
这一节的标题叫“机器学习诊断”, 感觉很抽象, 实际上是指分析并解决在实际运用机器学习算法的过程中出现的问题, 并尽可能的避免无谓的时间浪费——原课程这一章叫“决定下一步做什么”, 感觉还不如我这标题
引入
在实施机器学习算法的过程中, 不可能是一帆风顺的, 我们会遇到各种各样的问题, 导致算法做出的预测与实际值偏差过大, 此时我们有很多可以做的事情
- 尝试减少特征数量
- 尝试增加特征数量
- 尝试增加多项式特征(特征相乘, 高次特征等)
- 尝试减少正则化系数lambda
- 尝试增大正则化系数lambda
我们不应该凭感觉随机选择上面的一种或几种方法来实施, 这会耗费多达数个月的时间, 还有可能没什么用, 本节要介绍的“机器学习诊断法”, 便是解决这些问题: 我们需要深入了解一个算法是否有效, 如果存在不足, 不足在哪里, 又该如何改进? 机器学习诊断同样可能会花费很多时间, 但是和随机选择上述的方法解决问题的话费比起来微不足道——他会告诉你应该用上述的哪种方法, 并且告诉你为什么
训练集与测试集
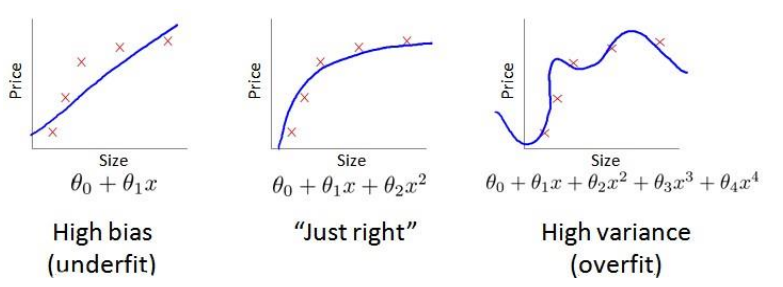
我们已经知道, 在实施算法的过程中, 我们通过优化算法使得代价函数J最小——但是代价函数最小并不一定代表着模型的泛化能力最好, 考虑过拟合的情况
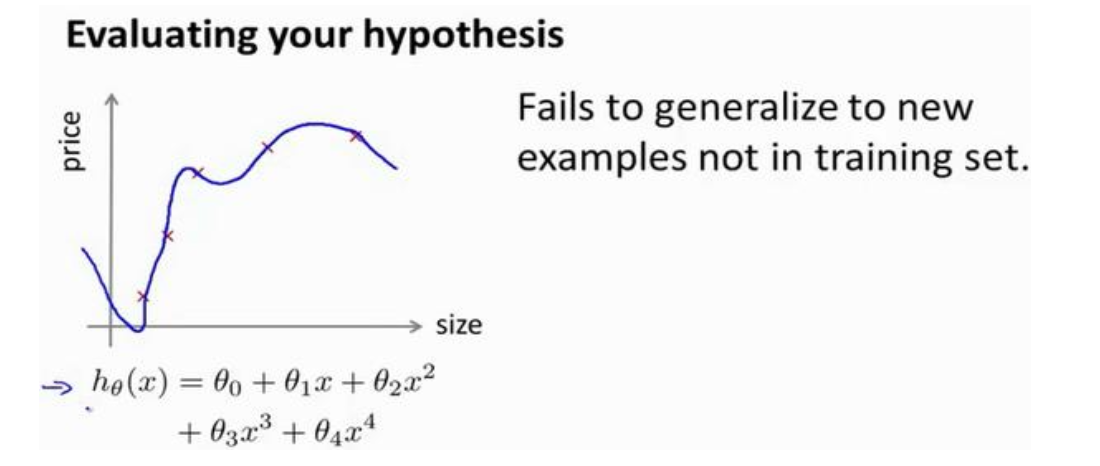
上图的过拟合情况显然只适用于训练集, 泛化能力很差, 如果是图里的线性拟合, 我们还可以通过观察函数图像来获得信息, 在实际问题中, 通常会有非常大量的特征, 而我们没法画出高维函数图像, 自然也无法观察判断过拟合与否
此时我们可以将数据分为训练集(Train set)和测试集(Test set), 来解决这个问题——训练集的数据只用来训练模型, 然后用测试集的数据对模型评估.
需要注意的是, 训练集和测试集必须是完全随机的, 在分割前最好将整个数据集打乱一下, 一般来说两者之比是7:3

我们之前学过的两种代价函数, 线性回归和逻辑回归的, 现在只需要将其套用在测试集上, 就可以计算更加准确的损失值
对于逻辑回归, 除了可以用原先的代价函数之外 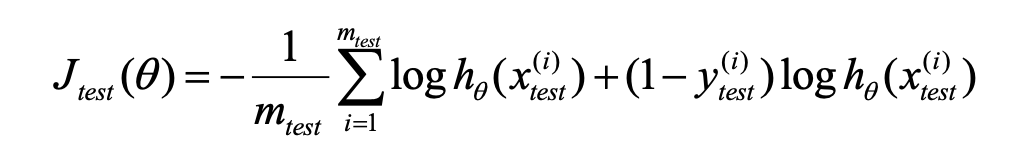
还可以用失误分类代价函数
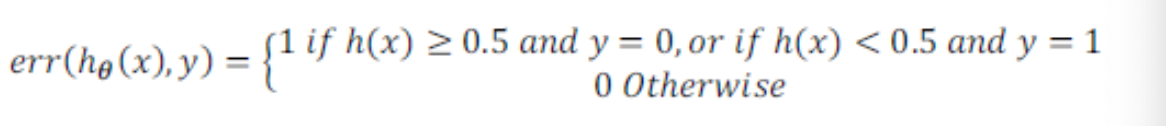
然后对结果取平均
模型选择与交叉验证
在上面的线性回归问题中, 假设我们有如下的一些模型可供选择:
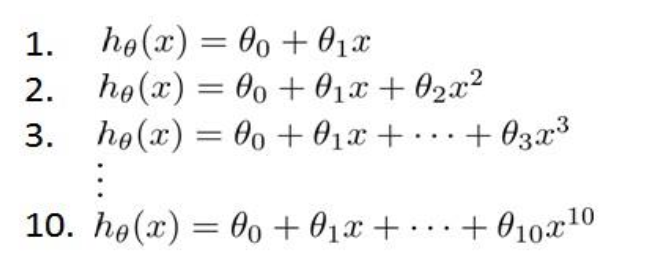
实际上就是选择x的幂次b, 注意这个字母, 等下会用到
一个很普通的想法是对于上面的10个模型, 分别对测试集最小化代价函数, 选择最小的一个, 这个做法有一个问题: 如果以此选择, 相当于我们用测试集拟合了参数b(上面提到的),这样以来, 参数b的可信度便不是很高——他只能对测试集负责
一个更好的做法是我们将全部数据集分成三份, 分别是训练集, 验证集, 测试集, 比例一般是6:2:2, 然后如此做:
- 使用训练集训练出10个模型
- 对这10个模型分别对交叉验证集求出损失值
- 选取最小损失值的模型
- 合并训练集和验证集, 作为一个整体训练新的模型参数
- 用最终模型对测试集求出推广误差(代价函数值)

在上述交叉验证的步骤中, 可能存在这样的问题: 因为样本量不够, 导致选择不同的验证集所带来的损失函数值相差很大, 导致我们不确定应该选择哪个模型
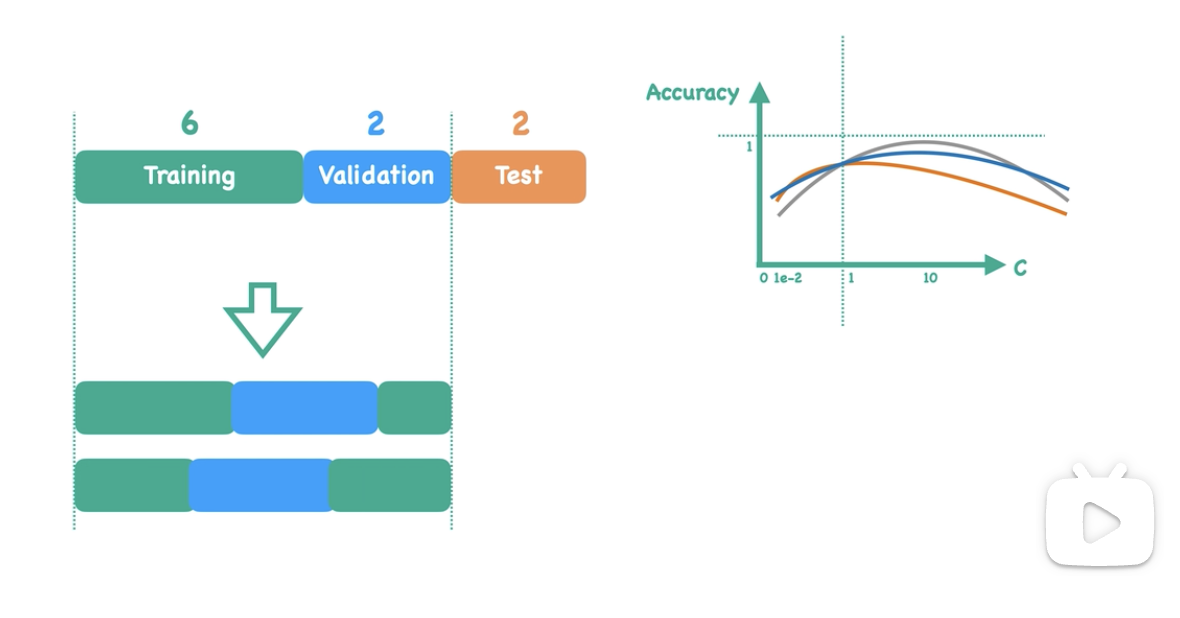
此时我们通常使用K折交叉验证(K-fold cross validation): 我们希望除过测试集的每组数据, 都最少做过一次测试集和验证集, 如图所示, 我们分别取四次验证集, 并将余下的部分作为训练集, 保证每次验证集不重不漏的覆盖, 最后对总体损失取平均值, 这就是4折交叉验证
当我们只取一个数据作为验证集时, 就叫留一交叉验证(Leave-one-out cross validation)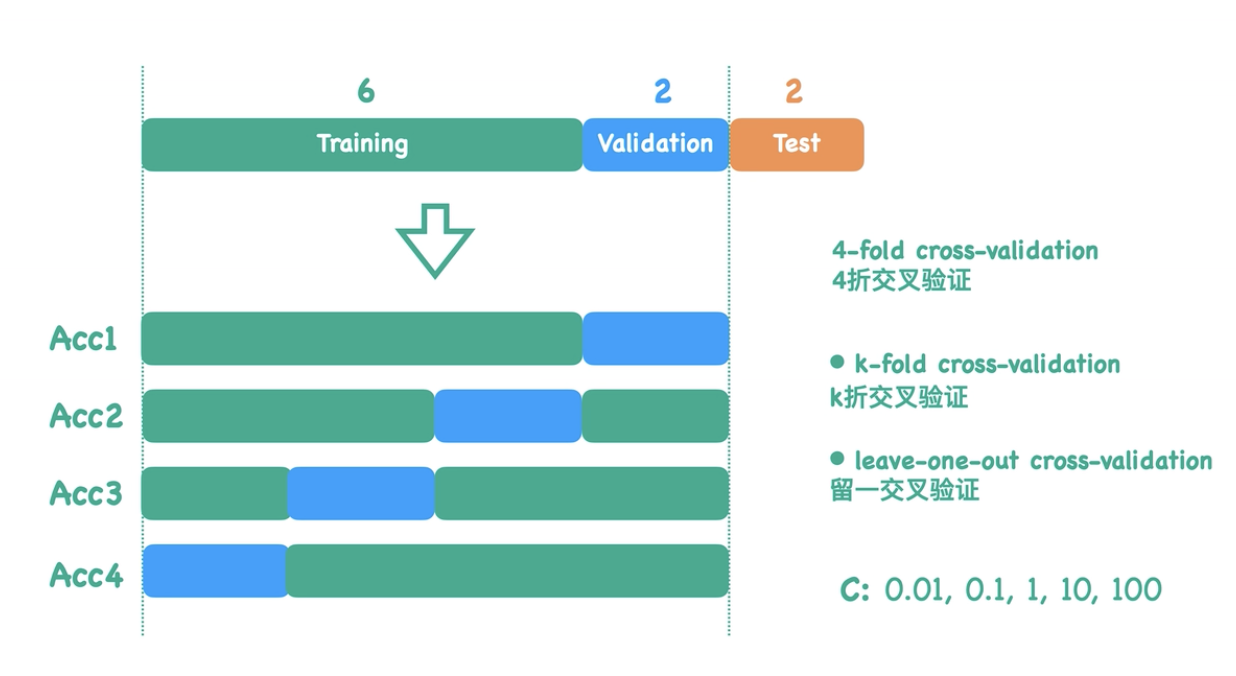
诊断偏差与方差
如果一个算法的表现不理想, 多半是出现了以下两种情况之一:偏差过大(欠拟合),或者方差过大(过拟合)
我们通常会通过将训练集和交叉验证集的代价函数误差与多项式的次数绘制在同一张图表上来帮助分析
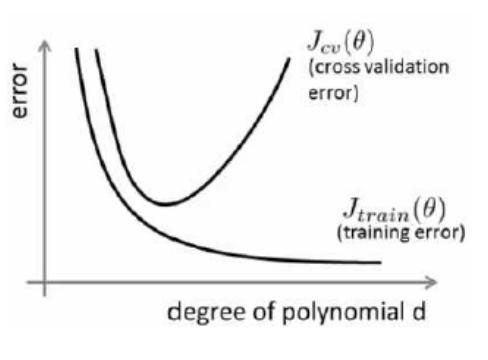
对于训练集,随着多项式次数的增加,拟合效果会越来会好,但是对于验证集,过度的拟合会带来过拟合,使得损失重新上升

从上图可以看到,前半段是欠拟合问题,后半段是过拟合问题
- 训练集误差和交叉验证集误差近似时:偏差/欠拟合
- 交叉验证集误差远大于训练集误差时:方差/过拟合
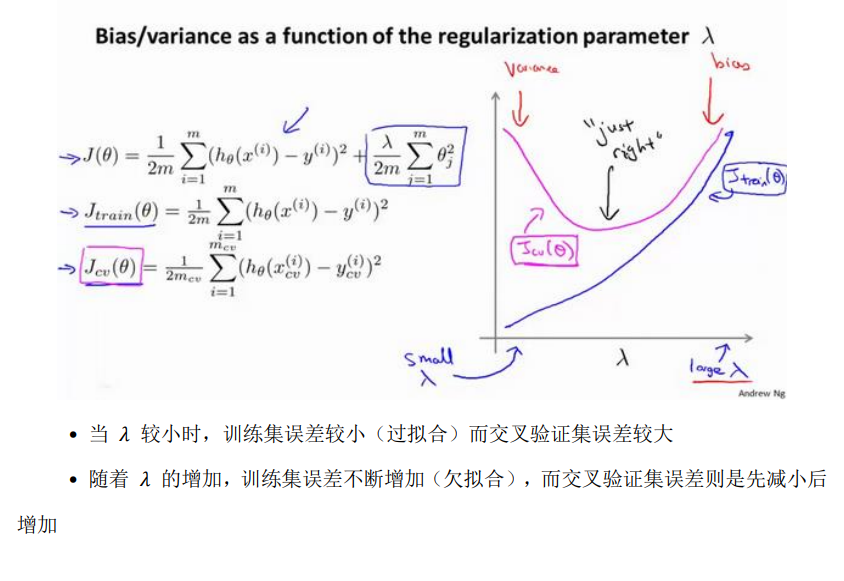
正则化与偏差/方差
正则化也会影响偏差与方差,看一下图:
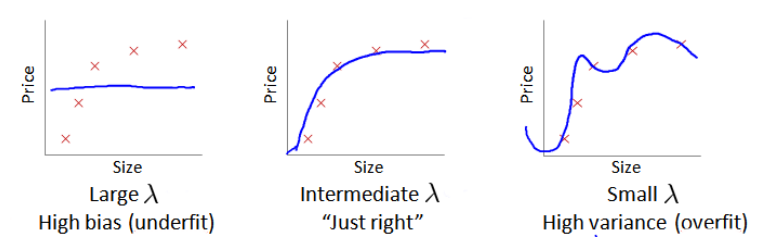
如果惩罚力度过大, 就会像左图那样, 令所有参数都趋近于零, 而过小又起不到作用,如右图那样过拟合
通常可以这样选择正则化系数: 准备一系列备选的系数,可以已2倍关系递增,比如(0, 0.01, 0.02, 0.04, …, 10 共12个). 我们同样的, 把数据分为训练集, 交叉验证集和测试集

- 使用12个不同的训练集分别训练出12个不同程度正则化的模型
- 用12个模型分别对交叉验证集计算交叉验证误差
- 选择交叉验证误差最小的模型(正则化参数)
- 用选出的模型对测试机计算推广误差
学习曲线
学习曲线是将训练集误差和交叉验证集误差作为训练集实例数量(m)的函数绘制的
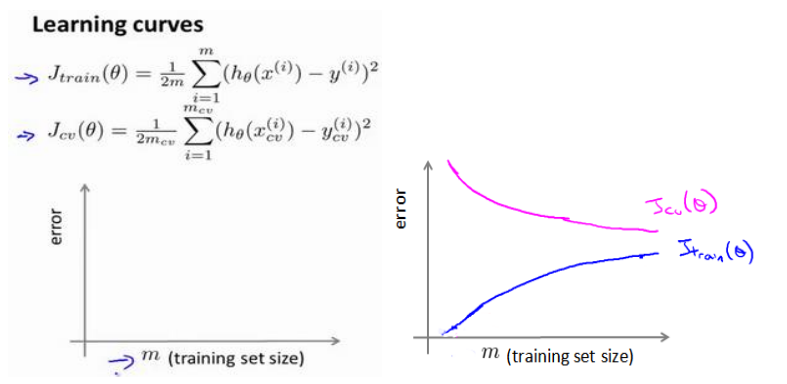
横轴的训练集大小, 是在已有基础上扩大的结果, 在计算误差时, 也只考虑选择的部分数据, 而不考虑全体数据
来看一个欠拟合的例子, 我们试图用一条直线去拟合图中数据, 可以看到无论如何调整参数, 都不能很好的预测
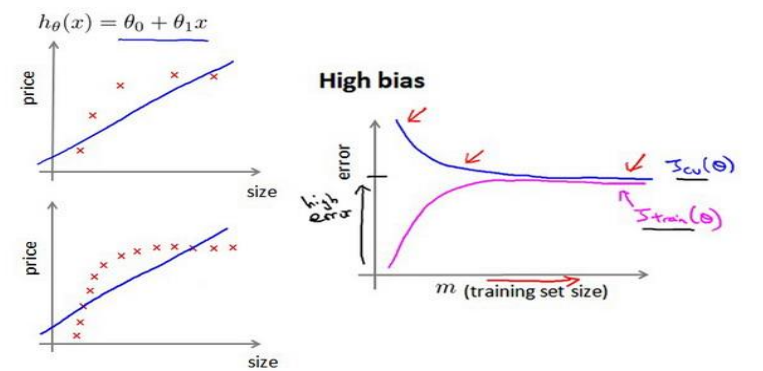 欠拟合的一个显著特征便是测试集和验证集的误差都很高, 并且两者趋近相等
欠拟合的一个显著特征便是测试集和验证集的误差都很高, 并且两者趋近相等
此时增加训练数据量不会有帮助
再看看过拟合的情况
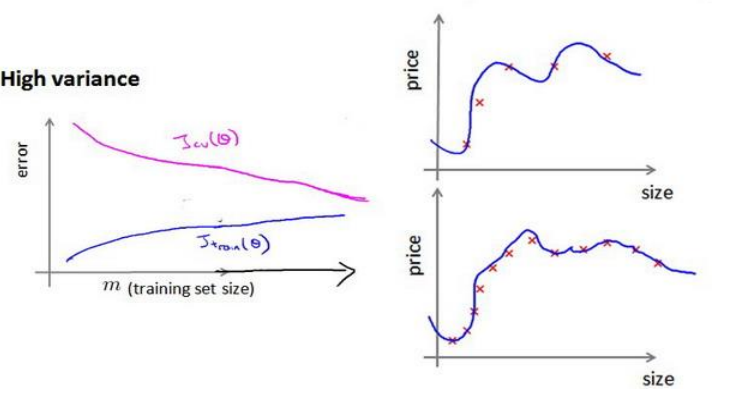
在过拟合时, 一个显著特征是训练误差与验证误差的距离
此时当交叉验证误差远大于训练误差时候, 增加数据量是有效果的
总结
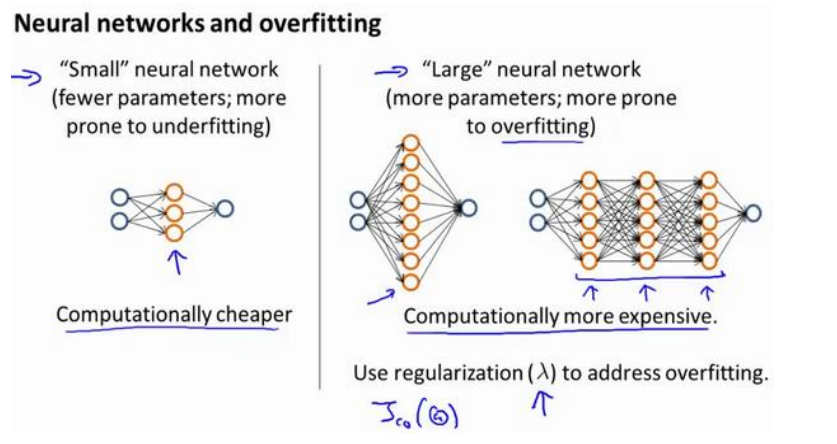
在神经网络中, 小型的神经网络参数较少, 容易导致高偏差, 但是也比较节省算力. 复杂的网络参数较多, 容易导致高方差和过拟合, 且耗费算力
通常选择较大的神经网络并采用正则化处理会比采用较小的神经网络效果要好