引擎会物化结果集(即将其存储到临时文件中)。
拓展: 除了
ORDER BY, 比如复杂的JOIN,SUM,AVG,GROUP BY, 子查询也会触发物化操作
定位更新: 游标操作结果集
定位更新是指通过游标操作结果集中的当前行数据,并根据业务逻辑直接更新数据库中的对应记录
注意:WHERE CURRENT OF 后必须指定游标名称,游标名称通过 ResultSet.getCursorName() 获取
// FOR UPDATE: 表明查询结果集中的记录是可以被修改的
String mySelect = "SELECT LASTNAME, FIRSTNME FROM EMP FOR UPDATE";
// WHERE CURRENT OF: 表示对游标当前指向的记录进行更新
String myUpdate = "UPDATE EMP SET FIRSTNME = ? WHERE CURRENT OF ";
// 上面的写法不是SQL标准, 依赖于JDBC实现
String cursorName = null;
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(mySelect);
cursorName = rs.getCursorName();
PreparedStatement ps = con.prepareStatement(myUpdate + cursorName); // 这里很重要
// 遍历mySelect的结果集
while (rs.next()) {
String lastname = rs.getString(1);
String firstnme = rs.getString(2);
if (lastname.equals("SMITH")) {
String newFirstname = "George";
ps.setString(1, newFirstname); // 业务逻辑: 用myUpdate+cursorName更新名字
ps.executeUpdate();
}
}上面的这种更新 会反映到数据库,不仅仅是对结果集负责
事实上, 当执行到
// String myUpdate = "UPDATE EMP SET FIRSTNME = ? WHERE CURRENT OF ";
// PreparedStatement ps = con.prepareStatement(myUpdate + cursorName);
ps.executeUpdate();相当于执行SQL
UPDATE EMP SET FIRSTNME = 'George' WHERE CURRENT OF cursor_name;FOR UPDATE的好处: 避免死锁
复习一下之前学过的锁
-
IS 锁 和 IX 锁 是表级别的意向锁,用于优化加锁性能,减少锁冲突
-
S 锁 用于读取数据,防止数据被修改
-
U 锁 是更新操作的过渡锁,避免了死锁
-
X 锁 用于修改数据,独占对数据的访问权限
锁的兼容性矩阵
| 锁类型 | IS | IX | S | U | X |
|---|---|---|---|---|---|
| IS | ✔️ | ✔️ | ✔️ | ❌ | ❌ |
| IX | ✔️ | ✔️ | ❌ | ❌ | ❌ |
| S | ✔️ | ❌ | ✔️ | ❌ | ❌ |
| U | ❌ | ❌ | ❌ | ✔️ | ❌ |
| X | ❌ | ❌ | ❌ | ❌ | ❌ |
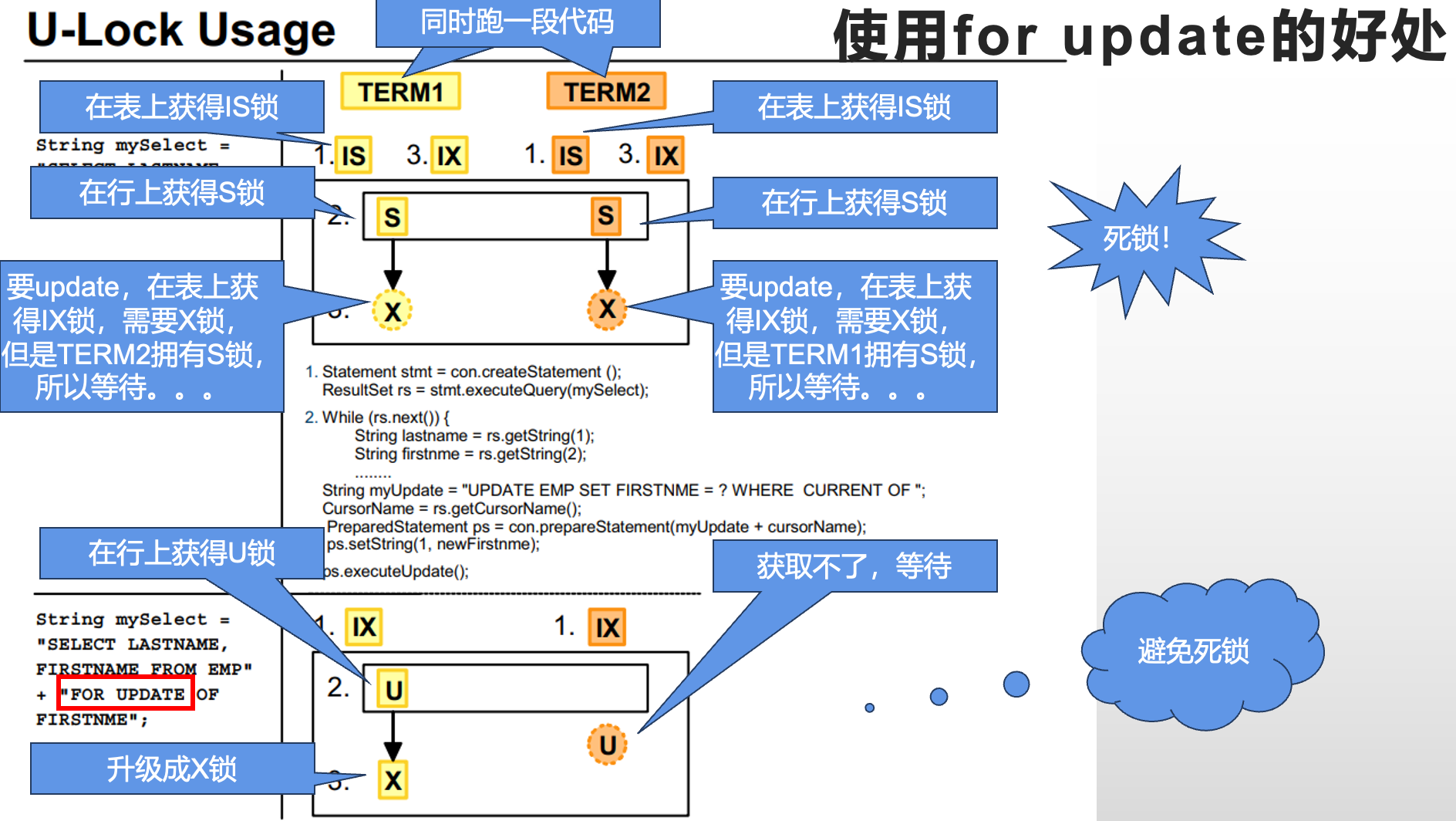
其中, 不使用FOR UPDATE的做法指UPDATE+子查询
限制说明
在SQL中, SELECT 语句不能包含 FOR UPDATE OF,也不能用于 DELETE WHERE CURRENT OF或 UPDATE WHERE CURRENT OF 的操作,如果 SELECT 语句中包含以下内容:
- ORDER BY:即对查询结果进行排序
- GROUP BY:即对查询结果进行分组
- DISTINCT:即去除查询结果中的重复数据
- 集合操作符(Set Operators):包括
UNION、EXCEPT和INTERSECT - 函数(Function):指在查询语句中调用的函数
- Join:即关联多个表的查询操作
FOR FETCH ONLY/FOR READ ONLY:只用于只读的查询操作
使用rs.close()后, 游标关闭, 内存释放, 但是锁不会改变状态, 除非commit
结果集重定位
如果要修改的数据量太大, 则应该每500行左右提交一次, 如果遇到了ABEND(异常终止), 则定位游标到检查点
-- 创建一个名为 RESTART 的表,用于保存游标重新定位的值
CREATE TABLE RESTART (VALUE INTEGER NOT NULL);int ctr = 0; // 计数器,用于记录当前处理的行数
int MinValue = 0; // 最小值,用于初始化或重新定位
int abValue = 0; // 保存的重新定位值(从 RESTART 表中读取)
ResultSet rs2 = null; // 第二个结果集,用于处理主数据
Statement stmt = con.createStatement(); // 创建 SQL 语句对象
// 查询 RESTART 表的值,用于获取上次处理的中断位置
sql = "SELECT VALUE FROM RESTART";
ResultSet rs = stmt.executeQuery(sql);
// 检查是否有值,并将值赋给 abValue
while (rs.next()) {
abValue = rs.getShort(1); // 获取第1列的值
}
// 构造一个查询,用于从主表 T1 中读取数据,使用 abValue 来定位起始位置
sql2 = "SELECT X, Y, Z FROM T1 "
+ "WHERE X > ? " // 使用占位符 ? 表示条件
+ "ORDER BY X"; // 确保结果集有序
PreparedStatement pstmt = con.prepareStatement(sql2,
rs2.TYPE_SCROLL_INSENSITIVE, // 支持游标移动,结果集不会随数据库变化而改变
rs2.CONCUR_READ_ONLY); // 结果集为只读,防止意外修改
pstmt.setShort(1, abValue); // 绑定 ? 参数为 abValue 的值
rs2 = pstmt.executeQuery(); // 执行查询并返回结果集
// 遍历结果集 rs2 中的每一行
while (rs2.next()) {
short storx = rs2.getShort(1); // 获取第1列的值(主键 X)
String story = rs2.getString(2); // 获取第2列的值(列 Y)
String storz = rs2.getString(3); // 获取第3列的值(列 Z)
// 检查某些条件(需根据实际业务逻辑定义)
if (some condition) {
// 构造更新语句,更新表 T1 中的当前行
sql3 = "UPDATE T1 SET Y = ?, Z = ? "
+ "WHERE X = ?"; // 通过主键 X 定位
// 使用 PreparedStatement 更新表 T1
PreparedStatement pstmt2 = con.prepareStatement(sql3);
pstmt2.setString(1, newStory); // 设置新值到列 Y
pstmt2.setString(2, newStorz); // 设置新值到列 Z
pstmt2.setShort(3, storx); // 设置条件列 X 的值
updateCount = pstmt2.executeUpdate(); // 执行更新语句
ctr = ctr + 1; // 计数器递增
}
// 检查计数器是否达到 500 行,若是则执行提交操作
if (ctr == 500) {
// 更新 RESTART 表中的值,保存当前处理的行位置
sql4 = "UPDATE RESTART SET VALUE = ?";
PreparedStatement pstmt3 = con.prepareStatement(sql4);
pstmt3.setShort(1, storx); // 将当前行的主键值 storx 保存到 RESTART 表
updateCount = pstmt3.executeUpdate(); // 执行更新
// 提交事务,释放锁,确保数据一致性
sql5 = "COMMIT";
Statement stmt2 = con.createStatement();
stmt2.executeUpdate(sql5);
ctr = 0; // 重置计数器
// 重新定位游标到提交前的最后一行
rs2.absolute(storx); // 根据存储的行位置重新定位
}
}
// 当所有处理完成时,保存最后的位置并提交事务
sql6 = "UPDATE RESTART SET VALUE = ?";
PreparedStatement upd = con.prepareStatement(sql6);
upd.setShort(1, minValue); // 设置最小值或最后处理的值
UpdateCount = upd.executeUpdate(); // 执行更新操作
// 提交事务,完成整个流程
sql7 = "COMMIT";
Statement cstmt = con.createStatement();
cstmt.executeUpdate(sql7);获取元数据
ResultSetMetaData 是 Java 中用于描述查询结果的结构(即元数据)的接口
通过从 ResultSet 获取 ResultSetMetaData 对象,可以访问查询结果的结构信息
try {
// 1. 通过 DriverManager 获取数据库连接
Connection sample = DriverManager.getConnection("jdbc:db2:sample");
// 2. 获取 DatabaseMetaData 对象,用于获取数据库的元数据
DatabaseMetaData dbmd = sample.getMetaData();
// 3. 调用 getSchemas() 方法,获取所有模式的 ResultSet
ResultSet rs = dbmd.getSchemas();
// 4. 遍历结果集,逐行处理每个模式信息
while (rs.next()) {
// 5. 获取当前行的第 1 列(模式名称)
String s = rs.getString(1);
// 打印模式名称
System.out.println("\nSchema Name: " + s);
}
} catch (SQLException e) {
// 捕获并打印 SQL 异常
e.printStackTrace();
}大对象
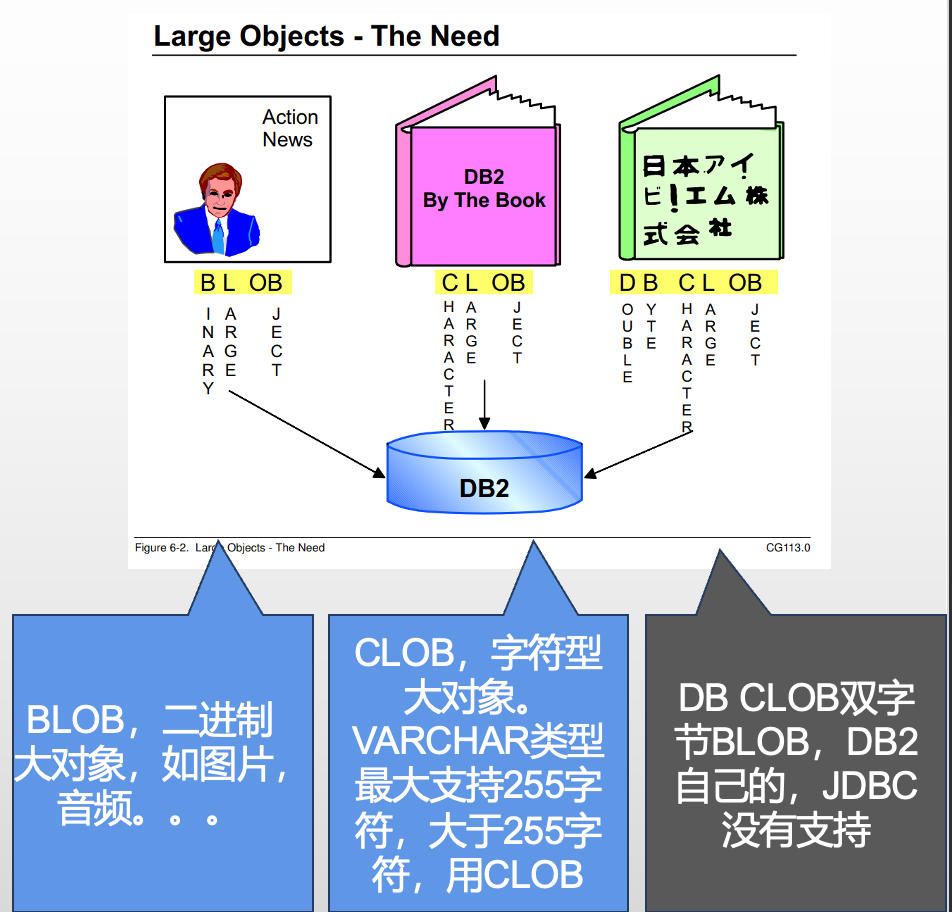
CLOB SQL实例
-- 定义一个包含CLOB的表
CREATE TABLE example_table (
id INT NOT NULL,
description CLOB(1M), -- 最大存储 1MB 的文本
PRIMARY KEY (id)
);
-- 执行插入
INSERT INTO example_table (id, description)
VALUES (1, 'This is a large text stored as CLOB.');
-- 查询, 提取前100字符
SELECT SUBSTR(description, 1, 100) AS snippet FROM example_table WHERE id = 1;JDBC实例
String resume = null; // 用于存储简历内容
String empnum = "000130"; // 员工编号
int startper, startper1, startdpt = 0; // 用于存储起始位置等信息的变量
PreparedStatement stmt1, stmt2, stmt3 = null;
String sql1, sql2, sql3 = null; // SQL 查询语句
String empno, resumefmt = null; // 员工编号和简历格式
Clob resumelob = null; // 用于存储 CLOB 对象
ResultSet rs1, rs2, rs3 = null; // 结果集对象
// 定义 SQL 查询语句,用于查找 "Personal" 在简历中的起始字节位置
sql1 = "SELECT POSSTR(RESUME,'Personal') " // 查找 "Personal" 字符串的起始位置
+ "FROM EMP_RESUME " // 从 EMP_RESUME 表中查询
+ "WHERE EMPNO = ? AND RESUME_FORMAT = 'ascii' "; // 条件:指定员工编号和简历格式
stmt1 = con.prepareStatement(sql1);
stmt1.setString(1, empnum); // 将第一个参数设置为员工编号 empnum
rs1 = stmt1.executeQuery(); // 执行查询并返回结果集
while (rs1.next()) {
// 获取查询结果的第一列值,即 "Personal" 的起始字节位置
startper = rs1.getInt(1); // 将起始位置值赋给 startper
} 这里面的SQL单拿出来讲一下
SELECT POSSTR(RESUME, 'Personal')
FROM EMP_RESUME
WHERE EMPNO = ? AND RESUME_FORMAT = 'ascii';POSSTR 函数:
用于查找一个字符串在另一个字符串中的位置
返回值:字符串的起始位置(以字节为单位,起始位置从 1`开始). 如果字符串不存在,则返回 0
- 第一个参数:
RESUME列(CLOB 类型),即存储简历数据的列 - 第二个参数:目标字符串
'Personal',需要在RESUME列中查找的子串
CLOB简历大题

这题出太复杂了, 下面代码不是按照题干做的
// 1. 接收用户输入的员工编号
System.out.print("请输入员工编号:");
String empno = scanner.nextLine();
// 2. 查询简历中 "Personal" 关键词的位置
String sql1 = "SELECT POSSTR(resume, 'Personal') FROM emp_resume WHERE empno = ?";
PreparedStatement pstmt1 = con.prepareStatement(sql1);
pstmt1.setString(1, empno);
ResultSet rs1 = pstmt1.executeQuery();
int startPersonal = -1;
if (rs1.next()) {
startPersonal = rs1.getInt(1); // 获取 "Personal" 关键词的位置
}
// 3. 查询简历中 "Department" 关键词的位置
String sql2 = "SELECT POSSTR(resume, 'Department') FROM emp_resume WHERE empno = ?";
PreparedStatement pstmt2 = con.prepareStatement(sql2);
pstmt2.setString(1, empno);
ResultSet rs2 = pstmt2.executeQuery();
int startDepartment = -1;
if (rs2.next()) {
startDepartment = rs2.getInt(1); // 获取 "Department" 关键词的位置
}
// 4. 计算 "Personal" 前的内容范围
int startPersonalAdjusted = startPersonal - 1;
// 5. 拼接简历中 "Personal" 前的内容和 "Department" 后的内容
String sql3 = "SELECT SUBSTR(resume, 1, ?) || SUBSTR(resume, ?) FROM emp_resume WHERE empno = ?";
PreparedStatement pstmt3 = con.prepareStatement(sql3);
pstmt3.setInt(1, startPersonalAdjusted); // 截取从开始到 "Personal" 前的内容
pstmt3.setInt(2, startDepartment); // 从 "Department" 开始截取
pstmt3.setString(3, empno); // 设置员工编号
ResultSet rs3 = pstmt3.executeQuery();
// 6. 输出处理后的简历
if (rs3.next()) {
Clob clob = rs3.getClob(1); // 获取 CLOB 对象
String resume = clob.getSubString(1, (int) clob.length()); // 转为字符串
System.out.println("处理后的简历内容:");
System.out.println(resume);
}
CLOB大题总体思路就这样
- 先用
POSSTR查关键词下标, 一次只能查一个 - 再用
SUBSTR查子串, 这时候用||随便拼
插入图片
完整的过程, 使用了try的自动资源管理
// 图片文件路径
String imagePath = "e:\\photo\\a.jpg";
// SQL 插入语句: 表student的photo列, 而且必须是一组(?)
String sql = "INSERT INTO student (photo) VALUES (?)";
try (
// 创建数据库连接
Connection connection = DriverManager.getConnection(url, user, password);
// 创建 PreparedStatement
PreparedStatement statement = connection.prepareStatement(sql);
// 创建文件输入流读取图片
FileInputStream inputStream = new FileInputStream(new File(imagePath))
) {
// 设置 BLOB 参数
statement.setBlob(1, inputStream);
// 执行插入操作
int rowsInserted = statement.executeUpdate();
if (rowsInserted > 0) {
System.out.println("图片已成功插入到数据库!");
} else {
System.out.println("插入图片失败!");
}
} catch (Exception e) {
e.printStackTrace();
}精简部分
// 创建 PreparedStatement 对象,用于执行 SQL 语句
// 这里实际上是插入了一行
PreparedStatement preparedStatement = conn.prepareStatement(
"INSERT INTO emp_photo VALUES ('000130', 'jpeg', ?)"
);
// 创建文件对象,参数是本地图片的路径名
File file = new File("e:\\folder\\a123.jpg");
// 创建 BufferedInputStream 对象,用于读取文件数据
BufferedInputStream imageInput = new BufferedInputStream(
new FileInputStream(file)
);
// 设置参数:
// 第1个参数是占位符索引(?的位置),
// 第2个参数是 InputStream 对象,
// 第3个参数是文件的字节长度(需要强制转换为int)
preparedStatement.setBinaryStream(1, imageInput, (int) file.length());
// 执行 SQL 语句,将数据插入数据库
preparedStatement.executeUpdate();GUI
说是不考, 但是往年也有涉及到的, 就一点点, 问个简单用法之类的, 重点还是上面
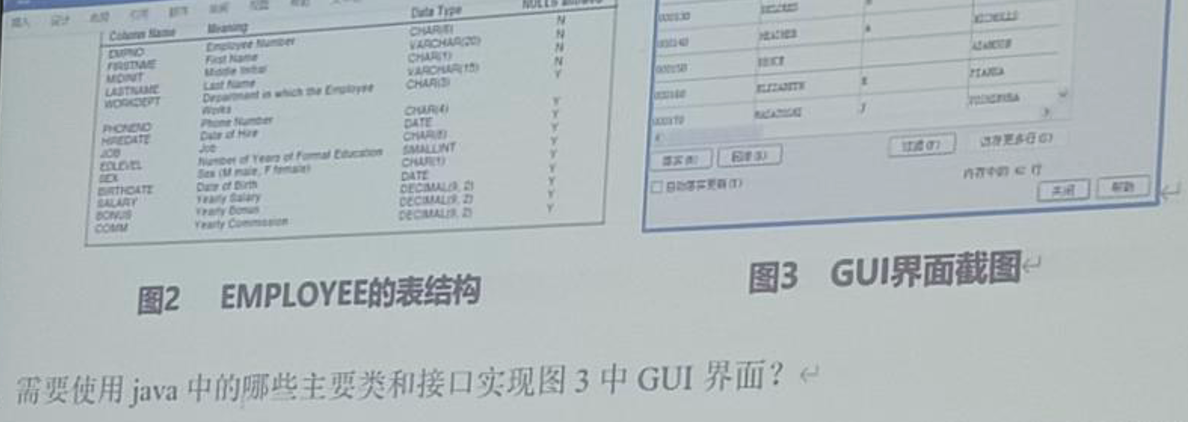
常见 Swing 组件
以下是 Swing 中一些常用组件及其功能:
-
JFrame:表示一个窗口,通常作为应用程序的主窗口
-
JPanel:用于组织组件的容器
-
JLabel:显示文本或图像的标签
-
JButton:按钮组件,用于触发操作
-
JTextField:单行文本输入框
-
JTable:表格组件